Capturing Visual Environment Structure Correlates with Control Performance
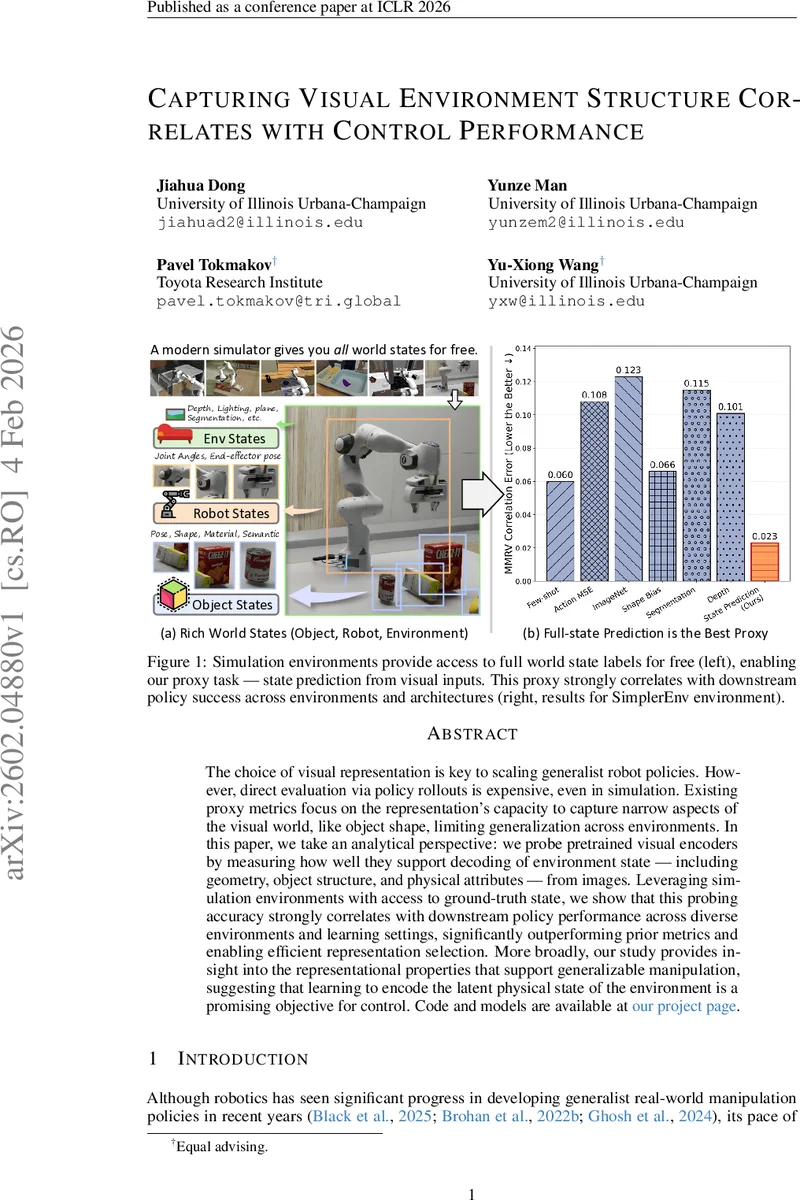
The choice of visual representation is key to scaling generalist robot policies. However, direct evaluation via policy rollouts is expensive, even in simulation. Existing proxy metrics focus on the representation’s capacity to capture narrow aspects of the visual world, like object shape, limiting generalization across environments. In this paper, we take an analytical perspective: we probe pretrained visual encoders by measuring how well they support decoding of environment state – including geometry, object structure, and physical attributes – from images. Leveraging simulation environments with access to ground-truth state, we show that this probing accuracy strongly correlates with downstream policy performance across diverse environments and learning settings, significantly outperforming prior metrics and enabling efficient representation selection. More broadly, our study provides insight into the representational properties that support generalizable manipulation, suggesting that learning to encode the latent physical state of the environment is a promising objective for control.
