A principled framework for uncertainty decomposition in TabPFN
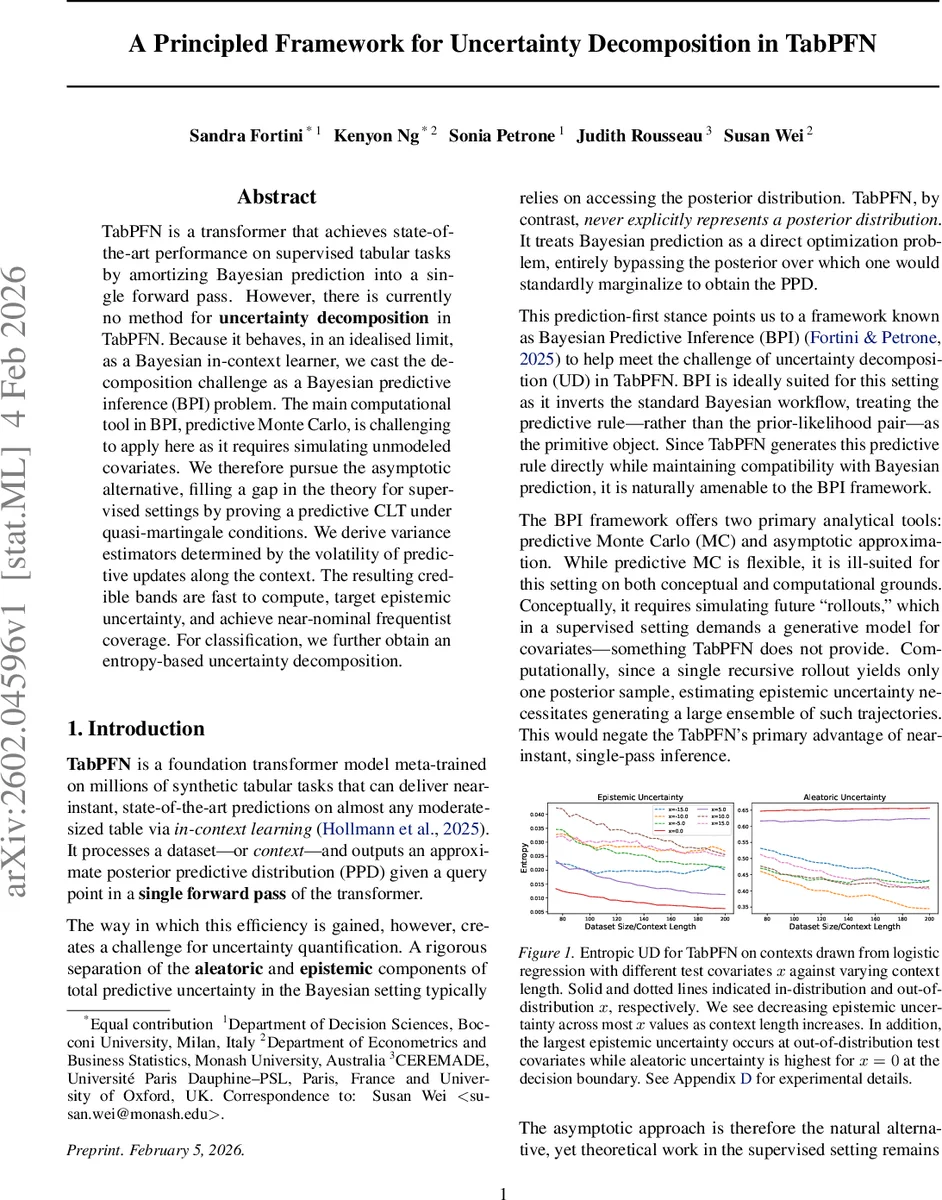
TabPFN is a transformer that achieves state-of-the-art performance on supervised tabular tasks by amortizing Bayesian prediction into a single forward pass. However, there is currently no method for uncertainty decomposition in TabPFN. Because it behaves, in an idealised limit, as a Bayesian in-context learner, we cast the decomposition challenge as a Bayesian predictive inference (BPI) problem. The main computational tool in BPI, predictive Monte Carlo, is challenging to apply here as it requires simulating unmodeled covariates. We therefore pursue the asymptotic alternative, filling a gap in the theory for supervised settings by proving a predictive CLT under quasi-martingale conditions. We derive variance estimators determined by the volatility of predictive updates along the context. The resulting credible bands are fast to compute, target epistemic uncertainty, and achieve near-nominal frequentist coverage. For classification, we further obtain an entropy-based uncertainty decomposition.
💡 Research Summary
TabPFN is a transformer‑based foundation model that, after meta‑training on millions of synthetic tabular datasets, can produce near‑instant state‑of‑the‑art predictions for any moderate‑sized table by processing the whole dataset as a context and outputting an approximate posterior predictive distribution (PPD) in a single forward pass. While this “prediction‑first” approach yields impressive accuracy, it obscures the internal Bayesian posterior, making it impossible to separate total predictive uncertainty into its aleatoric (data‑intrinsic) and epistemic (model‑related) components.
The authors address this gap by adopting the Bayesian Predictive Inference (BPI) framework, which treats the predictive rule itself—as a sequence of one‑step‑ahead predictive distributions—as the primitive object, rather than the prior‑likelihood pair. Within BPI, two main tools exist: predictive Monte Carlo (MC) and asymptotic approximations. Predictive MC would require simulating future covariates, a task TabPFN is not equipped to perform in supervised settings, and it would also destroy the model’s hallmark speed. Consequently, the paper develops an asymptotic tool: a Predictive Central Limit Theorem (Predictive CLT) that works under a quasi‑martingale condition, a relaxation of the martingale/exchangeability assumptions used in prior CLTs.
The key theoretical result states that, for any fixed covariate‑event pair ((x,A)), the sequence of predictive probabilities (P_k(x,A)=\Pr(Y_{k+1}\in A\mid X_{k+1}=x, Z_{1:k})) forms a quasi‑martingale and converges to a random limit (\tilde P(x,A)). By tracking the incremental updates (\Delta_k = P_k - P_{k-1}) across the observed context, the authors construct an empirical covariance matrix
\
Comments & Academic Discussion
Loading comments...
Leave a Comment