Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
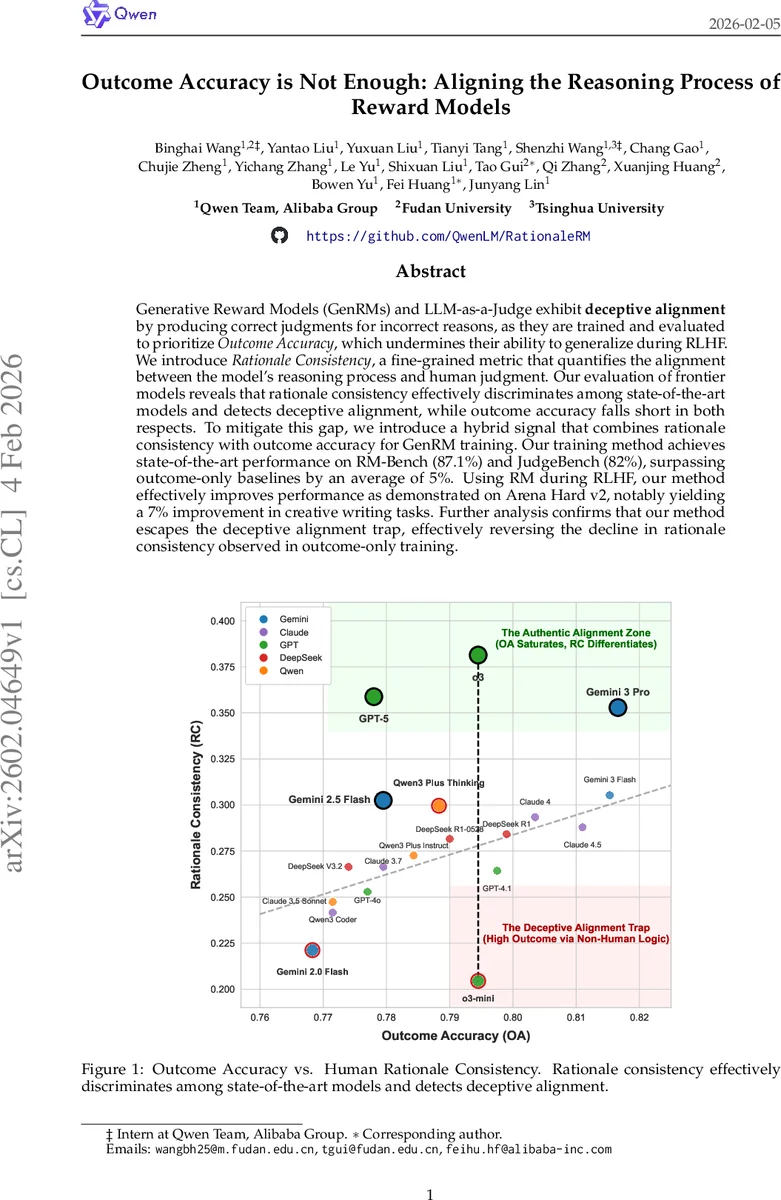
Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model’s reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
💡 Research Summary
The paper addresses a critical shortcoming in current reward models (RMs) and LLM‑as‑a‑Judge systems: they are optimized solely for outcome accuracy (OA), i.e., matching human‑annotated preference labels, which allows models to achieve high correctness while reasoning for the wrong reasons. This “deceptive alignment” hampers generalization during reinforcement learning from human feedback (RLHF).
To expose and remedy this issue, the authors introduce Rationale Consistency (RC), a fine‑grained metric that measures how well a model’s reasoning process aligns with human rationales. They construct a benchmark called MetaJudge that first decomposes human explanations into mutually exclusive atomic units (using a GPT‑5‑based pipeline) and then asks the model to output a ranked list of atomic reasons before giving its final judgment. An evaluator LLM performs strict one‑to‑one semantic matching between the human and model atomic reasons, assigning a similarity score in
Comments & Academic Discussion
Loading comments...
Leave a Comment