KVzap: Fast, Adaptive, and Faithful KV Cache Pruning
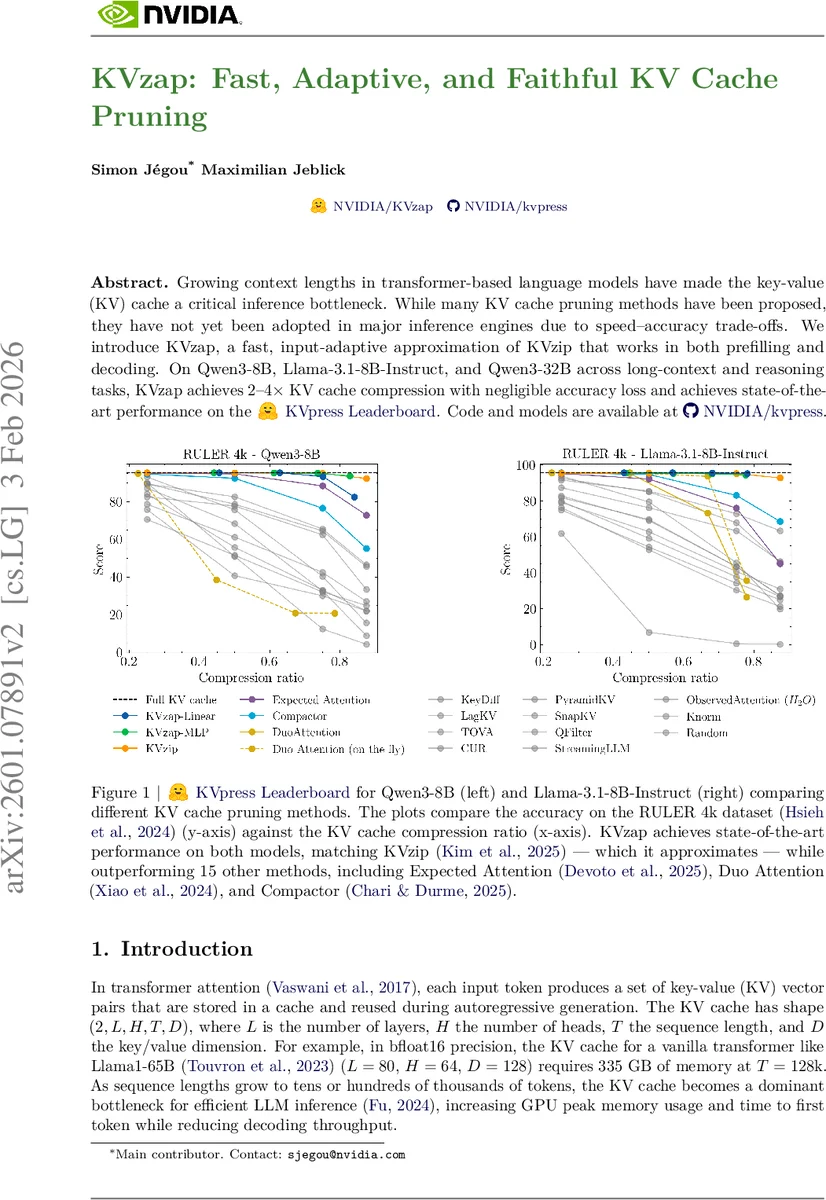
Growing context lengths in transformer-based language models have made the key-value (KV) cache a critical inference bottleneck. While many KV cache pruning methods have been proposed, they have not yet been adopted in major inference engines due to speed–accuracy trade-offs. We introduce KVzap, a fast, input-adaptive approximation of KVzip that works in both prefilling and decoding. On Qwen3-8B, Llama-3.1-8B-Instruct, and Qwen3-32B across long-context and reasoning tasks, KVzap achieves $2$–$4\times$ KV cache compression with negligible accuracy loss and achieves state-of-the-art performance on the KVpress leaderboard. Code and models are available at https://github.com/NVIDIA/kvpress.
💡 Research Summary
The paper addresses the growing memory and latency bottleneck caused by the key‑value (KV) cache in transformer‑based large language models (LLMs) during inference. While many architectural tricks (e.g., grouped‑query attention, multi‑head latent attention) compress the cache along the head, dimension, or layer axes, none effectively reduce the cache size along the sequence‑length axis (T‑axis). Existing KV‑cache pruning methods, such as KV‑zip, achieve high compression ratios but require a costly double forward pass on an extended prompt, making them unsuitable for real‑time inference and for decoding tasks that generate long outputs.
KVzap is introduced as a fast, input‑adaptive approximation of KV‑zip that works both during pre‑filling (long inputs) and decoding (reasoning tasks). The core idea is to train a lightweight surrogate model—either a single linear layer or a two‑layer MLP—that predicts the KV‑zip+ importance scores directly from the hidden states of each transformer layer. KV‑zip+ improves the original KV‑zip scoring by normalizing attention contributions with the output‑projection norm, yielding scores:
s⁺ᵢ = maxⱼ aⱼᵢ ‖W_O vᵢ‖ / ‖hⱼ‖.
The surrogate is trained on 1.2 M (hidden state, log(s⁺)) pairs sampled from a diverse pre‑training dataset (Nemotron‑Pretraining‑Dataset‑sample). Because the surrogate depends only on hidden states, inference overhead is negligible: KVzap‑MLP adds about 1.1 % of extra FLOPs, while KVzap‑Linear adds only 0.02 %. After each attention pass, the surrogate produces per‑token scores; tokens with scores below a configurable threshold τ are pruned, and the most recent w = 128 tokens are always retained via a sliding window to preserve local context.
Experiments were conducted on three models—Qwen‑3‑8B, Llama‑3.1‑8B‑Instruct, and Qwen‑3‑32B—across three benchmark suites: RULER‑4k (long‑context retrieval, multi‑hop, aggregation, QA), LongBench (multi‑document QA, summarization, few‑shot, code), and AIME25 (mathematical reasoning). Compression thresholds were varied (τ ∈ {−6,−5,−4,−3} for Qwen models, τ ∈ {−9,−8,−7,−6} for Llama). Results show that KVzap achieves 2–4× KV‑cache compression with less than 0.5 % absolute accuracy loss. On RULER‑4k, KVzap matches or exceeds the KV‑zip+ oracle and outperforms 15 competing methods. KVzap‑MLP consistently yields higher R² correlation with KV‑zip+ scores (0.71–0.77) than KVzap‑Linear, and in many cases surpasses the oracle, especially on Llama‑3.1‑Instruct where the linear model surprisingly excels despite lower correlation. Memory overhead is dominated by the quadratic attention cost in long‑context regimes, making KVzap’s extra storage negligible. During decoding, KVzap’s extra FLOPs are effectively hidden behind KV‑cache retrieval stalls, improving GPU utilization.
In summary, KVzap satisfies four practical criteria for KV‑cache pruning: (1) negligible runtime overhead, (2) applicability to both pre‑fill and decode phases, (3) compatibility with fast attention kernels (FlashAttention2, PagedAttention), and (4) faithful preservation of model accuracy. The method is open‑source (https://github.com/NVIDIA/kvpress) and ready for integration into major inference engines such as vLLM, SGLang, and TRT‑LLM, offering a scalable solution for the ever‑increasing context lengths of modern LLMs.
Comments & Academic Discussion
Loading comments...
Leave a Comment