Aster: Autonomous Scientific Discovery over 20x Faster Than Existing Methods
We introduce Aster, an AI agent for autonomous scientific discovery capable of operating over 20 times faster than existing frameworks. Given a task, an initial program, and a script to evaluate the performance of the program, Aster iteratively improves the program, often leading to new state-of-the-art performances. Aster’s significant reduction in the number of iterations required for novel discovery expands the domain of tractable problems to include tasks with long evaluation durations, such as multi-hour machine learning training runs. We applied Aster to problems in mathematics, GPU kernel engineering, biology, neuroscience, and language model training. More specifically: the Erdos minimum overlap problem, optimizing the TriMul kernel, a single-cell analysis denoising problem, training a neural activity prediction model to perform well on ZAPBench, and the NanoGPT Speedrun Competition. Aster attains SOTA results in every task, except for ZAPBench, where it matches the performance of the best human solution with less than 1/190th of the compute. Aster is accessible via a web interface and API at asterlab.ai.
💡 Research Summary
The paper introduces Aster, an autonomous scientific discovery agent that dramatically accelerates the iterative code‑generation loop used by large language model (LLM)‑based discovery systems. By taking an initial program, an evaluator script, and a natural‑language prompt, Aster repeatedly asks an LLM to propose improved code, runs the evaluator, stores results, and feeds the best candidates back into the next iteration. The key novelty lies in two engineering advances: (1) a mixed‑model pool (80 % Gemini 2.0 Flash, 20 % Claude 3.7 Sonnet) that yields higher‑quality code suggestions, and (2) an “Iteration Speedup” module that generates multiple candidate programs per iteration, predicts their likely performance with a lightweight surrogate model, and only executes the most promising ones. This reduces the number of expensive evaluations dramatically.
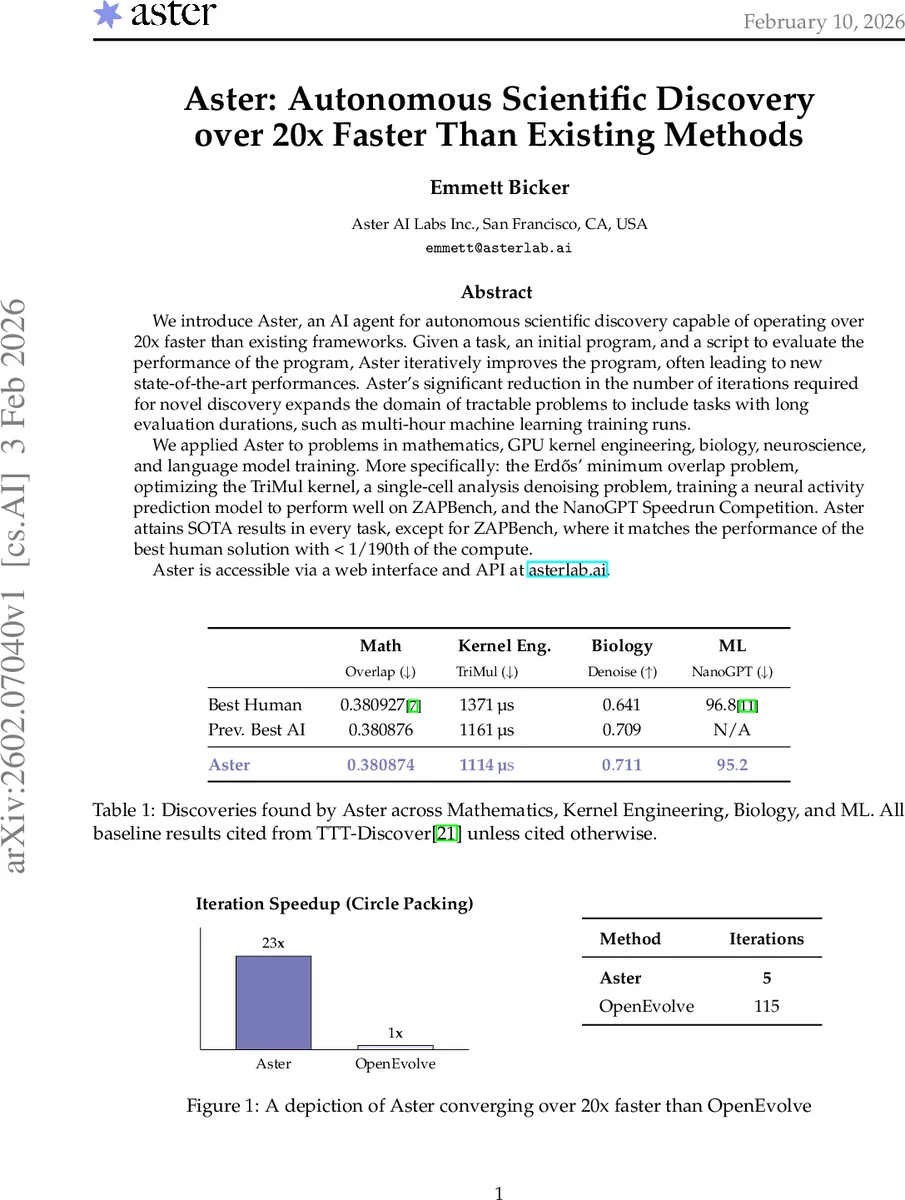
The authors benchmark Aster on the classic 26‑circle packing problem, a standard test for autonomous discovery frameworks. While OpenEvolve (the leading open‑source baseline) required 115 effective iterations to reach a score of 2.634, Aster surpassed that threshold in just 5 iterations and matched the current state‑of‑the‑art score (2.635983) after 6 iterations. This 20× speedup demonstrates that Aster can achieve comparable or better results with far fewer costly evaluations.
Aster’s capabilities are then validated across five diverse domains:
-
