VecSet-Edit: Unleashing Pre-trained LRM for Mesh Editing from Single Image
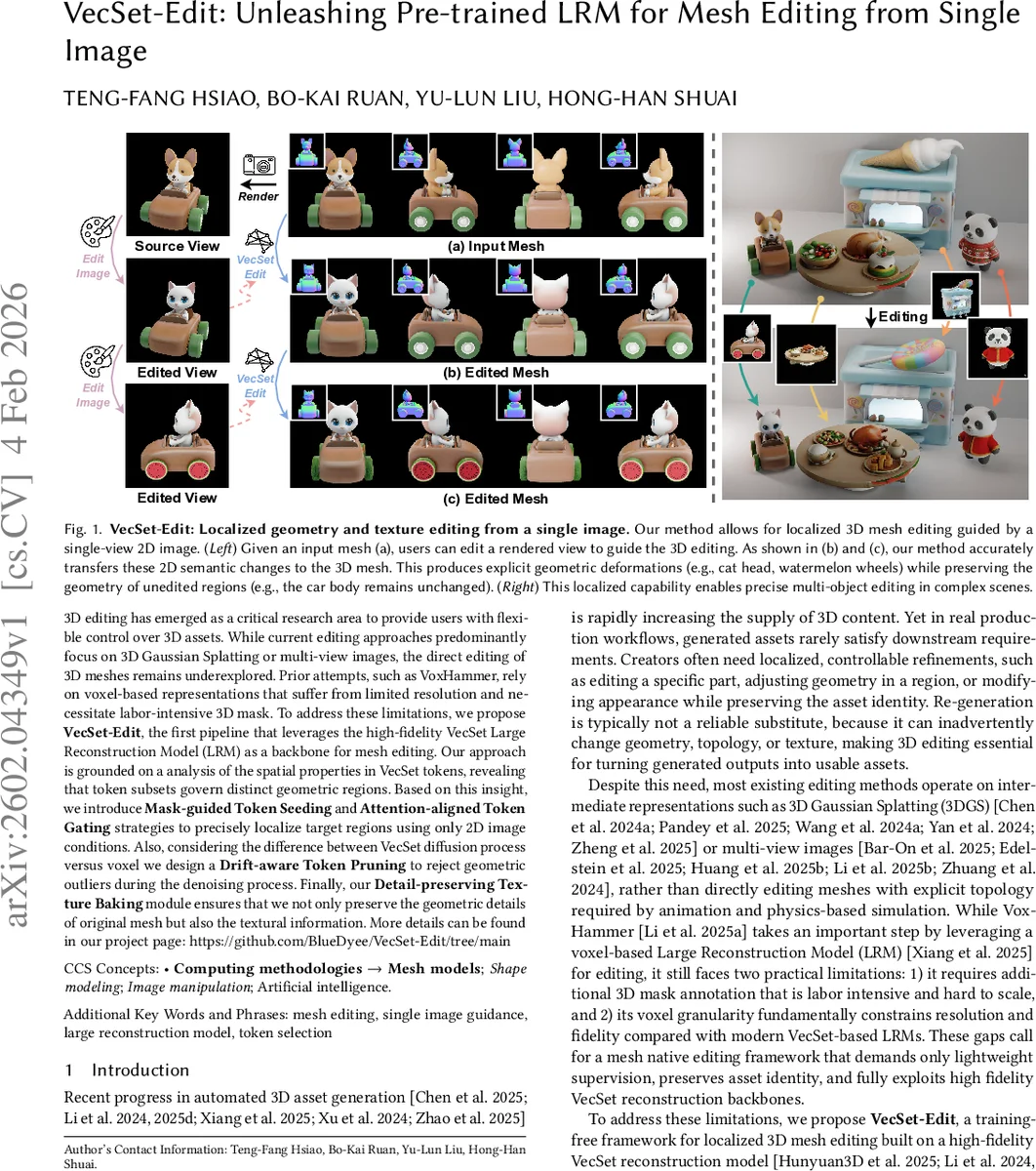
3D editing has emerged as a critical research area to provide users with flexible control over 3D assets. While current editing approaches predominantly focus on 3D Gaussian Splatting or multi-view images, the direct editing of 3D meshes remains underexplored. Prior attempts, such as VoxHammer, rely on voxel-based representations that suffer from limited resolution and necessitate labor-intensive 3D mask. To address these limitations, we propose \textbf{VecSet-Edit}, the first pipeline that leverages the high-fidelity VecSet Large Reconstruction Model (LRM) as a backbone for mesh editing. Our approach is grounded on a analysis of the spatial properties in VecSet tokens, revealing that token subsets govern distinct geometric regions. Based on this insight, we introduce Mask-guided Token Seeding and Attention-aligned Token Gating strategies to precisely localize target regions using only 2D image conditions. Also, considering the difference between VecSet diffusion process versus voxel we design a Drift-aware Token Pruning to reject geometric outliers during the denoising process. Finally, our Detail-preserving Texture Baking module ensures that we not only preserve the geometric details of original mesh but also the textural information. More details can be found in our project page: https://github.com/BlueDyee/VecSet-Edit/tree/main
💡 Research Summary
VecSet‑Edit introduces a training‑free pipeline that enables localized 3D mesh editing using only a single reference image, an edited target image, and a binary 2D mask. The method builds on a pre‑trained VecSet Large Reconstruction Model (LRM), which encodes a mesh as an unordered set of latent tokens and employs a diffusion transformer (DiT) for conditional generation. The authors first reveal that despite the unordered nature of the token set, each token retains strong spatial priors because it is derived from learnable query points that carry 3D coordinates. Empirical analysis on the Edit3D‑Bench dataset shows that selecting tokens whose associated query points fall inside a 3D bounding box can reconstruct the corresponding region with a Chamfer distance below 0.30 in 82 % of cases, confirming a “VecSet Geometry Property”.
Leveraging this property, the pipeline performs token selection in two stages. Mask‑guided Token Seeding aggregates cross‑attention maps from the DiT across diffusion timesteps and layers, weighting layers by KL‑divergence to identify tokens that attend heavily to pixels inside the user‑provided mask. This yields a coarse seed set of geometry‑relevant tokens. Attention‑aligned Token Gating then refines the set by examining self‑attention correlations among tokens, retaining only those that are strongly linked to the seed region, thereby ensuring spatial coherence and preventing leakage into unrelated mesh parts.
During diffusion‑based editing, tokens are mobile and can drift away from their original spatial locations, potentially contaminating preserved regions. To mitigate this, the authors propose Drift‑aware Token Pruning: at each denoising step, tokens are evaluated for geometric consistency with the original token subset; those that exceed a drift threshold are pruned, keeping the preserved token set untouched. This mechanism maintains clean boundaries between edited and unchanged areas throughout the denoising trajectory.
After the geometry has been edited, the Detail‑preserving Texture Baking module transfers texture from the original mesh to the edited mesh. It aligns UV maps, bakes new texture only on edited surfaces, and copies the original high‑frequency texture elsewhere, preserving fine‑grained appearance while reflecting geometric changes.
Extensive quantitative experiments on Edit3D‑Bench demonstrate that VecSet‑Edit outperforms voxel‑based approaches such as VoxHammer in Chamfer distance, F‑score, and texture PSNR, especially on thin structures and high‑frequency details. Qualitative results show accurate, localized deformations (e.g., adding a cat head to a car, turning wheels into watermelons) without altering the rest of the object, even in multi‑object scenes.
Limitations include reliance on accurate 2D mask alignment and difficulty handling topological changes; token selection may degrade when cross‑attention is diffuse. Future work aims to incorporate automatic mask generation, support topology modification, and strengthen token‑spatial correspondence through fine‑tuning.
In summary, VecSet‑Edit offers a practical solution for high‑fidelity, localized mesh editing by exploiting the spatial properties of VecSet tokens, mask‑guided token seeding, attention‑aligned gating, drift‑aware pruning, and texture baking, all without additional model training. This bridges the gap between generative 3D asset creation and precise user‑controlled editing, promising to streamline 3D content pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment