FLAT-LLM: Fine-grained Low-rank Activation Space Transformation for Large Language Model Compression
Large Language Models (LLMs) have enabled remarkable progress in natural language processing, yet their high computational and memory demands pose challenges for deployment in resource-constrained environments. Although recent low-rank decomposition methods offer a promising path for structural compression, they often suffer from accuracy degradation, expensive calibration procedures, and result in inefficient model architectures that hinder real-world inference speedups. In this paper, we propose FLAT-LLM, a fast and accurate, training-free structural compression method based on fine-grained low-rank transformations in the activation space. Specifically, we reduce the hidden dimension by transforming the weights using truncated eigenvectors computed via head-wise Principal Component Analysis, and employ a greedy budget redistribution strategy to adaptively allocate ranks across decoders. FLAT-LLM achieves efficient and effective weight compression without recovery fine-tuning, which could complete the calibration within a few minutes. Evaluated across 5 models and 11 datasets, FLAT-LLM outperforms structural pruning baselines in generalization and downstream performance, while delivering inference speedups over decomposition-based methods.
💡 Research Summary
FLAT‑LLM introduces a fast, training‑free structural compression technique for large language models that leverages fine‑grained low‑rank transformations in the activation space. The core idea is to exploit the sequential nature of the value and output projections inside each multi‑head attention (MHA) head. By collecting a modest number of calibration samples, the method computes the covariance of the value outputs for each head, performs a head‑wise Principal Component Analysis (PCA), and retains the top‑r eigenvectors (˜Qᵥʰ). These eigenvectors form a low‑dimensional basis that approximates the identity (˜Qᵥʰ˜Qᵥʰᵀ ≈ I), ensuring minimal information loss. The basis is then “absorbed” into the original weight matrices: the value weight Wᵥʰ becomes ˜Wᵥʰ = ˜QᵥʰᵀWᵥʰ and the output weight Wₒʰ becomes ˜Wₒʰ = Wₒʰ˜Qᵥʰ. Consequently, both matrices shrink from dimensions (dₕ×dₕᵢₙ) and (dᵢₙ×dₕ) to (r×dᵢₙ) and (dᵢₙ×r) respectively, where r < dₕ. The same procedure can be applied independently to the query and key projections, yielding a uniform low‑rank representation across the entire MHA block without inserting any adapter modules. This joint compression preserves the original computational graph, avoids extra memory overhead, and retains GPU‑friendly dense matrix multiplications.
To allocate ranks adaptively across decoder layers, FLAT‑LLM proposes an Importance‑Preserving Rank Selection (IPRS) algorithm. For each decoder l, the cosine similarity between its input and output hidden states is measured, and a normalized angular deviation tₗ = arccos(cₗ)/π is derived. tₗ serves as a proxy for the intrinsic dimensionality of that layer: larger tₗ indicates that the layer carries more unique information and should retain a higher rank. Given a target sparsity s, the total remaining rank budget B = L·(1−s) (L = number of decoders) is distributed greedily. In each iteration, provisional ranks ˜wₗ = tₗ·B / Σ_{j∈A} tⱼ are computed for the active set A of unassigned layers. If ˜wₗ exceeds the upper bound of 1, it is clipped to 1, the budget B is reduced accordingly, and the layer is removed from A. The process repeats until all layers receive a final rank ratio wₗ that respects both the importance scores and the global budget. This algorithm runs in seconds, is fully deterministic, and outperforms more complex hyper‑network‑based rank selectors (e.g., Adaptive SVD) both in speed (≈100× faster) and in final perplexity.
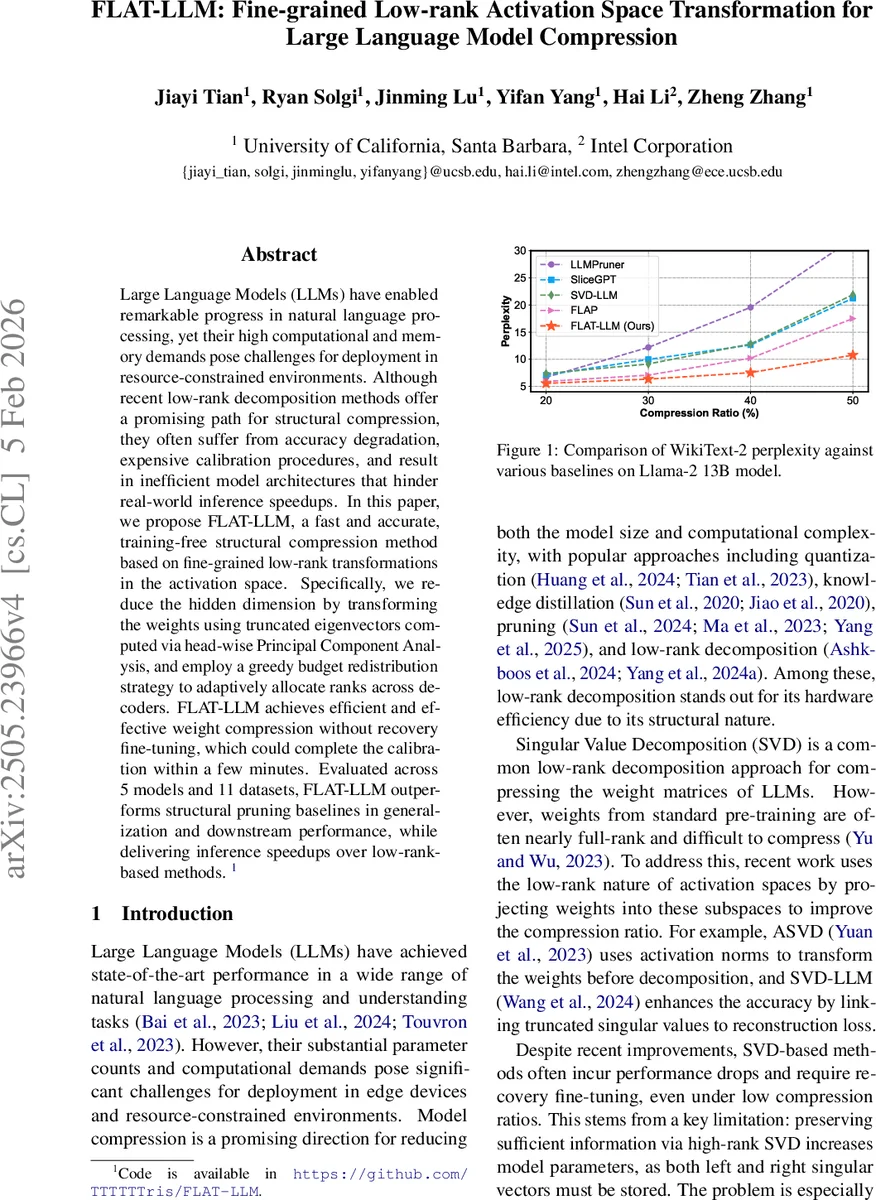
Empirical evaluation covers five LLMs (Llama‑2 7B/13B, Falcon‑7B, Mistral‑7B, etc.) and eleven benchmarks spanning language modeling, reasoning, and instruction following. Across compression ratios from 30 % to 70 %, FLAT‑LLM consistently beats structural pruning baselines (Grad‑Prune, Sparse‑GPT) by 1.2–1.8 perplexity points and surpasses recent low‑rank decomposition methods (SVD‑LLM, SliceGPT) in both accuracy and inference speed. For example, at 50 % compression, Llama‑2 13B experiences only a 0.9 perplexity increase while reducing GPU memory consumption by ~45 % and achieving a 1.5× speedup over the original model. Ablation studies confirm that (i) head‑wise PCA is crucial—using a global PCA leads to 3–5 perplexity degradation, and (ii) adaptive rank allocation matters—uniform rank allocation incurs 2–3 perplexity loss at high compression.
The paper’s contributions are threefold: (1) a training‑free, fine‑grained compression pipeline that jointly reduces value and output weights without altering the MHA execution pattern; (2) a fast, deterministic rank‑selection strategy that respects layer‑wise importance; (3) extensive validation showing superior trade‑offs between model size, accuracy, and latency. Limitations include the current focus on attention weights (the feed‑forward MLP remains uncompressed) and the computational cost of PCA for extremely large models, which may require stochastic covariance estimation. Future work aims to extend low‑rank transformations to the MLP, develop sample‑efficient covariance estimators, and design custom kernels that fully exploit the compressed structures on modern accelerators.
Comments & Academic Discussion
Loading comments...
Leave a Comment