Learning Domain Knowledge in Multimodal Large Language Models through Reinforcement Fine-Tuning
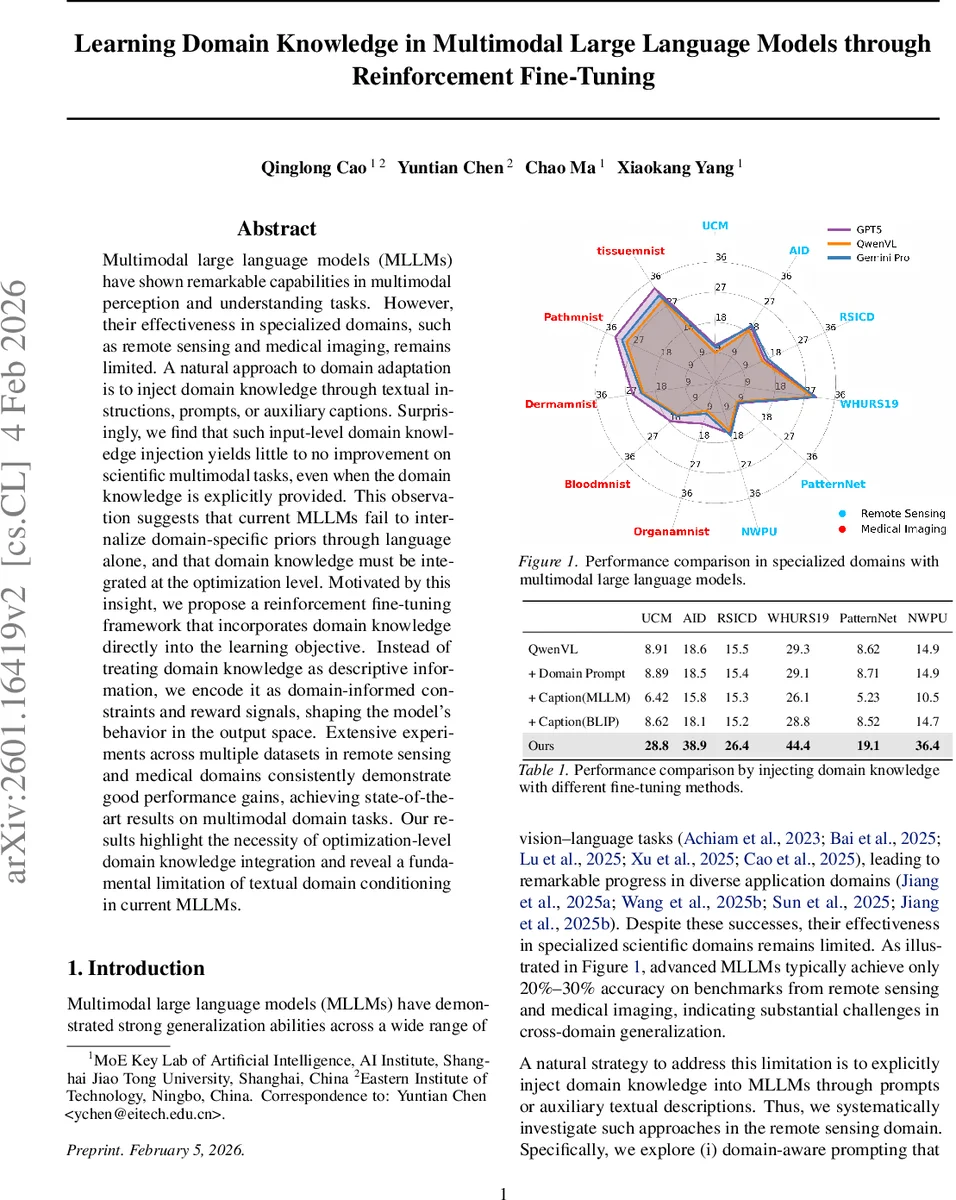
Multimodal large language models (MLLMs) have shown remarkable capabilities in multimodal perception and understanding tasks. However, their effectiveness in specialized domains, such as remote sensing and medical imaging, remains limited. A natural approach to domain adaptation is to inject domain knowledge through textual instructions, prompts, or auxiliary captions. Surprisingly, we find that such input-level domain knowledge injection yields little to no improvement on scientific multimodal tasks, even when the domain knowledge is explicitly provided. This observation suggests that current MLLMs fail to internalize domain-specific priors through language alone, and that domain knowledge must be integrated at the optimization level. Motivated by this insight, we propose a reinforcement fine-tuning framework that incorporates domain knowledge directly into the learning objective. Instead of treating domain knowledge as descriptive information, we encode it as domain-informed constraints and reward signals, shaping the model’s behavior in the output space. Extensive experiments across multiple datasets in remote sensing and medical domains consistently demonstrate good performance gains, achieving state-of-the-art results on multimodal domain tasks. Our results highlight the necessity of optimization-level domain knowledge integration and reveal a fundamental limitation of textual domain conditioning in current MLLMs.
💡 Research Summary
The paper investigates the problem of adapting multimodal large language models (MLLMs) such as GPT‑4V or Qwen‑VL to highly specialized domains like remote sensing and medical imaging. While MLLMs excel on general vision‑language benchmarks, their performance drops dramatically (often to 20‑30% accuracy) on domain‑specific tasks. A natural remedy is to inject domain knowledge through textual prompts, instructions, or auxiliary captions. The authors conduct systematic experiments on six remote‑sensing datasets (UCM, AID, RSICD, WHURS19, PatternNet, NWPU) and three MedMNIST v2 medical datasets (OrganMNIST, BloodMNIST, PathMNIST). They compare three input‑level strategies: (i) domain‑aware prompting, (ii) captions generated by the MLLM itself, and (iii) captions generated by an external model (BLIP). Table 1 shows that none of these methods consistently improve accuracy; in some cases they even degrade performance. This empirical finding demonstrates that current MLLMs cannot internalize high‑level, abstract domain priors merely by conditioning on additional text.
Motivated by this limitation, the authors propose a reinforcement‑learning based fine‑tuning framework that integrates domain knowledge directly into the learning objective. The base RL algorithm is Group Relative Policy Optimization (GRPO), a value‑free variant of PPO that computes relative advantages within a sampled group of candidate outputs, offering stability and sample efficiency. The framework introduces two complementary mechanisms:
-
Domain‑aware constraint – For each multimodal input (question + image), a domain‑specific transformation is applied (random rotations for remote‑sensing images, symmetry flips for medical scans). The transformed input is fed back into the model, producing a “domain‑support” policy distribution π_D^θ. A KL divergence loss L_dom = D_KL(π_D^θ‖π^θ) forces the original policy π^θ to remain invariant under these transformations, thereby encoding structural priors such as rotation invariance or bilateral symmetry.
-
Domain‑aware reward shaping – The degree of alignment between π^θ and π_D^θ is measured by the Jensen–Shannon divergence D_i = D_JS(π_D^θ‖π^θ) for each sampled output. The original GRPO advantage A_i is re‑weighted as A_d_i = (1 − D_i)·A_i, giving higher advantage to samples that better satisfy the domain constraint. The final objective combines the re‑weighted advantages, the standard KL regularization to a reference policy π_ref (preserving general knowledge), and the domain constraint term.
Mathematically, the loss is: L_DA(θ) = E_{o_i∼π_old}
Comments & Academic Discussion
Loading comments...
Leave a Comment