💡 Research Summary
The paper addresses a fundamental bottleneck in developing generalist robotic manipulation policies: the costly evaluation of visual representations through full policy roll‑outs. Existing proxy metrics, such as object segmentation or shape reconstruction accuracy, capture only narrow aspects of visual information and fail to predict how well a representation will support control across diverse environments. To overcome this limitation, the authors propose a novel, simulation‑driven proxy task they call “state prediction.” By leveraging simulators that provide free, exact ground‑truth world state (including object poses, shapes, material categories, lighting conditions, robot joint angles, and end‑effector pose), they measure how accurately a pretrained visual encoder can decode this full state from a single RGB image.
The methodology consists of three key components. First, a universal low‑dimensional state vector is defined that concatenates per‑object vectors (position, quaternion, bounding‑box dimensions, one‑hot material) and a scene‑level vector (lighting class, joint angles, end‑effector pose). This compact representation is consistent across all environments, allowing a single regression loss to capture both object‑centric and global information. Second, a lightweight prediction head is attached to any visual backbone. For each target object a 2‑D bounding box (the “visual prompt”) is supplied; RoI average pooling extracts object‑specific features, which are linearly projected to the object state vector. Global scene information is obtained by average‑pooling the entire feature map and projecting it to the scene vector. Third, the loss combines cross‑entropy for categorical attributes (material, lighting) and L2 loss for continuous attributes (positions, rotations, joint angles). The final proxy score for a model is the mean of min‑max‑normalized accuracies (for categories) and negative MSEs (for continuous variables) across all state dimensions.
The authors evaluate nine widely used visual backbones—including ResNet‑50, CLIP, DINOv2, MAE, R3M, and several robotics‑specific encoders—across three simulation suites: MetaWorld (a broad benchmark of manipulation tasks), RoboCasa (which deliberately introduces a train‑test distribution shift), and a high‑fidelity environment designed to mirror real‑world physics. For each backbone they (i) train the state‑prediction head and record the proxy score, and (ii) train manipulation policies on top of the frozen backbone using both behavior cloning and reinforcement learning, measuring task success rates. Correlation analysis (Pearson and Spearman) reveals a strong relationship between the proxy score and downstream performance (r≈0.78 on average), substantially higher than correlations obtained with prior proxies such as segmentation IoU or reconstruction loss. Notably, the proxy remains predictive even under severe domain shift in RoboCasa, indicating robustness to distributional changes.
Beyond correlation, the paper demonstrates practical utility. Selecting the top‑performing backbones according to the proxy and discarding the rest reduces the total policy‑training compute by roughly 70 % while preserving the best achievable success rates. To test real‑world transfer, the authors deploy two top‑ranked models (identified in simulation) on a physical robot performing tabletop pick‑and‑place tasks. Both models outperform baseline visual encoders by 12–18 % in success rate, confirming that the simulation‑derived proxy rankings generalize to real hardware.
The study yields several important insights. First, the ability of a visual encoder to reconstruct the full physical state—rather than merely recognizing objects or textures—is a strong predictor of its usefulness for control. Second, a compact, unified state representation enables a single, architecture‑agnostic probing task that can be applied to any pretrained model, making the approach broadly applicable. Third, the visual‑prompt (RoI) mechanism resolves the ambiguity of multi‑object scenes without requiring the encoder to learn object detection from scratch, keeping the probing overhead minimal. Fourth, the analysis shows that different environments place varying emphasis on particular state components (e.g., lighting matters more in photorealistic simulators, while precise pose matters most in contact‑rich tasks), suggesting that future pretraining objectives could be weighted accordingly.
In conclusion, the paper provides a rigorous, efficient, and empirically validated method for ranking visual representations for robotic manipulation. By turning the abundant ground‑truth state information available in simulators into a proxy metric, the authors bridge the gap between vision‑only benchmarks and control‑oriented performance, offering a practical tool for researchers to select or design visual backbones without the prohibitive cost of full policy roll‑outs. The work also points toward a new direction in representation learning: training visual models explicitly to encode latent physical state, which may yield even more generalizable and sample‑efficient control policies in the future.
Comments & Academic Discussion
Loading comments...
Leave a Comment