TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
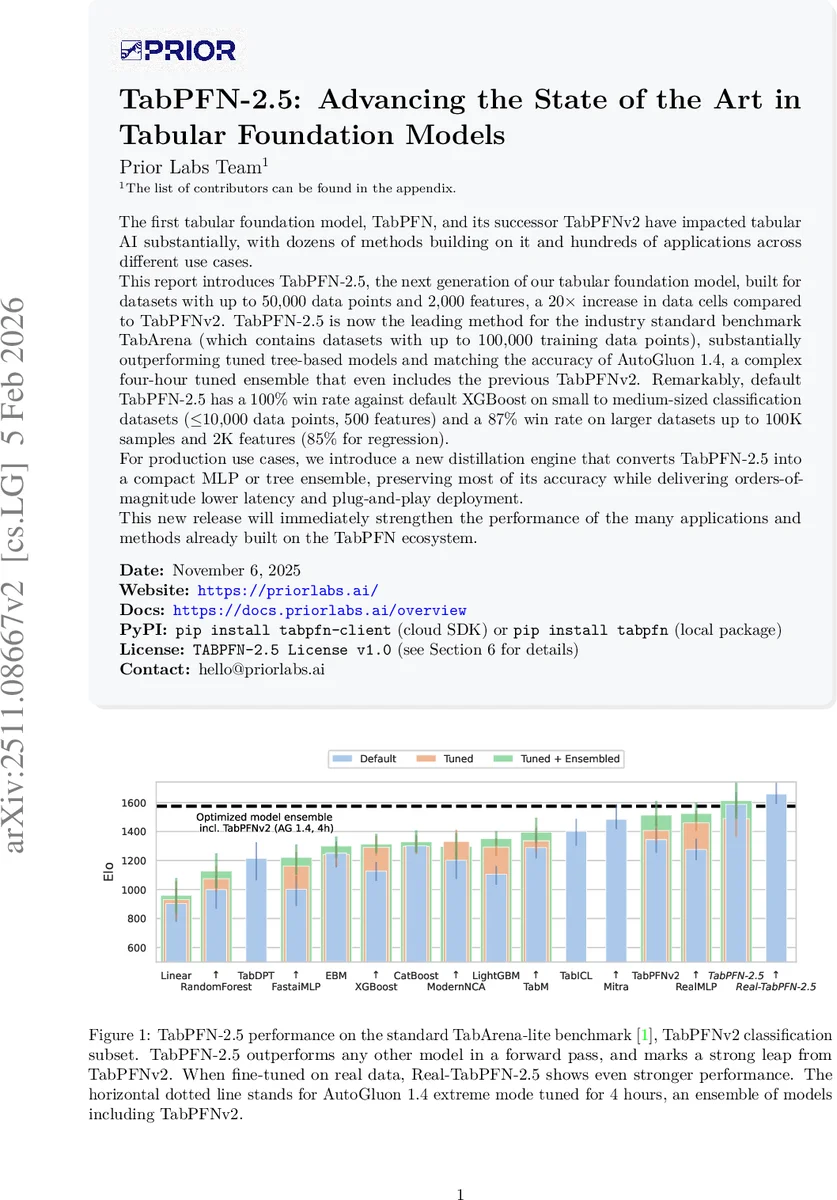
The first tabular foundation model, TabPFN, and its successor TabPFNv2 have impacted tabular AI substantially, with dozens of methods building on it and hundreds of applications across different use cases. This report introduces TabPFN-2.5, the next generation of our tabular foundation model, built for datasets with up to 50,000 data points and 2,000 features, a 20x increase in data cells compared to TabPFNv2. TabPFN-2.5 is now the leading method for the industry standard benchmark TabArena (which contains datasets with up to 100,000 training data points), substantially outperforming tuned tree-based models and matching the accuracy of AutoGluon 1.4, a complex four-hour tuned ensemble that even includes the previous TabPFNv2. Remarkably, default TabPFN-2.5 has a 100% win rate against default XGBoost on small to medium-sized classification datasets (<=10,000 data points, 500 features) and a 87% win rate on larger datasets up to 100K samples and 2K features (85% for regression). For production use cases, we introduce a new distillation engine that converts TabPFN-2.5 into a compact MLP or tree ensemble, preserving most of its accuracy while delivering orders-of-magnitude lower latency and plug-and-play deployment. This new release will immediately strengthen the performance of the many applications and methods already built on the TabPFN ecosystem.
