Quantized Evolution Strategies: High-precision Fine-tuning of Quantized LLMs at Low-precision Cost
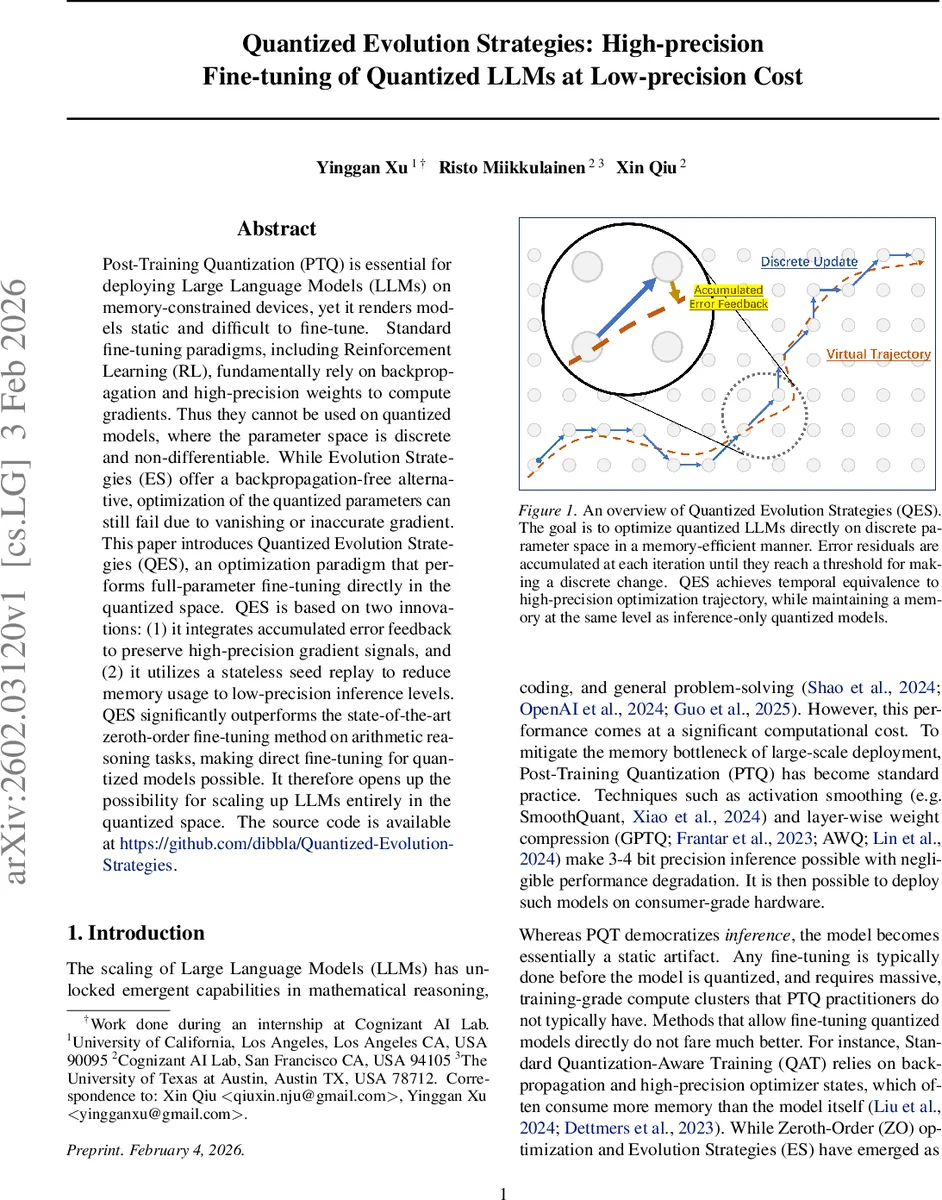
Post-Training Quantization (PTQ) is essential for deploying Large Language Models (LLMs) on memory-constrained devices, yet it renders models static and difficult to fine-tune. Standard fine-tuning paradigms, including Reinforcement Learning (RL), fundamentally rely on backpropagation and high-precision weights to compute gradients. Thus they cannot be used on quantized models, where the parameter space is discrete and non-differentiable. While Evolution Strategies (ES) offer a backpropagation-free alternative, optimization of the quantized parameters can still fail due to vanishing or inaccurate gradient. This paper introduces Quantized Evolution Strategies (QES), an optimization paradigm that performs full-parameter fine-tuning directly in the quantized space. QES is based on two innovations: (1) it integrates accumulated error feedback to preserve high-precision gradient signals, and (2) it utilizes a stateless seed replay to reduce memory usage to low-precision inference levels. QES significantly outperforms the state-of-the-art zeroth-order fine-tuning method on arithmetic reasoning tasks, making direct fine-tuning for quantized models possible. It therefore opens up the possibility for scaling up LLMs entirely in the quantized space. The source code is available at https://github.com/dibbla/Quantized-Evolution-Strategies .
💡 Research Summary
The paper “Quantized Evolution Strategies (QES)” addresses a critical limitation in deploying Large Language Models (LLMs): the inability to fine-tune models after they have undergone Post-Training Quantization (PTQ). While PTQ is essential for running LLMs on memory-constrained devices, it renders models static because standard fine-tuning methods, including Reinforcement Learning, rely on backpropagation and high-precision weights, which are incompatible with discrete, non-differentiable quantized parameter spaces. Although Evolution Strategies (ES) offer a backpropagation-free alternative, they fail in quantized spaces due to vanishing or inaccurate gradient signals, a problem termed “gradient stagnation.”
QES introduces a novel optimization paradigm that enables full-parameter fine-tuning directly on the quantized model weights. Its core innovation rests on two pillars designed to maintain high-precision learning dynamics while operating exclusively in low-precision space and keeping memory footprint at inference-only levels.
First, the Accumulated Error Feedback mechanism tackles the stagnation problem. Inspired by Delta-Sigma modulation from signal processing, it does not discard the fractional part of a computed update (the quantization error). Instead, this error is accumulated in a high-precision residual vector. Over multiple optimization steps, these tiny residuals sum up until they are large enough to trigger an actual discrete change (e.g., incrementing or decrementing an integer weight by 1). This allows QES to simulate a much finer-grained learning rate on the discrete lattice, effectively tracking the trajectory of a high-precision optimizer.
Second, the Stateless Seed Replay mechanism solves the memory overhead problem. Storing the high-precision error residual vector for a billion-parameter model would negate the memory savings of quantization. QES avoids storing this state. Instead, it maintains only a history buffer containing the random seeds and reward scores from recent optimization steps. When updating parameters, it replays these historical steps on-the-fly to reconstruct the necessary gradient estimates and, crucially, the current error residual state. This reduces the memory consumption of the optimization process to the same level as running inference with the quantized model alone.
The paper positions QES within related work on LLM quantization, zeroth-order fine-tuning (like MeZO and QuZO), and techniques for reducing discretization errors. It formally defines the optimization challenge in quantized spaces and provides detailed algorithms for both the core QES update with error feedback and the stateless update with seed replay.
Empirical validation is conducted on arithmetic reasoning using the Countdown task. The authors fine-tune quantized versions (INT4, INT8) of Qwen2.5-1.5B and 3B models. QES is compared against the quantized base models, the state-of-the-art zeroth-order method for quantized models (QuZO), and an “oracle” variant of QES that stores the full error residual (impractically memory-heavy). The results show that QES significantly improves the base model performance across all quantization formats and model sizes. It substantially outperforms QuZO, which struggles especially in low-bit settings. Furthermore, the performance of the practical QES (with seed replay) is only slightly lower than the oracle version, proving the effectiveness of the stateless approximation.
In conclusion, QES democratizes fine-tuning for quantized LLMs by making it feasible on hardware that previously could only support inference. It opens a new avenue for efficient model adaptation at the edge. Furthermore, by enabling effective learning directly in quantized space, it suggests a future research direction: scaling up LLMs by fitting more quantized parameters into a fixed memory budget, rather than just using quantization for compressing pre-trained models.
Comments & Academic Discussion
Loading comments...
Leave a Comment