From Single Scan to Sequential Consistency: A New Paradigm for LIDAR Relocalization
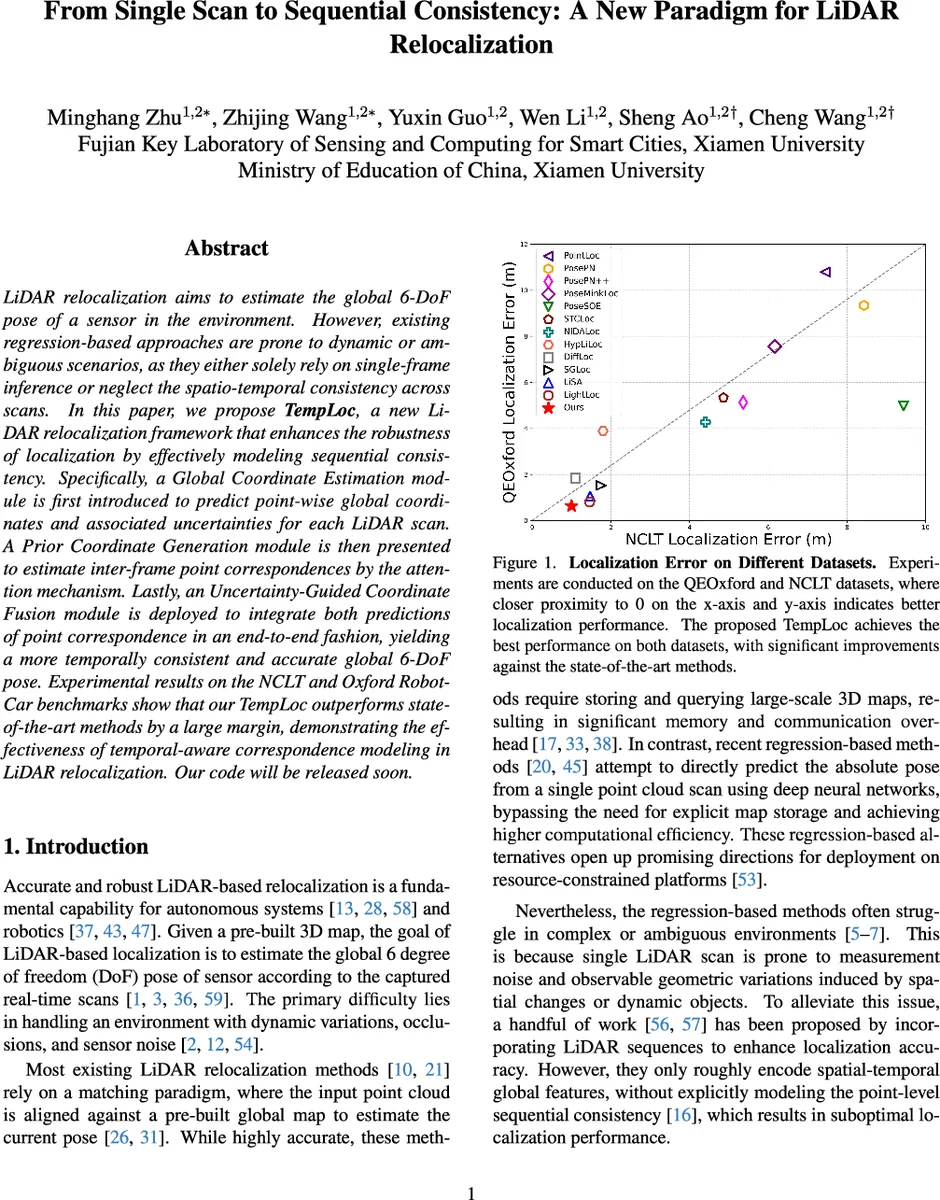
LiDAR relocalization aims to estimate the global 6-DoF pose of a sensor in the environment. However, existing regression-based approaches are prone to dynamic or ambiguous scenarios, as they either solely rely on single-frame inference or neglect the spatio-temporal consistency across scans. In this paper, we propose TempLoc, a new LiDAR relocalization framework that enhances the robustness of localization by effectively modeling sequential consistency. Specifically, a Global Coordinate Estimation module is first introduced to predict point-wise global coordinates and associated uncertainties for each LiDAR scan. A Prior Coordinate Generation module is then presented to estimate inter-frame point correspondences by the attention mechanism. Lastly, an Uncertainty-Guided Coordinate Fusion module is deployed to integrate both predictions of point correspondence in an end-to-end fashion, yielding a more temporally consistent and accurate global 6-DoF pose. Experimental results on the NCLT and Oxford Robot-Car benchmarks show that our TempLoc outperforms stateof-the-art methods by a large margin, demonstrating the effectiveness of temporal-aware correspondence modeling in LiDAR relocalization. Our code will be released soon.
