Group-Adaptive Adversarial Learning for Robust Fake News Detection Against Malicious Comments
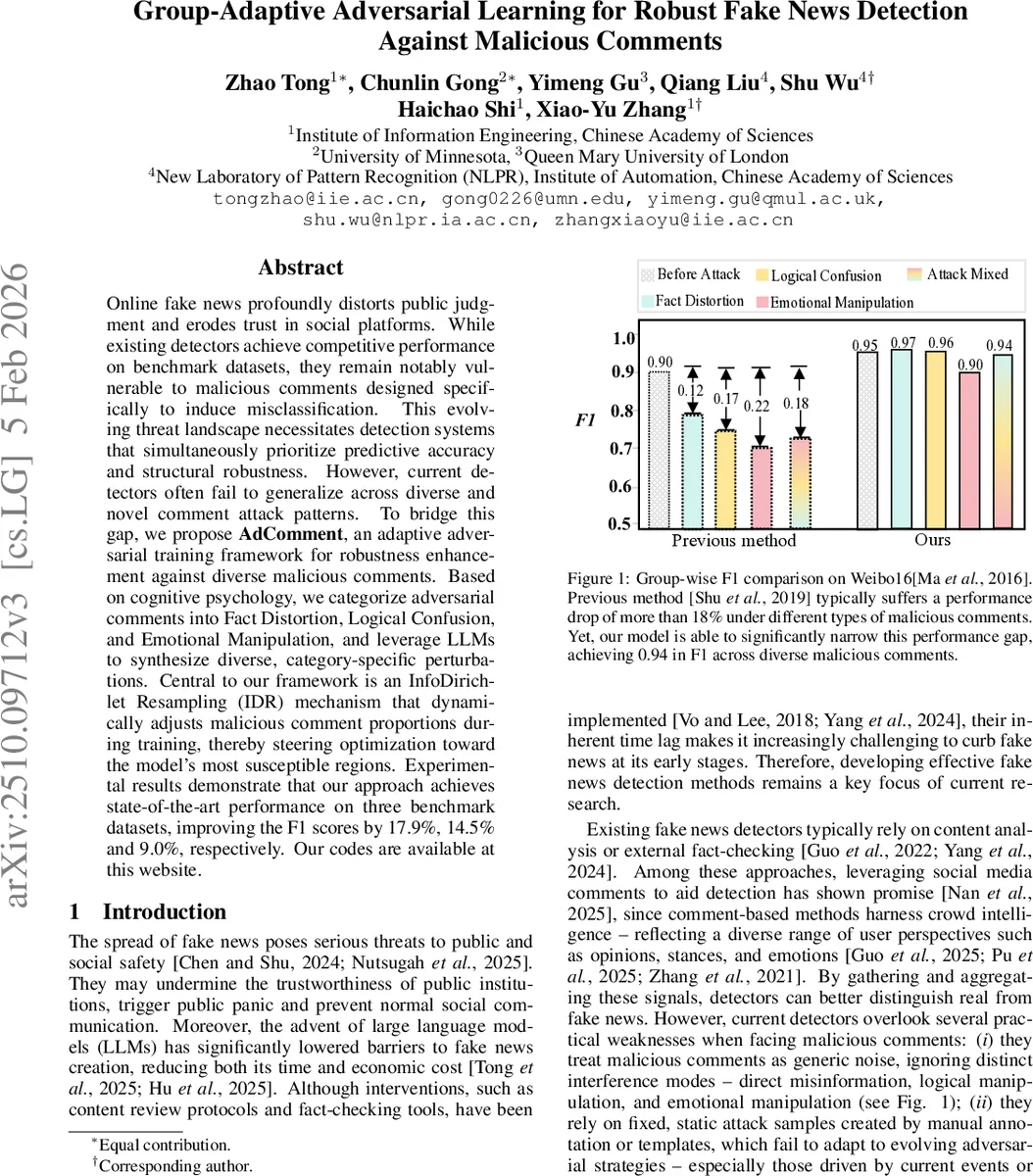
Online fake news profoundly distorts public judgment and erodes trust in social platforms. While existing detectors achieve competitive performance on benchmark datasets, they remain notably vulnerable to malicious comments designed specifically to induce misclassification. This evolving threat landscape necessitates detection systems that simultaneously prioritize predictive accuracy and structural robustness. However, current detectors often fail to generalize across diverse and novel comment attack patterns. To bridge this gap, we propose AdComment, an adaptive adversarial training framework for robustness enhancement against diverse malicious comments. Based on cognitive psychology, we categorize adversarial comments into Fact Distortion, Logical Confusion, and Emotional Manipulation, and leverage LLMs to synthesize diverse, category-specific perturbations. Central to our framework is an InfoDirichlet Resampling (IDR) mechanism that dynamically adjusts malicious comment proportions during training, thereby steering optimization toward the model’s most susceptible regions. Experimental results demonstrate that our approach achieves state-of-the-art performance on three benchmark datasets, improving the F1 scores by 17.9%, 14.5% and 9.0%, respectively.
💡 Research Summary
The paper tackles a critical vulnerability of comment‑based fake‑news detectors: malicious comments can deliberately mislead the model and cause severe performance drops. To address this, the authors introduce AdComment, a group‑adaptive adversarial learning framework that (1) categorizes malicious comments into three psychologically motivated attack mechanisms—Fact Distortion, Logical Confusion, and Emotional Manipulation; (2) synthesizes diverse, category‑specific attack comments using large language models (LLMs) through a two‑step “understand‑then‑generate” chain‑of‑thought prompting strategy; and (3) dynamically adjusts the proportion of each comment group during training via an InfoDirichlet Resampling (IDR) mechanism.
Comment Generation. The authors employ three distinct LLMs (Mistral‑7B, Gemma‑2B, Qwen‑32B) to mitigate style bias. For each news article, a prompt first extracts key factual points and a target misleading direction, then instructs the model to produce a comment that follows the chosen attack type while maintaining a natural user tone. This process yields a large synthetic dataset annotated with the attack mechanism, covering variations in slang, sarcasm, and platform‑specific norms.
Group‑Adaptive Training. At the start of training, comment groups are uniformly sampled. After each epoch, the model is evaluated on three group‑specific validation sets, producing vulnerability scores (v_j = 1 - \text{accuracy}_j) for (j \in {F, L, E}). These scores are fed into a Dirichlet distribution with parameters (\alpha_j = 1 + v_j); the expected values (E
Comments & Academic Discussion
Loading comments...
Leave a Comment