Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
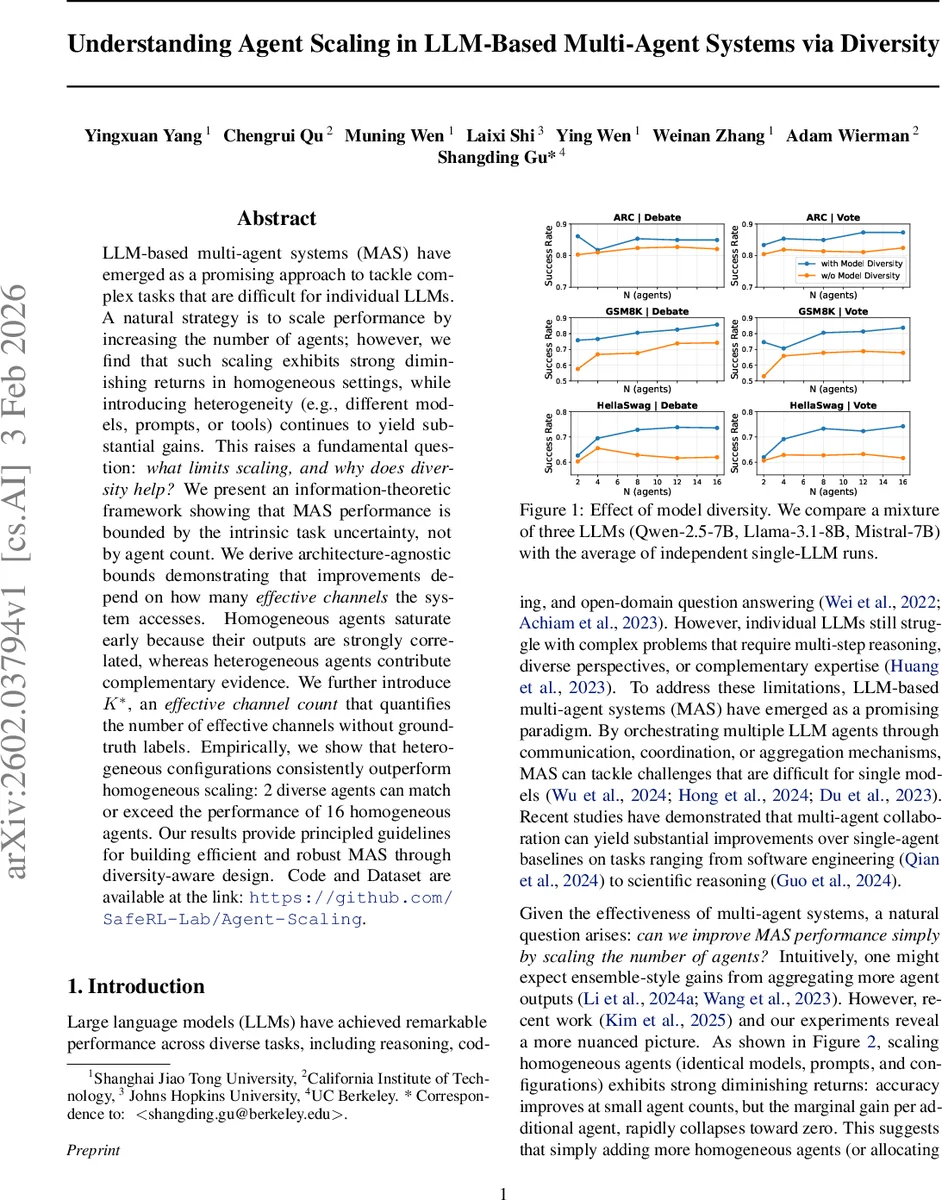
LLM-based multi-agent systems (MAS) have emerged as a promising approach to tackle complex tasks that are difficult for individual LLMs. A natural strategy is to scale performance by increasing the number of agents; however, we find that such scaling exhibits strong diminishing returns in homogeneous settings, while introducing heterogeneity (e.g., different models, prompts, or tools) continues to yield substantial gains. This raises a fundamental question: what limits scaling, and why does diversity help? We present an information-theoretic framework showing that MAS performance is bounded by the intrinsic task uncertainty, not by agent count. We derive architecture-agnostic bounds demonstrating that improvements depend on how many effective channels the system accesses. Homogeneous agents saturate early because their outputs are strongly correlated, whereas heterogeneous agents contribute complementary evidence. We further introduce $K^*$, an effective channel count that quantifies the number of effective channels without ground-truth labels. Empirically, we show that heterogeneous configurations consistently outperform homogeneous scaling: 2 diverse agents can match or exceed the performance of 16 homogeneous agents. Our results provide principled guidelines for building efficient and robust MAS through diversity-aware design. Code and Dataset are available at the link: https://github.com/SafeRL-Lab/Agent-Scaling.
💡 Research Summary
The paper investigates why simply increasing the number of agents in large‑language‑model (LLM) based multi‑agent systems (MAS) yields diminishing returns, and why introducing heterogeneity (different models, prompts, personas, or tools) continues to improve performance. The authors formalize MAS operation as a sequence of agent calls that produce a transcript Z₁:n given a task input X and a ground‑truth answer Y. They define “usable evidence” as the conditional mutual information I_MAS(n) = I(Z₁:n; Y | X), which quantifies how much uncertainty about Y is reduced after observing the transcript. By the chain rule, I_MAS(n) = Σ_i Δ_i where Δ_i = I(Z_i; Y | X, Z_{<i}) is the incremental information contributed by the i‑th call.
A key theoretical result (Theorem 3.2) shows that I_MAS(n) can never exceed the intrinsic task uncertainty H(Y | X). Consequently, once the MAS extracts information close to this bound, adding more agents cannot improve performance. The authors argue that homogeneous agents produce highly correlated outputs, causing Δ_i to drop quickly and leading to early saturation. In contrast, heterogeneous agents generate complementary evidence, keeping Δ_i relatively high for longer.
To capture the effect of heterogeneity, the paper introduces a configuration type b ∈ B for each call, representing a specific combination of model, prompt, decoding strategy, or tool. For parallel workflows (e.g., majority voting) they define a per‑type single‑call information I_b, and for sequential workflows (e.g., debate) a per‑type maximal incremental contribution I_max^b. They derive architecture‑independent upper bounds:
- Parallel: I_parallel ≤ min{ H(Y | X), Σ_{b∈B} m_b I_b }
- Sequential: I_seq ≤ min{ H(Y | X), Σ_{b∈B} m_b I_max^b }
where m_b is the number of calls of type b. These bounds depend on the multiset of configuration types rather than the raw call count n, highlighting that the “effective channel count” is the true driver of performance.
The authors formalize the notion of an effective channel as an independent source of task‑relevant information. If two agents follow nearly identical reasoning, they contribute only one effective channel; if they follow distinct reasoning paths, they contribute two. They introduce a complementarity rate α ∈ (0,1) that measures the probability that a new channel uncovers previously missing evidence, and define the effective channel count K. Because ground‑truth labels are often unavailable, they propose K* – a label‑free estimator of K based on statistical dependence among agent outputs. Empirically, K* correlates strongly with observed performance.
Experiments span seven benchmarks (ARC, GSM8K, HellaSwag, etc.) and three base models (Qwen‑2.5‑7B, Llama‑3.1‑8B, Mistral‑7B). The authors compare homogeneous scaling (identical agents) with heterogeneous configurations (different models, prompts, or tool access). Results show that two diverse agents can match or exceed the performance of sixteen homogeneous agents, confirming that diversity dramatically increases the effective channel count. Moreover, K* reliably predicts when adding agents will be beneficial.
The paper’s contributions are threefold: (1) a rigorous information‑theoretic bound showing that MAS performance is limited by H(Y | X) rather than agent count; (2) architecture‑agnostic analysis of common MAS paradigms (voting, debate, centralized orchestration) that explains why homogeneous systems saturate early; (3) the introduction of K* as a practical, label‑free metric for guiding diversity‑aware MAS design. Practically, the work suggests that system designers should prioritize heterogeneity—mixing models, prompts, or tools—to maximize effective channels, rather than merely scaling the number of identical agents. This approach yields better performance per compute budget and improves robustness. Limitations include the need for further study on communication overhead, tool‑access costs, and real‑time constraints in large‑scale deployments. Nonetheless, the theoretical framework and empirical evidence provide a solid foundation for future research on efficient, robust LLM‑based multi‑agent collaboration.
Comments & Academic Discussion
Loading comments...
Leave a Comment