EMA Policy Gradient: Taming Reinforcement Learning for LLMs with EMA Anchor and Top-k KL
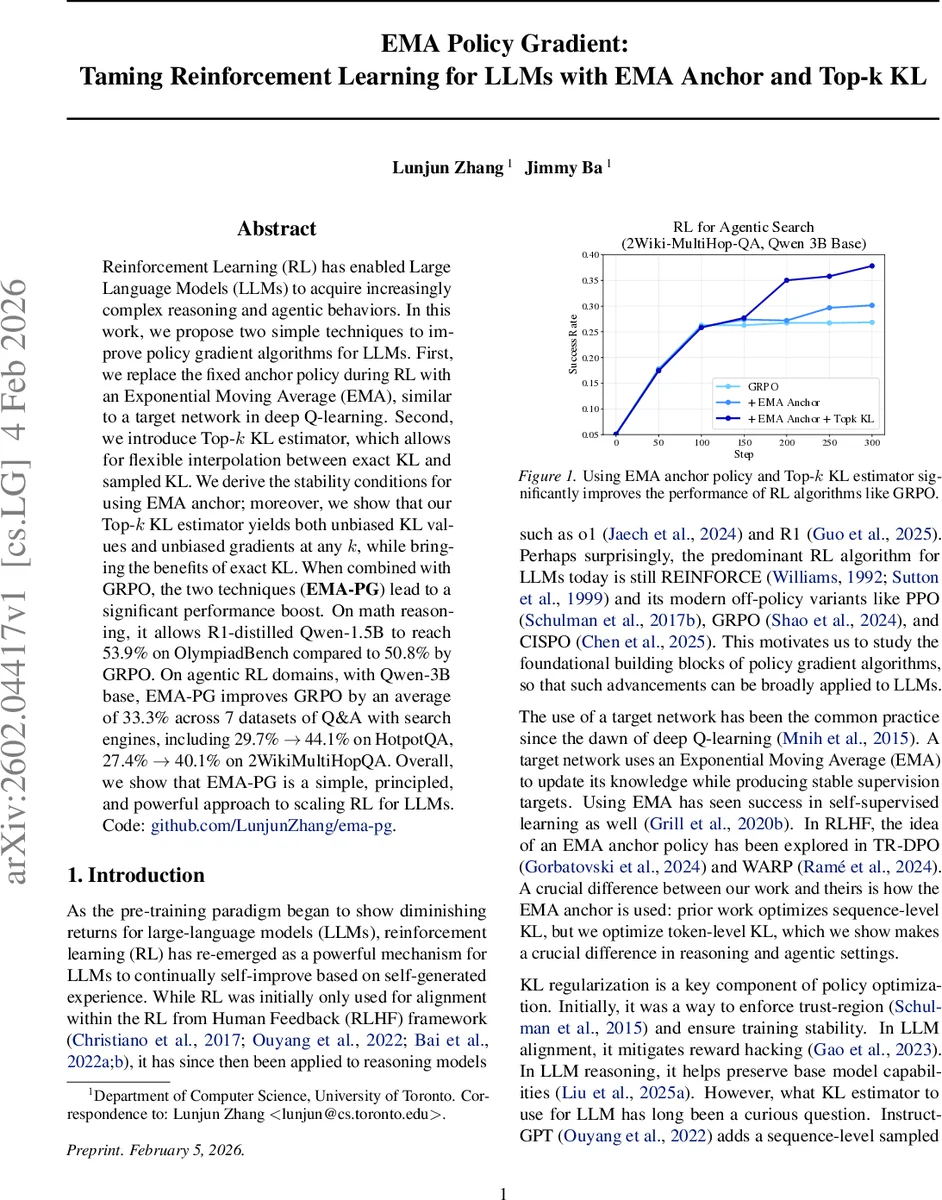
Reinforcement Learning (RL) has enabled Large Language Models (LLMs) to acquire increasingly complex reasoning and agentic behaviors. In this work, we propose two simple techniques to improve policy gradient algorithms for LLMs. First, we replace the fixed anchor policy during RL with an Exponential Moving Average (EMA), similar to a target network in deep Q-learning. Second, we introduce Top-k KL estimator, which allows for flexible interpolation between exact KL and sampled KL. We derive the stability conditions for using EMA anchor; moreover, we show that our Top-k KL estimator yields both unbiased KL values and unbiased gradients at any k, while bringing the benefits of exact KL. When combined with GRPO, the two techniques (EMA-PG) lead to a significant performance boost. On math reasoning, it allows R1-distilled Qwen-1.5B to reach 53.9% on OlympiadBench compared to 50.8% by GRPO. On agentic RL domains, with Qwen-3B base, EMA-PG improves GRPO by an average of 33.3% across 7 datasets of Q&A with search engines, including 29.7% $\rightarrow$ 44.1% on HotpotQA, 27.4% $\rightarrow$ 40.1% on 2WikiMultiHopQA. Overall, we show that EMA-PG is a simple, principled, and powerful approach to scaling RL for LLMs. Code: https://github.com/LunjunZhang/ema-pg
💡 Research Summary
The paper tackles two fundamental components of policy‑gradient reinforcement learning for large language models (LLMs): the choice of an anchor (reference) policy and the way KL‑regularization is estimated. Existing RLHF and GRPO pipelines typically use a fixed, pre‑trained model as the anchor and compute a KL penalty either at the sequence level or with a simple sampled estimator. Both choices have drawbacks: a static anchor can become stale as the policy updates, leading to large KL spikes and instability; sampled KL estimators are memory‑efficient but introduce bias in the gradient, especially when the vocabulary is huge.
EMA Anchor
The authors propose replacing the static anchor with an Exponential Moving Average (EMA) of the current policy, analogous to target networks in deep Q‑learning. The EMA policy is updated as θₑₘₐ←ηθₑₘₐ+(1−η)θ, where η∈(0,1) controls the smoothing. They derive the dynamics of the parameter lag δₜ=θₜ−θₑₘₐₜ using a local quadratic approximation of KL (via the Fisher information matrix F). Under the assumption that gradients and F change slowly over a short horizon, they obtain a closed‑form solution and prove a stability condition: αβλ_max < 1+η, where α is the policy‑gradient step size, β the KL coefficient, and λ_max the largest eigenvalue of F. This condition delineates three regimes (stable non‑oscillatory, stable oscillatory, unstable) and explains why a high EMA decay (η≈0.9) can safely accommodate larger learning rates or KL weights.
Top‑k KL Estimator
For token‑level KL, exact computation requires O(|V|) memory, which is prohibitive for vocabularies of 50k‑200k tokens. The authors introduce a Top‑k KL estimator that computes exact KL on the top‑k logits (the most probable tokens) and uses a sampled KL on the remaining tail. The estimator combines:
- `c_KL_trun = Σ_{j∈top‑k} π_θ(j)
Comments & Academic Discussion
Loading comments...
Leave a Comment