TraceNAS: Zero-shot LLM Pruning via Gradient Trace Correlation
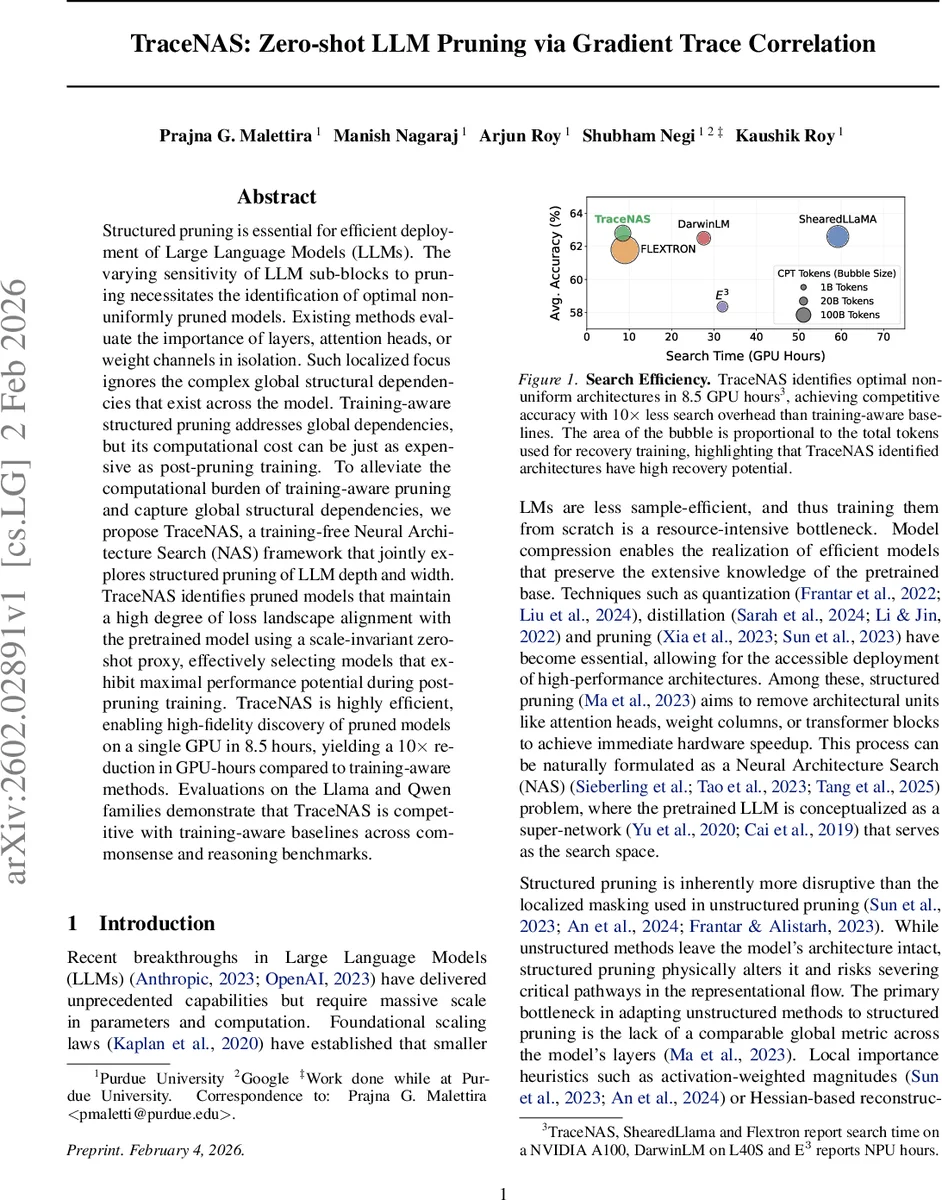
Structured pruning is essential for efficient deployment of Large Language Models (LLMs). The varying sensitivity of LLM sub-blocks to pruning necessitates the identification of optimal non-uniformly pruned models. Existing methods evaluate the importance of layers, attention heads, or weight channels in isolation. Such localized focus ignores the complex global structural dependencies that exist across the model. Training-aware structured pruning addresses global dependencies, but its computational cost can be just as expensive as post-pruning training. To alleviate the computational burden of training-aware pruning and capture global structural dependencies, we propose TraceNAS, a training-free Neural Architecture Search (NAS) framework that jointly explores structured pruning of LLM depth and width. TraceNAS identifies pruned models that maintain a high degree of loss landscape alignment with the pretrained model using a scale-invariant zero-shot proxy, effectively selecting models that exhibit maximal performance potential during post-pruning training. TraceNAS is highly efficient, enabling high-fidelity discovery of pruned models on a single GPU in 8.5 hours, yielding a 10$\times$ reduction in GPU-hours compared to training-aware methods. Evaluations on the Llama and Qwen families demonstrate that TraceNAS is competitive with training-aware baselines across commonsense and reasoning benchmarks.