Erdős Minimum Overlap Problem (Mathematics) – Starting from a very simple baseline, Aster performed 40 iterations and improved the best known bound from 0.380876 to 0.380874. The solution uses a step function with 8192 intervals, far finer than the previous 600‑interval construction, indicating higher precision.
-
Single‑Cell RNA‑seq Denoising (Biology) – Using the OpenProblems benchmark, Aster raised the mean composite score from 0.709 to 0.711 by reducing the mean‑squared error (MSE) to 0.150 while keeping the Poisson error comparable (0.049). The improvement is driven mainly by a better handling of sparsity in gene‑expression matrices.
-
TriMul GPU Kernel Optimization (Systems) – Targeting the forward pass of the triangular matrix multiplication kernel on an NVIDIA H100, Aster iterated 70 times and cut runtime from the prior best 1161 µs to 1114 µs, a 4 % gain. The optimizer refined Triton kernel launch parameters, memory load patterns, and eliminated redundant calculations.
-
NanoGPT Speedrun (Machine Learning) – The competition asks participants to train a language model to a target loss on 8 H100 GPUs as quickly as possible. Aster achieved a training time of 95.2 seconds in 8 iterations, beating the previous AI‑only records (Hiverge 1.3 % and Locus 0.9 %) with a 1.6 % speedup. The gains stem from fine‑tuning Triton kernels and streamlining data pipelines.
-
ZAP‑Bench (Neuroscience / Large‑Scale Model Training) – This task requires training a model to predict whole‑brain zebrafish activity, a computation that traditionally consumes 36 hours on 16 A100 GPUs. Aster ran 34 iterations (≈2.5 days on a single T4 GPU) and matched the best human MAE of 0.0182, using 190× less compute. This demonstrates that Aster can handle long‑duration evaluations that were previously infeasible for autonomous discovery.
The paper discusses several limitations. Aster depends on deterministic, automatable evaluator scripts; any nondeterminism or manual intervention can break the loop. Its performance is tied to the underlying LLMs, so future model updates may affect reproducibility. Moreover, the discovered solutions can become highly parameter‑dense (e.g., 8192‑interval step functions), making analytical insight harder. The authors propose future work on meta‑learning based evaluation cost prediction, multi‑objective optimization (balancing performance, resource usage, and interpretability), and formal verification of generated code.
In conclusion, Aster delivers a >20× reduction in required iterations across a spectrum of scientific and engineering problems, enabling autonomous discovery on tasks with multi‑hour evaluation times. By dramatically shrinking the computational budget, Aster expands the tractable problem space for AI‑driven research and sets a new benchmark for self‑improving code generation systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment