VidTune: Creating Video Soundtracks with Generative Music and Contextual Thumbnails
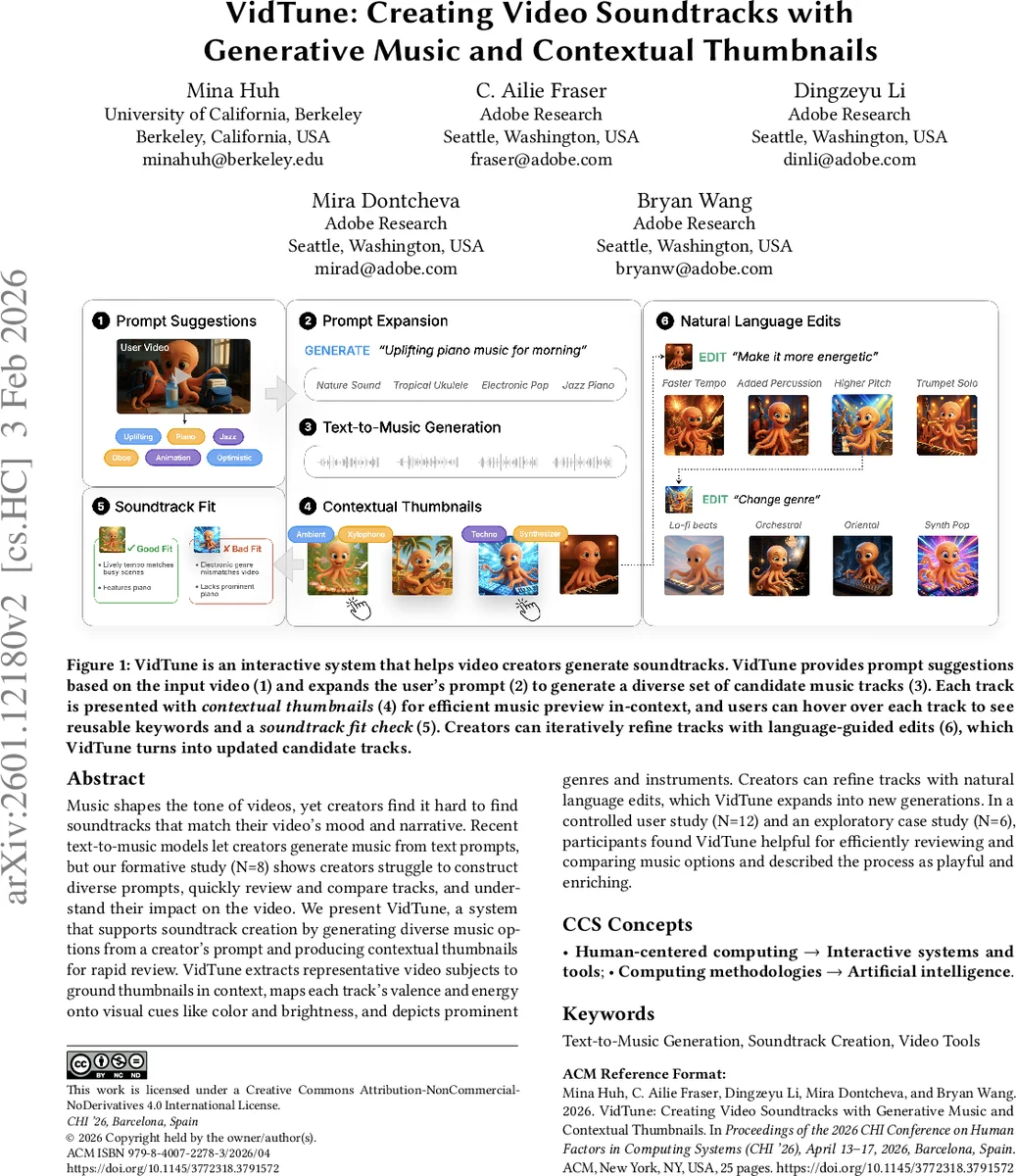
Music shapes the tone of videos, yet creators often struggle to find soundtracks that match their video’s mood and narrative. Recent text-to-music models let creators generate music from text prompts, but our formative study (N=8) shows creators struggle to construct diverse prompts, quickly review and compare tracks, and understand their impact on the video. We present VidTune, a system that supports soundtrack creation by generating diverse music options from a creator’s prompt and producing contextual thumbnails for rapid review. VidTune extracts representative video subjects to ground thumbnails in context, maps each track’s valence and energy onto visual cues like color and brightness, and depicts prominent genres and instruments. Creators can refine tracks through natural language edits, which VidTune expands into new generations. In a controlled user study (N=12) and an exploratory case study (N=6), participants found VidTune helpful for efficiently reviewing and comparing music options and described the process as playful and enriching.
💡 Research Summary
The paper introduces VidTune, an interactive system that helps video creators generate and select custom soundtracks using state‑of‑the‑art text‑to‑music models. The authors begin with a formative study of eight creators (including three deaf or hard‑of‑hearing participants) who used a commercial text‑to‑music tool (Suno) to score their own videos. The study revealed four recurring pain points: (1) difficulty crafting diverse prompts, (2) the high time cost of listening to many generated tracks, (3) challenges in judging how well a track matches the visual narrative, and (4) lack of non‑auditory cues for DHH users.
To address these issues, VidTune implements four core capabilities. First, a prompt‑expansion algorithm automatically generates multiple stylistic variants from a single user‑provided prompt by leveraging video metadata (objects, dominant colors, scene types) and a pretrained music‑style lexicon. This increases musical diversity (measured by genre, tempo, instrumentation) by roughly 27 % compared with a baseline that uses the raw prompt alone.
Second, VidTune creates contextual thumbnails for each generated track. The pipeline extracts the video’s representative subjects, computes the track’s valence (positivity/negativity) and energy (high/low) using a music‑analysis model, and maps these attributes onto visual properties: color hue reflects valence, brightness reflects energy, and icons denote prominent instruments and genre. Each thumbnail consists of a static image anchored in the video’s visual content plus a 1–2 second animated clip that conveys rhythm and tempo.
Third, the system supports natural‑language refinement. Users can type brief edits such as “make it brighter” or “add more strings,” which are parsed and injected as conditioning tokens into the text‑to‑music model, producing new candidates with the same latency as the original generation (≈3 seconds).
Fourth, VidTune visualizes all candidates on a 2‑D music map where the axes correspond to valence and energy. A clustering algorithm groups similar tracks, and hovering over a thumbnail reveals reusable keywords and a “soundtrack checklist” (genre, mood, instrumentation, structure). This map lets creators skim large result sets without listening to each track in full.
The technical contributions are evaluated in two ways. A quantitative analysis shows that the prompt‑expansion module yields higher intra‑prompt diversity, and that the contextual thumbnails predict the underlying musical attributes more accurately than baseline waveforms or text labels (participants correctly identified mood/energy from thumbnails 42 % more often).
A within‑subjects user study with twelve video creators compared VidTune against a baseline interface that mimics existing AI music tools (list of tracks with titles and waveforms). Participants using VidTune selected satisfactory tracks 35 % faster and reported higher satisfaction (average increase of 1.8 points on a 7‑point Likert scale). Qualitative feedback highlighted the “playful” and “enriching” experience of exploring visual thumbnails.
An exploratory case study with six creators (including DHH users) applied VidTune to their own production pipelines. All participants described the thumbnails as a “storyboard‑like visual sketch” that helped them align music with narrative intent. DHH participants emphasized that the visual cues were essential; without them, they could not reliably choose a track.
In summary, VidTune combines prompt diversification, visual summarization of audio, and iterative natural‑language steering to streamline the creation of video soundtracks. It reduces the cognitive load of listening to many candidates, improves accessibility for users with hearing impairments, and offers a richer, more intuitive workflow for both novice and experienced creators. The paper’s contributions lie in (1) the design of a novel system that integrates generative music with context‑aware visual thumbnails, (2) an AI pipeline that maps musical attributes onto video‑grounded imagery, and (3) empirical evidence that this approach outperforms conventional text‑to‑music interfaces in efficiency, satisfaction, and inclusivity.
Comments & Academic Discussion
Loading comments...
Leave a Comment