💡 Research Summary
TraceNAS introduces a training‑free neural architecture search (NAS) framework for structured pruning of large language models (LLMs) that jointly optimizes depth and width. The core insight is that a well‑trained LLM resides in a broad, stable region of its loss landscape, and a pruned model that preserves the direction of gradients in this landscape is more likely to recover performance after fine‑tuning. To quantify this “functional inheritance,” the authors compute gradient traces of the pretrained base model and each candidate sub‑network within a low‑rank subspace, then evaluate the sparsity‑weighted Pearson correlation between the two traces. Because Pearson correlation is scale‑invariant, the proxy (denoted Φ) captures alignment of gradient directions regardless of magnitude changes caused by structured pruning.
The search space is defined at the sub‑block level: a binary depth mask d determines whether each transformer block is kept or bypassed, while width ratios κ specify the fraction of attention and MLP channels retained per block. Width masks are generated using an activation‑weighted saliency metric (the product of absolute weight values and the L2 norm of corresponding activations), which respects the outlier‑heavy nature of LLM weights. Candidates are realized via an in‑place masking strategy that temporarily modifies the base model’s weight matrices, allowing forward and backward passes on a small calibration set without instantiating each candidate network. This dramatically reduces memory consumption.
An evolutionary algorithm drives the search. An initial population of depth‑width configurations is randomly sampled; crossover and mutation produce new offspring, each evaluated by Φ. The top‑scoring candidates are kept for the next generation. Because the proxy requires only a single gradient pass per candidate, the entire search completes in 8.5 GPU‑hours on a single NVIDIA A100, a ten‑fold reduction compared to training‑aware methods that interleave fine‑tuning for every candidate.
Experiments on Llama (7B, 13B, 30B) and Qwen (7B, 14B) families across benchmarks such as CommonSenseQA, ARC‑Easy/Challenge, and GSM‑8K demonstrate that TraceNAS‑selected non‑uniform pruning configurations achieve comparable or slightly lower post‑pruning accuracy (within 1–2 % of the full model) while reducing parameters by 30‑50 %. The zero‑shot proxy correlates strongly with downstream performance (Spearman ρ = 0.94, Kendall τ = 0.82), confirming its predictive power. Moreover, the method requires far fewer calibration tokens and far less GPU time than training‑aware baselines like ShearedLlama, DarwinLM, or PUZZLE.
Key contributions are: (1) a scale‑invariant, gradient‑trace based zero‑shot proxy that directly measures functional inheritance; (2) a unified depth‑and‑width search space enabling heterogeneous pruning; (3) an efficient in‑place masking and low‑rank gradient computation that makes the search tractable for multi‑billion‑parameter models; and (4) empirical evidence that training‑free NAS can match or surpass the performance of expensive training‑aware pruning pipelines. TraceNAS thus opens a practical pathway for rapid, low‑cost compression of ever‑larger LLMs without sacrificing the knowledge encoded in their pretrained weights.
Comments & Academic Discussion
Loading comments...
Leave a Comment