BinaryPPO: Efficient Policy Optimization for Binary Classification
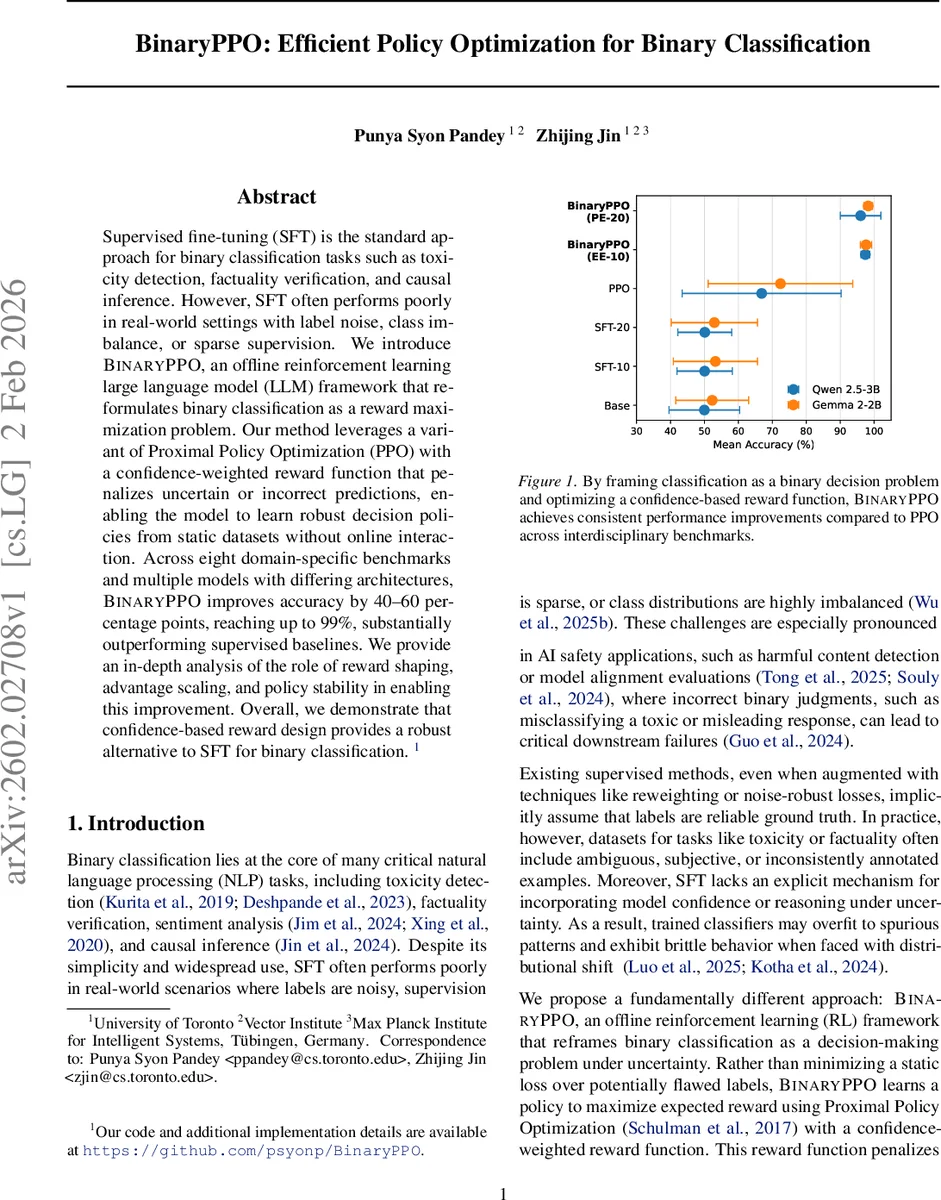
Supervised fine-tuning (SFT) is the standard approach for binary classification tasks such as toxicity detection, factuality verification, and causal inference. However, SFT often performs poorly in real-world settings with label noise, class imbalance, or sparse supervision. We introduce BinaryPPO, an offline reinforcement learning large language model (LLM) framework that reformulates binary classification as a reward maximization problem. Our method leverages a variant of Proximal Policy Optimization (PPO) with a confidence-weighted reward function that penalizes uncertain or incorrect predictions, enabling the model to learn robust decision policies from static datasets without online interaction. Across eight domain-specific benchmarks and multiple models with differing architectures, BinaryPPO improves accuracy by 40-60 percentage points, reaching up to 99%, substantially outperforming supervised baselines. We provide an in-depth analysis of the role of reward shaping, advantage scaling, and policy stability in enabling this improvement. Overall, we demonstrate that confidence-based reward design provides a robust alternative to SFT for binary classification. Our code is available at https://github.com/psyonp/BinaryPPO.
💡 Research Summary
**
BinaryPPO proposes a novel offline reinforcement‑learning framework for binary classification, addressing the well‑known shortcomings of supervised fine‑tuning (SFT) when faced with noisy labels, severe class imbalance, or sparse supervision. The authors recast the classification task as a Markov decision process: a language model policy πθ selects an action a ∈ {0, 1} for each input x, and a confidence‑weighted reward r(x,a,y)=κ·s(a,y)·log πθ_old(a|x) is assigned, where s(a,y) is +1 for correct predictions and –1 for errors, and the logarithmic term scales the reward with the model’s confidence.
The training objective combines the standard PPO clipped loss with three auxiliary terms: a value‑loss that forces a learned value network Vϕ to approximate the expected reward, a supervised cross‑entropy loss that anchors the policy to the ground‑truth labels, and an entropy regularizer that discourages over‑confident policies. The total loss L = L_PPO + α‖Vϕ‑r‖² + β·CE – γ·H(π) is minimized by alternating policy and value updates.
Experiments are conducted on two open‑source LLMs—Qwen‑2.5‑3B and Gemma‑2‑2B—across eight diverse binary benchmarks (CLadder, SciRIFF, BoolQ, FEVER, IMDB, OpenAI Moderation, Detect‑Jailbreak, JailbreakBench). Baselines include the raw pre‑trained models, SFT with 10 or 20 epochs, and a vanilla PPO implementation. BinaryPPO consistently outperforms all baselines, delivering 40–60 percentage‑point gains in accuracy and reaching up to 99.56 % on the best‑performing task. Two training schedules are explored: EE‑10 (equal allocation of 5 epochs to exploration and exploitation) and PE‑20 (pure exploration for 20 epochs). EE‑10 generally yields higher accuracy and more stable learning curves.
The paper provides an in‑depth analysis of the relationship between model confidence and post‑training accuracy, showing a monotonic increase, and demonstrates that the advantage signal peaks at intermediate confidence levels (≈0.6–0.8), indicating that moderately confident predictions generate the strongest learning signal. This behavior mitigates the classic PPO issue where overly confident or completely uncertain actions receive flat rewards, leading to stagnant updates.
While the results are impressive, several caveats remain. The reward scaling factor κ and the choice of a logarithmic shaping function are not extensively ablated, leaving open questions about sensitivity to these hyper‑parameters. The reported “40–60 %p improvement” is relative to weak baselines (often ≈30 % accuracy), so absolute gains in high‑quality datasets may be smaller. Moreover, offline RL inherently limits the diversity of actions seen during training; if the dataset does not contain enough varied predictions, the policy may still overfit to spurious patterns.
The authors release code and hyper‑parameter settings, facilitating reproducibility. Future work could explore (1) application to domains with extreme label noise or imbalance (e.g., medical diagnosis), (2) automated tuning of the confidence‑shaping function, and (3) hybrid online‑offline schemes that incorporate real‑time user feedback. Overall, BinaryPPO introduces a compelling alternative to SFT for binary decision tasks, demonstrating that confidence‑aware reward design and PPO‑style policy optimization can substantially improve robustness and accuracy in noisy, real‑world settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment