Align to Structure: Aligning Large Language Models with Structural Information
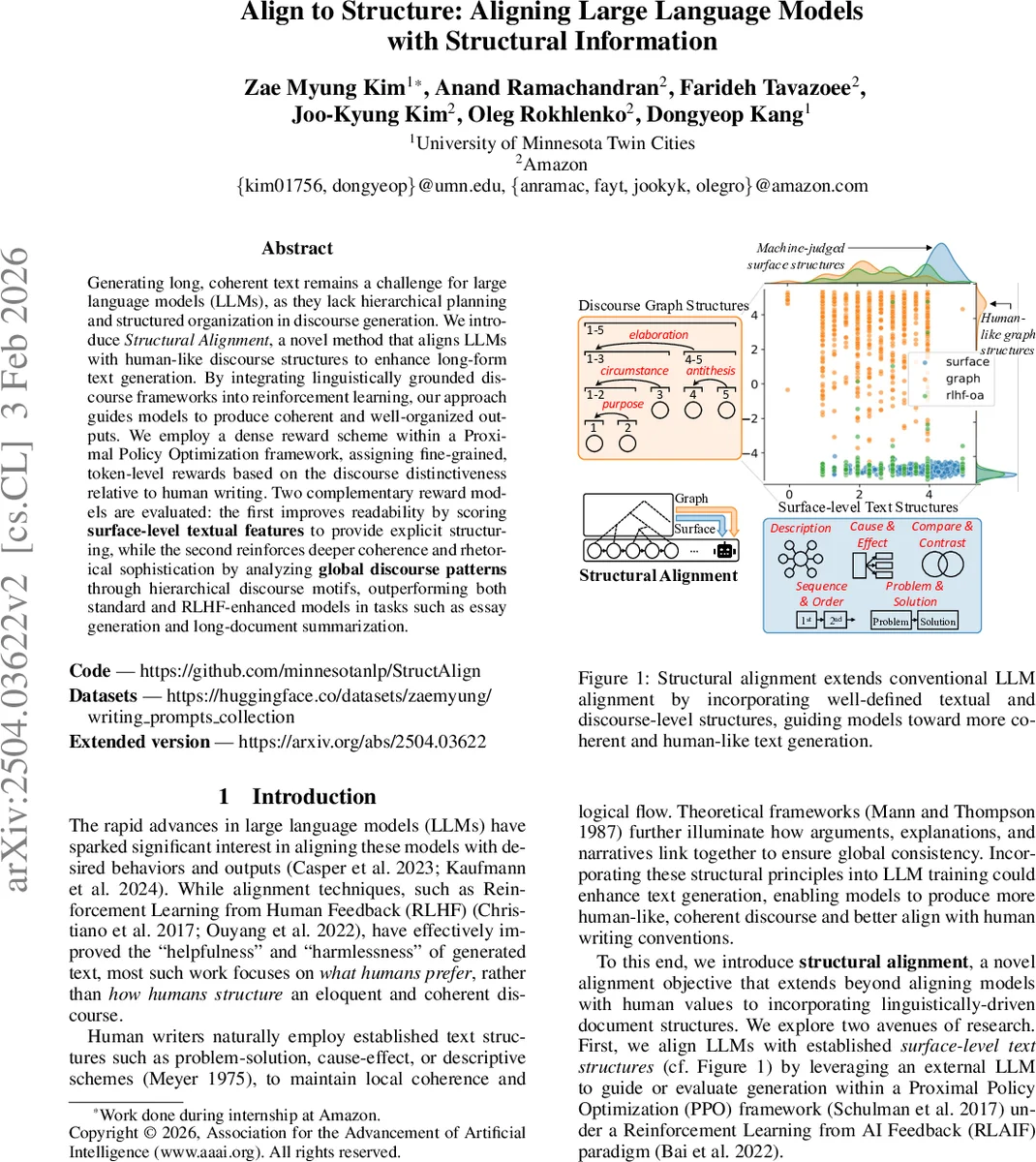
Generating long, coherent text remains a challenge for large language models (LLMs), as they lack hierarchical planning and structured organization in discourse generation. We introduce Structural Alignment, a novel method that aligns LLMs with human-like discourse structures to enhance long-form text generation. By integrating linguistically grounded discourse frameworks into reinforcement learning, our approach guides models to produce coherent and well-organized outputs. We employ a dense reward scheme within a Proximal Policy Optimization framework, assigning fine-grained, token-level rewards based on the discourse distinctiveness relative to human writing. Two complementary reward models are evaluated: the first improves readability by scoring surface-level textual features to provide explicit structuring, while the second reinforces deeper coherence and rhetorical sophistication by analyzing global discourse patterns through hierarchical discourse motifs, outperforming both standard and RLHF-enhanced models in tasks such as essay generation and long-document summarization. All training data and code will be publicly shared at https://github.com/minnesotanlp/struct_align.
💡 Research Summary
The paper tackles a persistent shortcoming of large language models (LLMs): the inability to consistently produce long, coherent, and well‑structured discourse. While existing alignment techniques such as Reinforcement Learning from Human Feedback (RLHF) or from AI Feedback (RLAIF) improve helpfulness, safety, and user preference alignment, they largely ignore the structural scaffolding that human writers employ (e.g., problem‑solution, cause‑effect, comparison‑contrast). To address this gap, the authors introduce Structural Alignment, a novel alignment objective that explicitly incorporates linguistically grounded discourse structures into the reinforcement‑learning training loop.
Core Idea
Structural Alignment consists of two complementary sources of structural information:
- Surface‑level text structures – simple, human‑readable schemas such as logical flow, hierarchical organization, and balance/emphasis. An off‑the‑shelf LLM (acting as a judge) scores each generated text on a 0‑5 scale for each of these three criteria. The average of the three scores becomes a scalar reward.
- Hierarchical discourse structures – deeper, theory‑driven representations derived from Rhetorical Structure Theory (RST). The generated document is split into ~400‑token paragraphs, each parsed into an RST tree of Elementary Discourse Units (EDUs). From these trees a hypergraph is built and discourse motifs (recurring sub‑structures) are extracted. The motif distribution is fed into a Longformer‑based authorship classifier that has been trained to distinguish human‑written from AI‑generated essays. The classifier’s binary probability (human = 1, AI = 0) is used as a second reward signal.
Reinforcement Learning Framework
Training proceeds with Proximal Policy Optimization (PPO) under the RLAIF paradigm. The reward at each timestep is a dense, token‑level shaping of the two higher‑level signals:
- An episodic reward (the average of surface scores and the authorship‑classifier probability) is applied to the whole sequence.
- Tokens that contribute to human‑distinctive discourse motifs receive an additional per‑token bonus proportional to ½ × (num tokens) for that motif. This dense shaping mitigates the usual sparsity of long‑form rewards and stabilizes PPO updates.
Implementation Details
- The surface‑level evaluator is prompted to produce three integer scores; the prompt is provided in the supplementary material.
- The RST parser (based on Liu, Shi, & Chen 2021) is extended to handle longer inputs by segmenting the text and processing non‑overlapping chunks. Motif vectors from each chunk are averaged to obtain a document‑level representation.
- The authorship classifier concatenates the motif vector with the
Comments & Academic Discussion
Loading comments...
Leave a Comment