💡 Research Summary
TempLoc addresses the longstanding challenge of robust LiDAR relocalization in dynamic and ambiguous environments by explicitly modeling temporal consistency at the point level. The framework consists of three tightly coupled modules.
-
Global Coordinate Estimation (GCE) builds on the LightLoc scene‑coordinate regression network but adds a shared MLP head that predicts per‑point uncertainty scores together with global coordinates. Uncertainty labels are derived from the L1 distance between predicted and ground‑truth coordinates using a dynamic threshold τ that decays during training, allowing the network to focus on severe outliers early and refine confidence later. The loss combines a regression term (MSE on coordinates) and an uncertainty term (binary cross‑entropy on the confidence label).
-
Prior Coordinate Generation (PCG) extracts inter‑frame point correspondences using a point‑cloud registration backbone (PCAM) enhanced with self‑attention. For two consecutive scans (P^{t-1}) and (P^{t}), a global attention matrix (A_{global}) is computed, yielding soft correspondences (m(p_i^{t-1})) for each point in the previous frame. Because these soft points do not coincide with actual sampled points, a k‑nearest‑neighbor interpolation is performed: each real point in the current frame gathers its k closest soft correspondences and computes a distance‑weighted average of the world coordinates carried by those soft neighbors. This produces a “prior” coordinate (p^{prior}_j) and an associated uncertainty (u^{prior}_j) that encode temporal information from the preceding scan.
-
Uncertainty‑Guided Coordinate Fusion (UCF) merges the measurement coordinates from GCE ((p^{meas}, u^{meas})) with the prior coordinates from PCG ((p^{prior}, u^{prior})). For each point, the two uncertainties are concatenated and passed through a Softmax layer to obtain adaptive fusion weights (w^{prior}) and (w^{meas}). The final fused coordinate is (p^{fuse}=w^{prior}p^{prior}+w^{meas}p^{meas}), and the fused uncertainty is similarly weighted. This data‑driven fusion mimics Kalman‑filter weighting but is fully differentiable and learned end‑to‑end.
The refined 3‑D‑3‑D correspondences are fed into a RANSAC‑based pose estimator to recover the global 6‑DoF pose. The overall training objective is a weighted sum of the three module losses:
(L_{total}= \lambda_1 L_{GCE}+ \lambda_2 L_{PCG}+ \lambda_3 L_{Fuse}) with (\lambda_1=0.3), (\lambda_2=0.3), (\lambda_3=0.4).
Extensive experiments on the NCLT and Oxford RobotCar datasets demonstrate that TempLoc outperforms state‑of‑the‑art APR, SCR, and sequence‑based methods (e.g., LightLoc, STCLoc, NIDALoc) by a large margin. On NCLT, the average translation error is reduced by roughly 30 % compared to the strongest baseline, and the method remains stable in scenes with heavy traffic, moving objects, and repetitive structures. The authors also commit to releasing the code, facilitating reproducibility and real‑world deployment.
In summary, TempLoc’s key contributions are: (1) per‑point uncertainty estimation that quantifies the reliability of scene‑coordinate predictions; (2) attention‑driven soft correspondence generation coupled with neighborhood interpolation to create temporally coherent priors; (3) an uncertainty‑aware fusion mechanism that adaptively balances measurement and prior information; and (4) a comprehensive empirical validation showing significant gains in accuracy and robustness. By integrating temporal consistency directly into the coordinate regression pipeline, TempLoc sets a new benchmark for LiDAR relocalization and offers a practical solution for autonomous platforms that require both precision and real‑time performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment