Atomic Information Flow: A Network Flow Model for Tool Attributions in RAG Systems
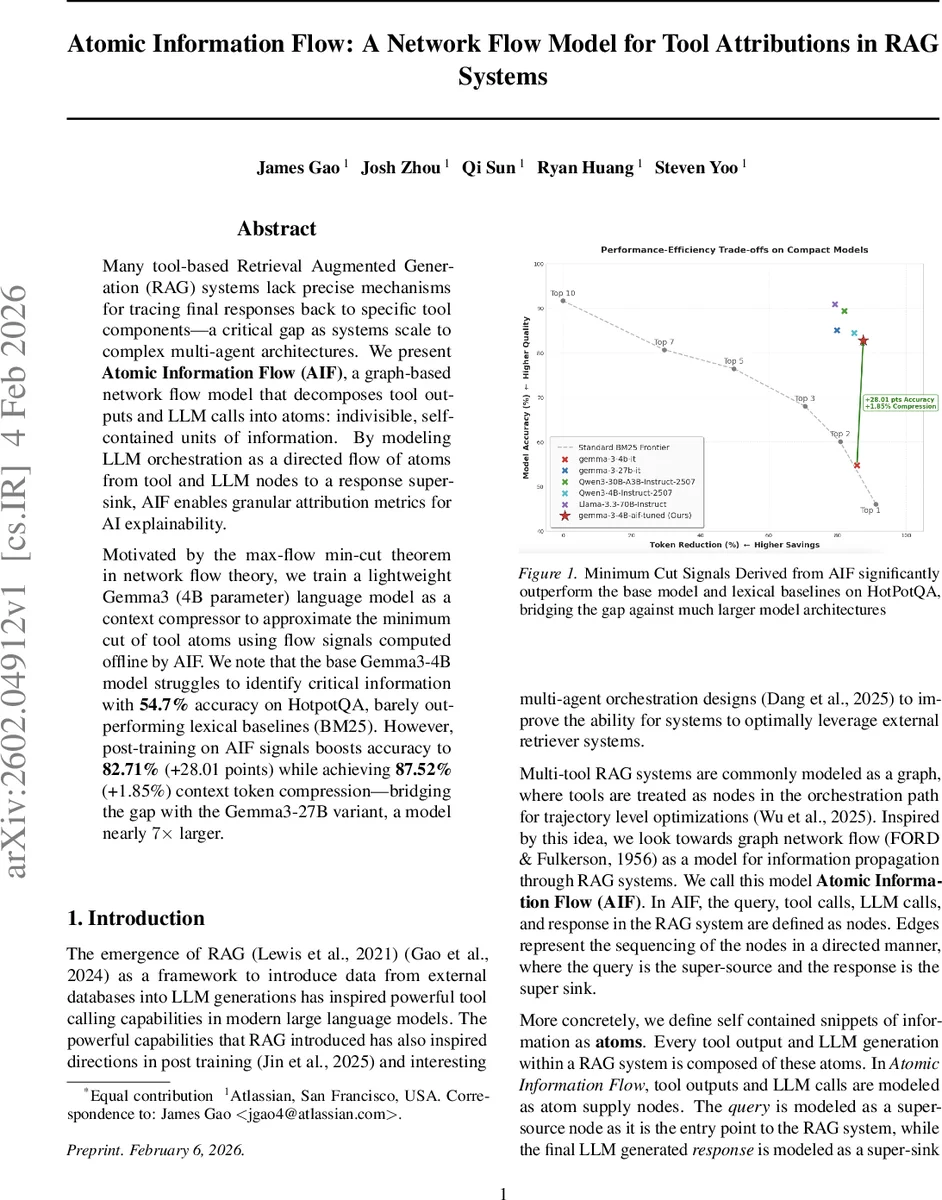
Many tool-based Retrieval Augmented Generation (RAG) systems lack precise mechanisms for tracing final responses back to specific tool components – a critical gap as systems scale to complex multi-agent architectures. We present \textbf{Atomic Information Flow (AIF)}, a graph-based network flow model that decomposes tool outputs and LLM calls into atoms: indivisible, self-contained units of information. By modeling LLM orchestration as a directed flow of atoms from tool and LLM nodes to a response super-sink, AIF enables granular attribution metrics for AI explainability. Motivated by the max-flow min-cut theorem in network flow theory, we train a lightweight Gemma3 (4B parameter) language model as a context compressor to approximate the minimum cut of tool atoms using flow signals computed offline by AIF. We note that the base Gemma3-4B model struggles to identify critical information with \textbf{54.7%} accuracy on HotpotQA, barely outperforming lexical baselines (BM25). However, post-training on AIF signals boosts accuracy to \textbf{82.71%} (+28.01 points) while achieving \textbf{87.52%} (+1.85%) context token compression – bridging the gap with the Gemma3-27B variant, a model nearly $7\times$ larger.
💡 Research Summary
The paper introduces Atomic Information Flow (AIF), a graph‑based network‑flow framework designed to provide fine‑grained attribution of tool outputs and LLM calls in Retrieval‑Augmented Generation (RAG) pipelines. Existing tool‑augmented RAG systems can involve cascades of retrievals, database queries, web searches, and intermediate LLM rewrites, making it difficult to answer questions such as “which tool contributed to a particular sentence?” or “what is the minimal set of information needed to preserve answer fidelity?”. AIF addresses these challenges by decomposing every piece of generated text—both from external tools and internal LLM calls—into indivisible units called atoms. These atoms are treated as commodities flowing through a directed graph whose nodes represent the query (super‑source), tool calls, intermediate LLM calls, and the final response (super‑sink). Edges encode causal or sequential dependencies.
Formally, each node v has a multiset Atoms(v) of atoms it produces. A supply function s(v)=|Atoms(v)| injects new atoms at tool and LLM nodes. A flow function f:E→ℕ₀ assigns a non‑negative count of atoms to each directed edge, obeying a relaxed conservation law that allows LLM nodes to discard irrelevant atoms via a slack variable δ(v). This slack quantifies the amount of information filtered out by LLM steering. Because atoms are distinct, the model corresponds to a multicommodity flow problem, which is NP‑hard. Instead of solving it exactly, the authors leverage the max‑flow/min‑cut duality: the minimum cut identifies the “information bottleneck” – the smallest set of atoms that must be retained to preserve answer quality.
To make the approach practical at inference time, they train a lightweight 4‑billion‑parameter Gemma‑3 model as a context compressor. The model is fine‑tuned on signals derived from offline AIF computations (minimum‑cut approximations). During training, a semantic relevance scorer assigns a Likert‑scale score to each atom relative to the query, providing a scalar signal that guides the flow. At inference, the trained Gemma‑3 predicts which atoms to keep, effectively approximating the optimal cut without expensive combinatorial optimization.
The pipeline consists of three stages:
- Atomic Decomposition – Tool outputs are split into atoms using a dedicated decomposer (GPT‑5‑Nano). Large outputs are handled with a map‑reduce chunking strategy.
- Atomic Signal Injection – Each atom receives a relevance score (or other metadata such as freshness or uncertainty) via a scorer S(a,q). This step demonstrates the extensibility of AIF to arbitrary weighted flow heuristics.
- Response Atom Assignment – The final LLM response is also decomposed into atoms. A global pool of all tool atoms is constructed, and a matching algorithm (also map‑reduce for scalability) assigns each response atom to one or more source atoms, yielding a multi‑hop attribution map Φ.
From these assignments, the authors define a suite of flow heuristics (Table 1) that quantify: (i) the proportion of response atoms supplied by tools (AR,T), (ii) the fraction of high‑relevance atoms contributing to the answer (RAP), (iii) tool‑specific consumption rates, and (iv) usage under relevance thresholds. These metrics enable fine‑grained analysis of why a particular answer succeeded or failed.
Empirical evaluation is performed on four multi‑context QA benchmarks that provide human‑annotated tool attributions: HotpotQA, MS MarcoV2, Musique, and Wiki‑Multihop QA. The datasets are split into “True” (answers that are correct) and “False” (incorrect) subsets. AIF’s attribution precision and recall are markedly higher on the True subsets, confirming that correct answers rely on well‑attributed tool information. Compared to the ALCE benchmark baseline, AIF achieves comparable or slightly superior attribution scores while also delivering the additional granularity unavailable to citation‑only methods.
The most striking result concerns the context compression capability. The base Gemma‑3‑4B model attains only 54.7 % accuracy on HotpotQA, barely beating a BM25 lexical baseline. After fine‑tuning on AIF‑derived minimum‑cut signals, accuracy jumps to 82.71 % (a +28.01‑point gain). Simultaneously, the model reduces the amount of context tokens it needs to retain to 87.52 % of the original (a +1.85 % improvement), effectively matching the performance of a much larger 27‑billion‑parameter Gemma‑3 model (≈7× more parameters). This demonstrates that AIF can both enhance factual correctness and compress context, offering a practical route to lightweight, high‑performing RAG systems.
In conclusion, Atomic Information Flow provides a principled, graph‑theoretic lens for tracing information provenance in tool‑augmented LLM pipelines. It enables (1) precise tool‑level attribution, (2) identification of minimal informative cuts for context compression, and (3) diagnostic insight into multi‑agent orchestration failures. The authors suggest future work to extend AIF to include retrieval‑flow edges, explore richer signal types (e.g., uncertainty quantification), and apply the framework to more complex multi‑agent environments, thereby advancing both explainability and efficiency of next‑generation RAG architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment