RePack then Refine: Efficient Diffusion Transformer with Vision Foundation Model
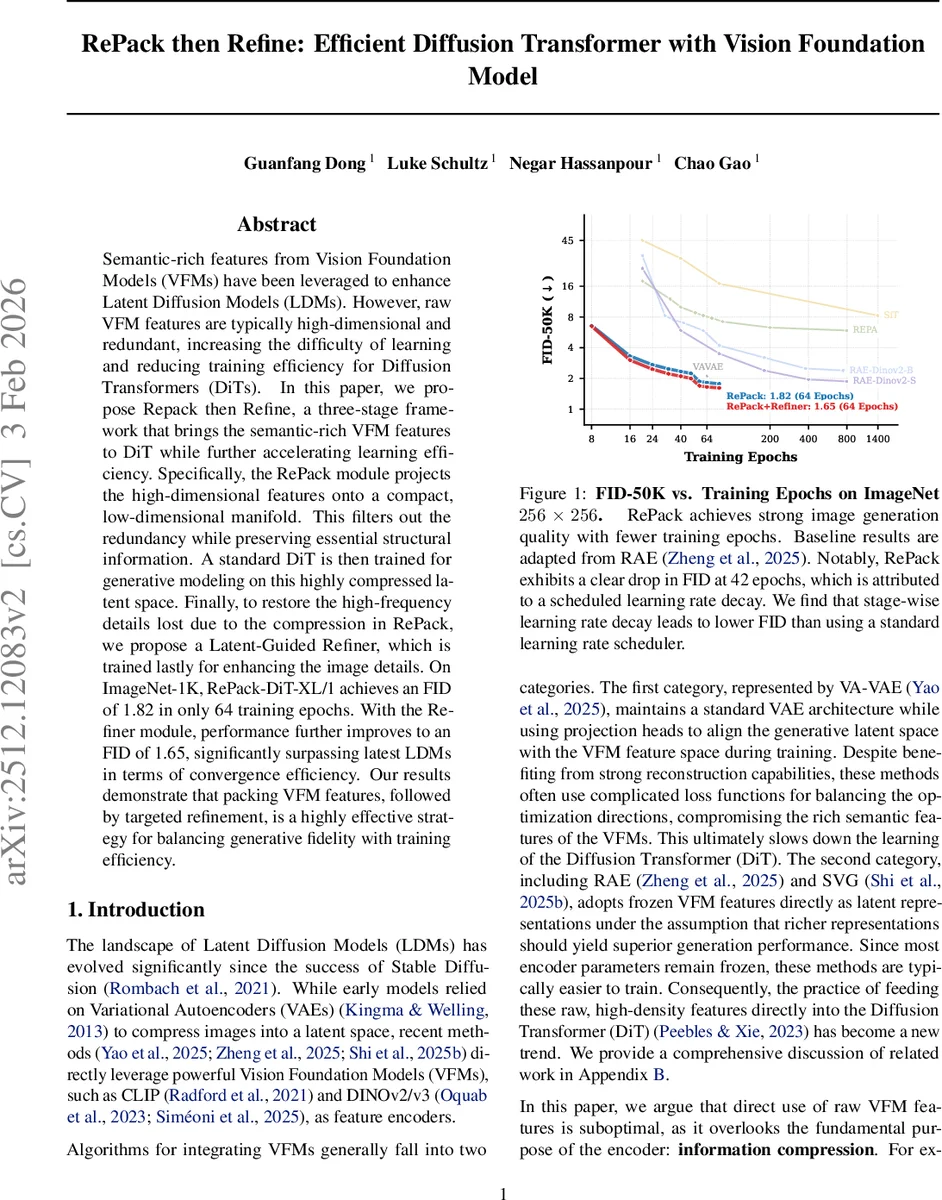
Semantic-rich features from Vision Foundation Models (VFMs) have been leveraged to enhance Latent Diffusion Models (LDMs). However, raw VFM features are typically high-dimensional and redundant, increasing the difficulty of learning and reducing training efficiency for Diffusion Transformers (DiTs). In this paper, we propose Repack then Refine, a three-stage framework that brings the semantic-rich VFM features to DiT while further accelerating learning efficiency. Specifically, the RePack module projects the high-dimensional features onto a compact, low-dimensional manifold. This filters out the redundancy while preserving essential structural information. A standard DiT is then trained for generative modeling on this highly compressed latent space. Finally, to restore the high-frequency details lost due to the compression in RePack, we propose a Latent-Guided Refiner, which is trained lastly for enhancing the image details. On ImageNet-1K, RePack-DiT-XL/1 achieves an FID of 1.82 in only 64 training epochs. With the Refiner module, performance further improves to an FID of 1.65, significantly surpassing latest LDMs in terms of convergence efficiency. Our results demonstrate that packing VFM features, followed by targeted refinement, is a highly effective strategy for balancing generative fidelity with training efficiency.
💡 Research Summary
The paper introduces a three‑stage framework called “RePack then Refine” that dramatically improves the efficiency and quality of diffusion‑based image generation when using Vision Foundation Models (VFMs) as encoders. Recent works have begun to replace trainable variational autoencoders (VAEs) in Latent Diffusion Models (LDMs) with frozen VFMs such as CLIP or DINOv2/v3, leveraging their strong semantic representations. However, raw VFM features are extremely high‑dimensional (e.g., 768 channels for DINOv3‑B/16) and contain a large amount of redundancy. The authors first quantify this redundancy by performing Principal Component Analysis (PCA) on VFM features extracted from the ImageNet‑1K validation set. The cumulative explained variance curve shows a clear elbow at around 32 dimensions, where the first 32 components capture roughly 77 % of the variance, while the remaining 700+ dimensions contribute little. This empirical finding suggests that the essential semantic information lives on a low‑dimensional manifold, and that feeding the full‑dimensional features into a Diffusion Transformer (DiT) wastes capacity and slows convergence.
To address the problem, the authors propose the RePack module, a lightweight, bias‑free linear projection (P_{\theta}) that maps the 768‑dimensional VFM feature map to a compact 32‑dimensional latent space. The projection has only 0.04 M parameters, making it negligible in terms of memory and compute. A small decoder (D_{\psi}) reconstructs an image (I_{\text{rec}}) from the compressed latent. RePack is trained end‑to‑end with a composite loss comprising L1 pixel loss, LPIPS perceptual loss, an adversarial loss, Watson loss, and a focal loss, encouraging both fidelity and perceptual realism while preserving the structural information of the original VFM representation.
With the compressed latents in hand, the second stage trains a Diffusion Transformer. The authors adopt LightningDiT, an optimized DiT variant that incorporates RMSNorm, SwiGLU, rotary positional embeddings (RoPE), and Rectified Flow for faster and more stable training. The DiT learns to predict the velocity field that transforms a standard Gaussian noise distribution into the distribution of the compressed latents, using a flow‑matching objective (mean‑squared error between predicted and target velocities). Because the latent space is already semantically compact, the DiT enjoys a smoother optimization landscape and converges far more quickly than when operating on raw VFM features.
The third stage introduces a Latent‑Guided Refiner to recover high‑frequency details that were inevitably lost during the aggressive compression. The Refiner follows a U‑Net architecture with multi‑scale skip connections. During inference, the compressed latent is bilinearly upsampled to the full image resolution and concatenated with the base reconstruction (I_{\text{rec}}); this combined tensor is fed into the Refiner, which synthesizes realistic textures and fine details. The Refiner is trained offline, separate from the DiT, using a loss that combines L1, LPIPS, and a PatchGAN adversarial term, focusing on local texture realism.
Experimental results on ImageNet‑1K (256 × 256) demonstrate the efficacy of the approach. After only 64 training epochs, the RePack‑DiT‑XL/1 model achieves an FID of 1.82, substantially better than competing methods trained for the same number of epochs (e.g., standard DiT 2.27, VAE‑based LDMs >2.2). Adding the Refiner further improves the FID to 1.65, which the authors claim is the fastest‑converging result among recent diffusion models. The table of results also shows competitive Inception Scores, sFID, and IS metrics while keeping the total parameter count comparable to baselines.
Key contributions of the paper are:
- Quantitative redundancy analysis of VFM features, establishing that a low‑dimensional subspace captures the bulk of semantic information.
- RePack, a minimal linear projection that efficiently compresses VFM features without sacrificing essential structure.
- Demonstration of accelerated diffusion training on the compressed latent space, achieving state‑of‑the‑art FID with far fewer epochs.
- Latent‑Guided Refiner, which decouples texture synthesis from semantic generation, allowing the encoder to stay lightweight while still producing high‑fidelity images.
The work underscores the importance of respecting the “information compression” principle inherent to latent diffusion: even when using powerful pretrained encoders, a deliberate compression step can dramatically reduce redundancy, speed up training, and ultimately lead to higher‑quality generation. Future directions include exploring adaptive dimensionality selection for different VFMs, extending the framework to higher resolutions, and integrating the Refiner more tightly into an end‑to‑end training pipeline.
Comments & Academic Discussion
Loading comments...
Leave a Comment