Not All Negative Samples Are Equal: LLMs Learn Better from Plausible Reasoning
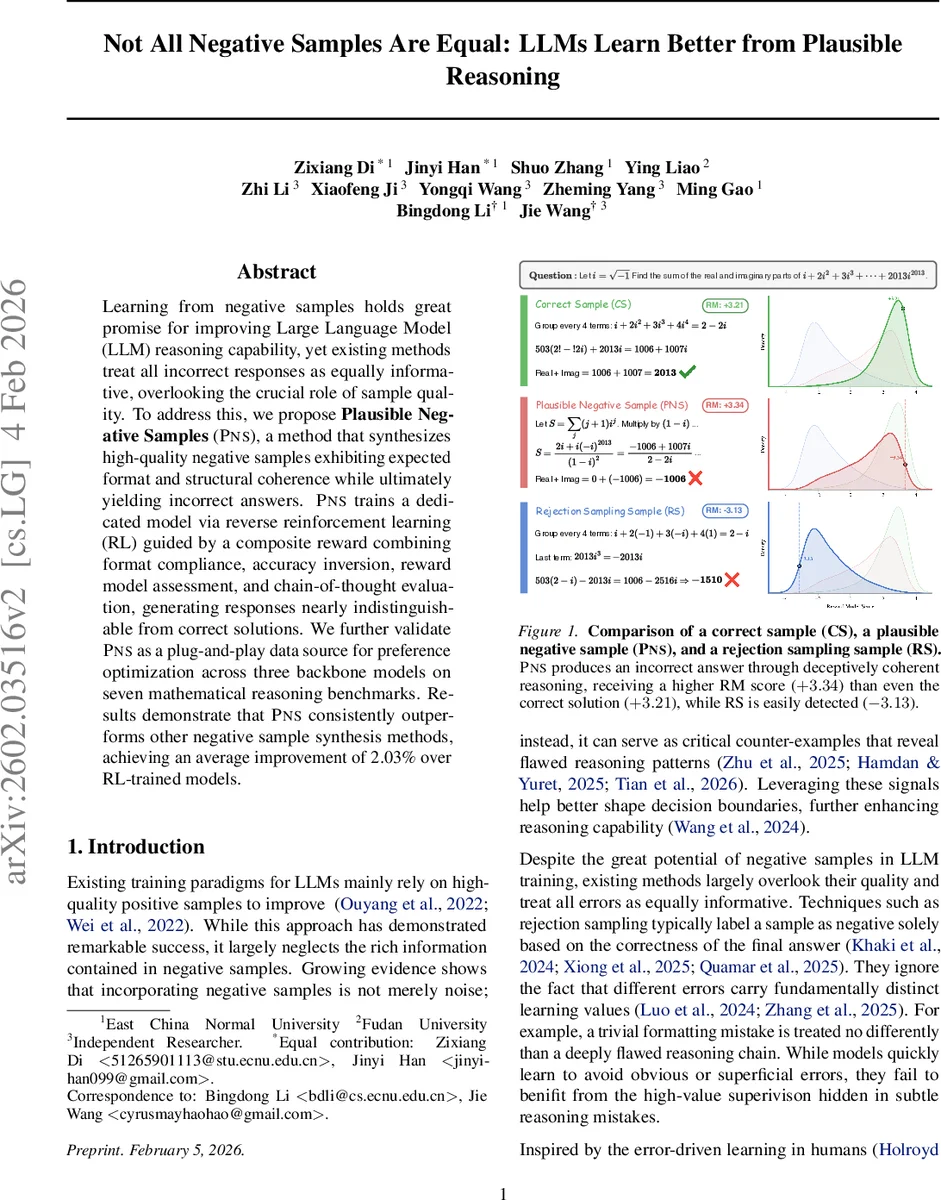
Learning from negative samples holds great promise for improving Large Language Model (LLM) reasoning capability, yet existing methods treat all incorrect responses as equally informative, overlooking the crucial role of sample quality. To address this, we propose Plausible Negative Samples (PNS), a method that synthesizes high-quality negative samples exhibiting expected format and structural coherence while ultimately yielding incorrect answers. PNS trains a dedicated model via reverse reinforcement learning (RL) guided by a composite reward combining format compliance, accuracy inversion, reward model assessment, and chain-of-thought evaluation, generating responses nearly indistinguishable from correct solutions. We further validate PNS as a plug-and-play data source for preference optimization across three backbone models on seven mathematical reasoning benchmarks. Results demonstrate that PNS consistently outperforms other negative sample synthesis methods, achieving an average improvement of 2.03% over RL-trained models.
💡 Research Summary
The paper addresses the under‑explored dimension of negative‑sample quality in the training of large language models (LLMs) for reasoning tasks. While prior work has largely treated all incorrect responses as equally informative, the authors argue that “plausible but wrong” samples—responses that follow the expected format and present a coherent chain‑of‑thought yet arrive at an incorrect final answer—provide richer learning signals because they lie close to the decision boundary between correct and incorrect reasoning.
To generate such high‑quality negative samples, the authors propose Plausible Negative Samples (PNS), a two‑phase pipeline. In Phase 1, a reward model (RM) is trained on preference pairs of correct and incorrect responses using a Center‑Regularized Bradley‑Terry loss, which encourages the RM’s scores to be symmetrically distributed around zero and to separate high‑ and low‑quality outputs. The RM is based on Qwen‑3‑4B and achieves near‑99% pairwise accuracy.
In Phase 2, a policy model (initialized from Qwen2.5‑7B‑Instruct) is fine‑tuned via reverse reinforcement learning (Reverse GRPO). The reward function is a composite of four components: (1) a format score that combines rule‑based structural checks (e.g., presence of
The generated PNS are then used as negative examples in Direct Preference Optimization (DPO), effectively augmenting the training data for downstream models. Experiments span three backbone models (Qwen2.5‑7B‑Instruct, LLaMA‑2‑13B, GPT‑Neo‑X) and seven mathematical reasoning benchmarks (including GSM8K, MATH, and SVAMP). Across all settings, incorporating PNS yields consistent improvements over baselines that use random or rejection‑sampling negatives, with an average absolute gain of 2.03 percentage points. The most notable boost is observed for Qwen2.5‑7B‑Instruct, which already benefits from prior RL‑VR fine‑tuning.
Key contributions are: (1) a novel reverse‑RL framework to synthesize “plausibly wrong” negative samples; (2) a multi‑component PNS reward that balances format compliance, factual incorrectness, and reasoning quality; and (3) empirical evidence that high‑quality negatives can further enhance LLM performance even after strong RL‑based pre‑training. The work demonstrates that carefully crafted negative examples are a powerful, underutilized resource for advancing LLM reasoning capabilities.
Comments & Academic Discussion
Loading comments...
Leave a Comment