ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution
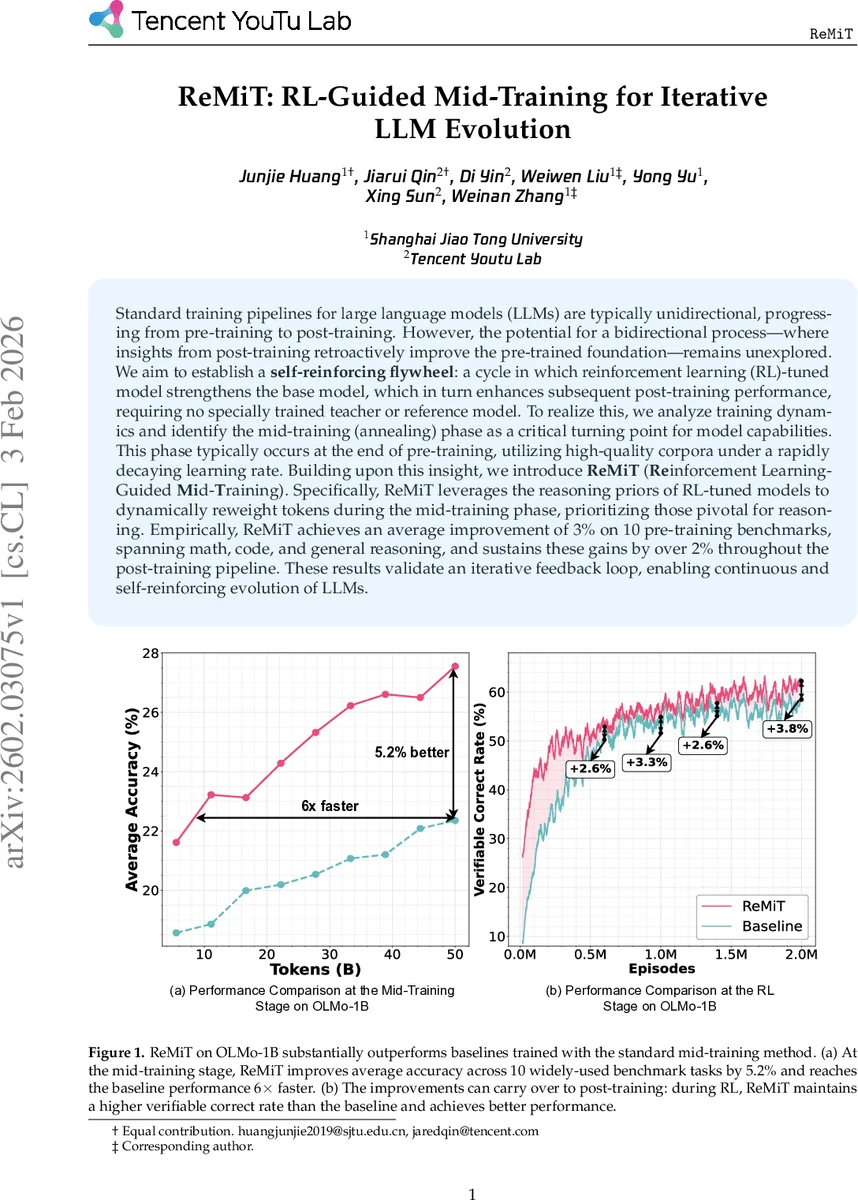
Standard training pipelines for large language models (LLMs) are typically unidirectional, progressing from pre-training to post-training. However, the potential for a bidirectional process–where insights from post-training retroactively improve the pre-trained foundation–remains unexplored. We aim to establish a self-reinforcing flywheel: a cycle in which reinforcement learning (RL)-tuned model strengthens the base model, which in turn enhances subsequent post-training performance, requiring no specially trained teacher or reference model. To realize this, we analyze training dynamics and identify the mid-training (annealing) phase as a critical turning point for model capabilities. This phase typically occurs at the end of pre-training, utilizing high-quality corpora under a rapidly decaying learning rate. Building upon this insight, we introduce ReMiT (Reinforcement Learning-Guided Mid-Training). Specifically, ReMiT leverages the reasoning priors of RL-tuned models to dynamically reweight tokens during the mid-training phase, prioritizing those pivotal for reasoning. Empirically, ReMiT achieves an average improvement of 3% on 10 pre-training benchmarks, spanning math, code, and general reasoning, and sustains these gains by over 2% throughout the post-training pipeline. These results validate an iterative feedback loop, enabling continuous and self-reinforcing evolution of LLMs.
💡 Research Summary
The paper introduces ReMiT (Reinforcement Learning‑Guided Mid‑Training), a novel framework that creates a bidirectional feedback loop between the pre‑training and post‑training stages of large language models (LLMs). Traditional LLM pipelines are unidirectional: a massive pre‑training phase followed by a post‑training phase such as supervised fine‑tuning (SFT), direct preference optimization (DPO), or reinforcement learning (RL). The authors observe that the “mid‑training” stage—typically occurring near the end of pre‑training on high‑quality corpora (e.g., mathematics, code, scientific text) with a rapidly decaying learning rate—acts as a critical turning point where the model’s token‑level probability distribution shifts dramatically toward that of a later RL‑tuned model.
Motivated by this observation, ReMiT reuses the RL‑tuned model that is already present in the training pipeline as a reference. For each token xₜ in the mid‑training corpus, the framework computes the loss discrepancy ΔL(xₜ) = –log pθ(xₜ|x<ₜ) + log pRL(xₜ|x<ₜ), centers it by subtracting the sequence‑wise mean μΔ, and maps the centered value bΔL = ΔL – μΔ through a scaled sigmoid function. The resulting weight wₜ = clip(2·σ(bΔL), 1–ε, 1+ε) is applied multiplicatively to the standard next‑token prediction loss, yielding a weighted loss L_ReMiT(θ) = –∑ₜ wₜ log pθ(xₜ|x<ₜ). The clipping parameter ε ensures stability by keeping weights within a narrow band around 1, so the objective reduces to ordinary maximum likelihood when the base and RL models agree.
The authors theoretically show that minimizing L_ReMiT is equivalent to minimizing the KL divergence between the model distribution πθ and an implicit target distribution q_w, which re‑weights the data distribution by wₜ. Consequently, each ReMiT update nudges the base model toward a distribution that places more probability mass on “pivotal tokens” where the RL model exhibits higher confidence. This provides a principled justification for why token‑level reweighting guided by an RL reference improves the base model’s reasoning capabilities.
Empirically, ReMiT is evaluated on the OLMo‑1B architecture. In the mid‑training stage, ReMiT achieves a 5.2 % average accuracy gain across ten widely used benchmarks and reaches baseline performance six times faster. When the same model proceeds to the RL stage, it maintains a higher verification correct rate than a baseline trained with standard mid‑training, translating into a sustained >2 % improvement throughout the post‑training pipeline. Overall, the method yields an average 3 % boost on pre‑training benchmarks covering mathematics, code, and general reasoning, and these gains persist after fine‑tuning and RL.
Key contributions include: (1) a token‑level dynamic weighting scheme that leverages an in‑pipeline RL model without requiring external teacher models; (2) identification of the mid‑training window as the optimal intervention point due to its high‑quality, reasoning‑oriented data and rapid learning‑rate decay; and (3) demonstration of a self‑reinforcing “flywheel” effect where improvements in the RL stage retroactively strengthen the base model, which in turn enables further gains in subsequent RL iterations. ReMiT thus offers a practical, scalable path toward continuous, iterative evolution of LLMs.
Comments & Academic Discussion
Loading comments...
Leave a Comment