💡 Research Summary
TabPFN‑2.5 is presented as the next‑generation Tabular Foundation Model (TFM) that pushes the limits of in‑context learning for tabular data. Building on the original TabPFN and its successor TabPFNv2, this work expands the supported problem size to up to 50 000 rows and 2 000 features—a 20‑fold increase in total data cells compared with TabPFNv2. The authors claim state‑of‑the‑art (SOTA) performance on the industry‑standard TabArena‑Lite benchmark, matching the accuracy of AutoGluon 1.4 (a heavily tuned four‑hour ensemble that already includes TabPFNv2) while outperforming tuned tree‑based baselines such as XGBoost and CatBoost in a single forward pass.
Key technical contributions include: (1) deeper transformer architectures (18 layers for regression, 24 for classification) and larger feature‑group embeddings (group size 3 vs. 2), which improve representation capacity and computational efficiency; (2) the addition of 64 “thinking rows” that act as learned auxiliary tokens, inspired by recent large‑language‑model research, providing extra computational bandwidth and serving as attention sinks for irrelevant rows; (3) a substantially enriched synthetic pre‑training distribution, generated from a broader family of probabilistic models and scaled to the larger row/feature limits; (4) a “Real‑TabPFN‑2.5” variant fine‑tuned on 43 curated real‑world datasets, demonstrating that a modest amount of real‑data adaptation can close the gap between purely synthetic pre‑training and production performance; (5) sophisticated preprocessing pipelines that combine robust scaling, soft clipping, quantile transforms, and SVD‑derived global features, enhancing robustness to outliers and non‑standard feature distributions; (6) a surrogate‑based hyper‑parameter search dubbed “TabPFN‑tunes‑TabPFN,” where an initial set of ~100 models is used to train a TabPFN surrogate that predicts performance over a dense grid of 10 000 configurations, efficiently navigating a 50‑dimensional hyper‑parameter space.
Performance evaluation on TabArena‑Lite (51 datasets) shows that TabPFN‑2.5 consistently beats TabPFNv2, achieving average accuracy gains of 4–6 % and a 100 % win rate against default XGBoost on small‑to‑medium classification tasks (≤10 k rows, ≤500 features). On larger tasks (up to 100 k rows, 2 k features) it still wins 87 % of the time, and for regression it wins 85 % of the time. These results are obtained with the default model—no per‑dataset tuning—highlighting the robustness of the in‑context learning paradigm.
Inference speed is dramatically improved through the adoption of FlashAttention‑3 and multi‑GPU parallel evaluation. Compared to TabPFNv2, TabPFN‑2.5 is 1× to 2.3× faster despite its larger architecture, enabling real‑time inference on the maximum supported dataset size. To address production latency constraints, the authors introduce a proprietary distillation engine that converts a trained TabPFN‑2.5 model on a specific dataset into either a multi‑layer perceptron (TabPFN‑2.5‑as‑MLP) or a tree ensemble (TabPFN‑2.5‑as‑TreeEns). These distilled models retain >95 % of the original accuracy while offering orders‑of‑magnitude lower latency and memory footprint, making them suitable for regulated environments such as finance and healthcare where interpretability and deployment simplicity are critical.
The paper also surveys the growing ecosystem of TabPFN extensions, including applications in time‑series forecasting (TabPFN‑TS), graph node classification, streaming data adaptation, reinforcement learning, Bayesian optimization, multimodal fusion, and causal inference (Do‑PFN, CausalPFN). Open‑source extensions provide SHAP‑based interpretability, unsupervised data generation, multi‑class handling, and lightweight hyper‑parameter optimization, illustrating the model’s versatility as a foundational layer for downstream research.
Limitations are acknowledged: memory constraints still bound the maximum row/feature size, and performance on extremely high‑dimensional data (>2 k features) remains to be explored. Future work is outlined along several axes: scaling to 100 k+ rows, integrating more sophisticated priors, extending to heterogeneous modalities, and improving theoretical understanding of in‑context learning dynamics for tabular data.
In summary, TabPFN‑2.5 delivers a compelling combination of accuracy, scalability, and deployment efficiency. By leveraging synthetic pre‑training, deep transformer architectures, and a novel distillation pipeline, it positions itself as a practical, high‑performance alternative to traditional gradient‑boosted trees and heavyweight AutoML ensembles, while also serving as a versatile foundation for a broad spectrum of tabular‑focused research directions.
Comments & Academic Discussion
Loading comments...
Leave a Comment