UniGeM: Unifying Data Mixing and Selection via Geometric Exploration and Mining
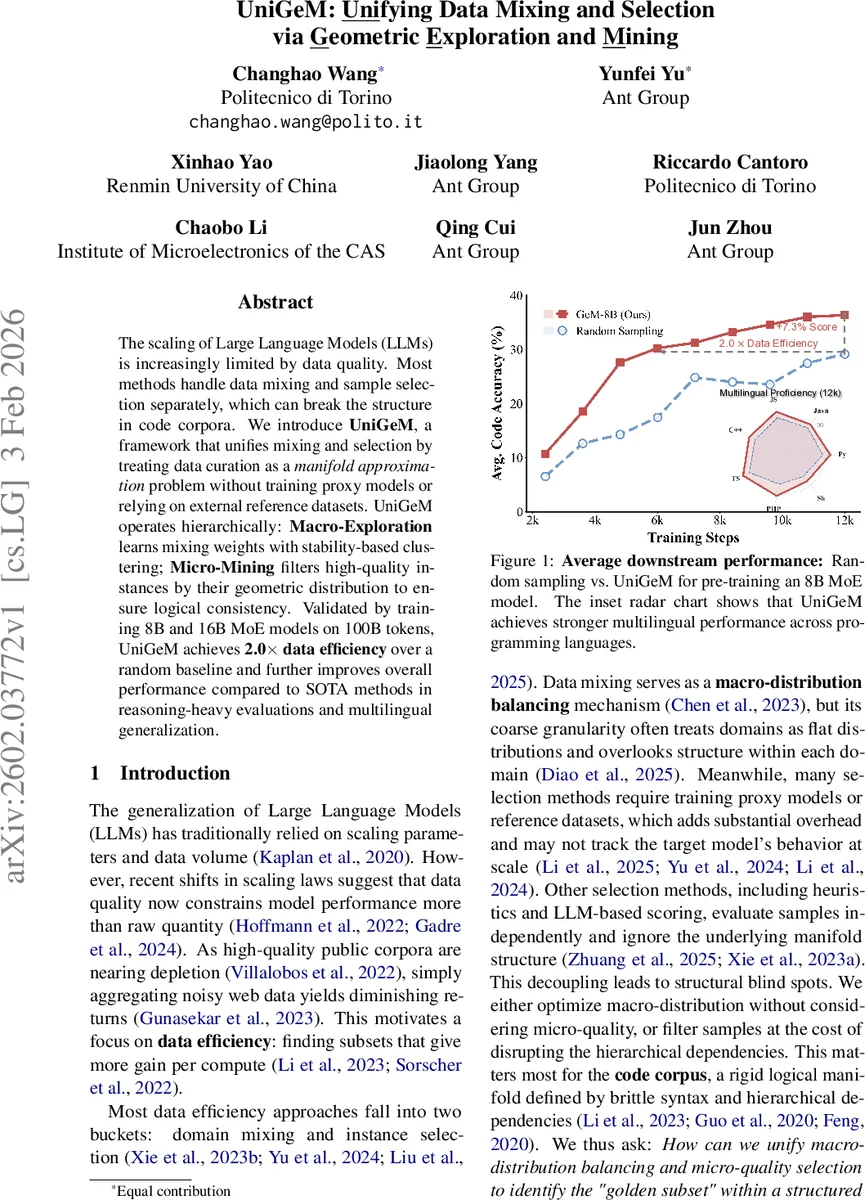
The scaling of Large Language Models (LLMs) is increasingly limited by data quality. Most methods handle data mixing and sample selection separately, which can break the structure in code corpora. We introduce \textbf{UniGeM}, a framework that unifies mixing and selection by treating data curation as a \textit{manifold approximation} problem without training proxy models or relying on external reference datasets. UniGeM operates hierarchically: \textbf{Macro-Exploration} learns mixing weights with stability-based clustering; \textbf{Micro-Mining} filters high-quality instances by their geometric distribution to ensure logical consistency. Validated by training 8B and 16B MoE models on 100B tokens, UniGeM achieves \textbf{2.0$\times$ data efficiency} over a random baseline and further improves overall performance compared to SOTA methods in reasoning-heavy evaluations and multilingual generalization.
💡 Research Summary
The paper introduces UniGeM, a unified framework for data mixing and instance selection in large‑scale language model pre‑training. Rather than treating mixing (macro‑distribution balancing) and selection (micro‑quality filtering) as separate steps, UniGeM casts data curation as a manifold approximation problem. The raw corpus is first embedded with a frozen encoder into normalized vectors that define a latent manifold.
In Stage‑I (Macro‑Exploration), the method computes four geometric descriptors for each candidate cluster: cohesion (inverse intra‑cluster distance), size, average sequence length, and entropy. These are combined with a spectral‑consensus weight vector to produce a scalar geometric score for each cluster. To determine the appropriate granularity, the authors evaluate stability across multiple clustering resolutions using a soft alignment matrix based on cosine similarity of centroids. Kendall’s τ between original and projected scores quantifies stability; the resolution with the highest τ (K*) is selected. A softmax over the geometric scores yields a mixing budget rₖ for each macro‑cluster, ensuring that semantically dense regions receive more samples.
Stage‑II (Micro‑Mining) refines each macro‑cluster by sub‑clustering into finer granules. For each sub‑cluster, a small probe set is extracted and fed to a large language model acting as a “knowledge probe” to obtain a semantic quality score P_{S_j}. A structural penalty L_struct is defined as a normalized Mahalanobis distance between the sub‑cluster’s feature means (length, entropy) and the parent cluster’s global statistics, discouraging outliers. Additionally, a cohesion gate β_{S_j}=σ(z_{S_j}^{coh}−z_{C_k}^{coh}) modulates the sampling weight based on how compact the sub‑cluster is relative to its parent. The final sampling weight combines the inherited macro budget, the semantic score, the exponential of the negative structural penalty, and the cohesion gate:
W(S_j) ∝ r_k · P_{S_j} · exp(−λ L_struct) · (β_{S_j}+ε).
The authors provide a theoretical analysis showing that the Wasserstein‑2 distance between the true data distribution and the empirical distribution of the selected subset can be bounded by a term reflecting macro‑quantization error plus a reduction term Δ(k)_gain contributed by micro‑pruning. This bound justifies why preserving both global coverage and local structure yields superior approximation.
Experiments are conducted on a 100 B‑token corpus composed of a 70 % code mixture (The Stack Dedup) and a 30 % text mixture (Common Crawl). A Qwen‑3 embedding model is used to embed a 20 % representative sample for clustering; the optimal macro resolution is K* = 72. Two MoE Transformers (8 B and 16 B total parameters, 1.4 B active parameters) are trained from scratch for one epoch under identical training recipes, differing only in data curation.
Results show that UniGeM achieves 2.0× data efficiency compared to uniform random sampling and consistently outperforms strong baselines such as Meta‑rater (LLM‑based instance scoring) and Nemotron‑CLIMB (domain‑level mixing) across a suite of code generation benchmarks (HE, MBPP, LiveCode, CruxEval) and a multilingual proficiency test (12 k samples). The 16 B model gains up to +6.0 points on HE and +5.3 on CruxEval, while the 8 B model surpasses the baselines by 5–7 points on most metrics.
Ablation studies confirm the necessity of both stages: removing the hierarchical structure, using only micro‑mining, or discarding macro‑level budgeting each leads to substantial performance drops. The analysis also highlights that the geometric cohesion gate and structural penalty are crucial for preserving the logical dependencies inherent in code.
Limitations include dependence on the quality of the frozen embedding model, computational overhead of large‑scale clustering, and the assumption that data lie on a low‑dimensional manifold. Future work may explore lightweight online clustering, extension to multimodal corpora, and learning the probe module jointly with the main model.
In summary, UniGeM offers a principled, geometry‑driven approach that unifies macro‑distribution balancing and micro‑quality selection, delivering marked improvements in data efficiency and downstream performance for large‑scale LLM pre‑training, especially in domains where structural consistency (e.g., source code) is critical.
Comments & Academic Discussion
Loading comments...
Leave a Comment