Sparsely Supervised Diffusion
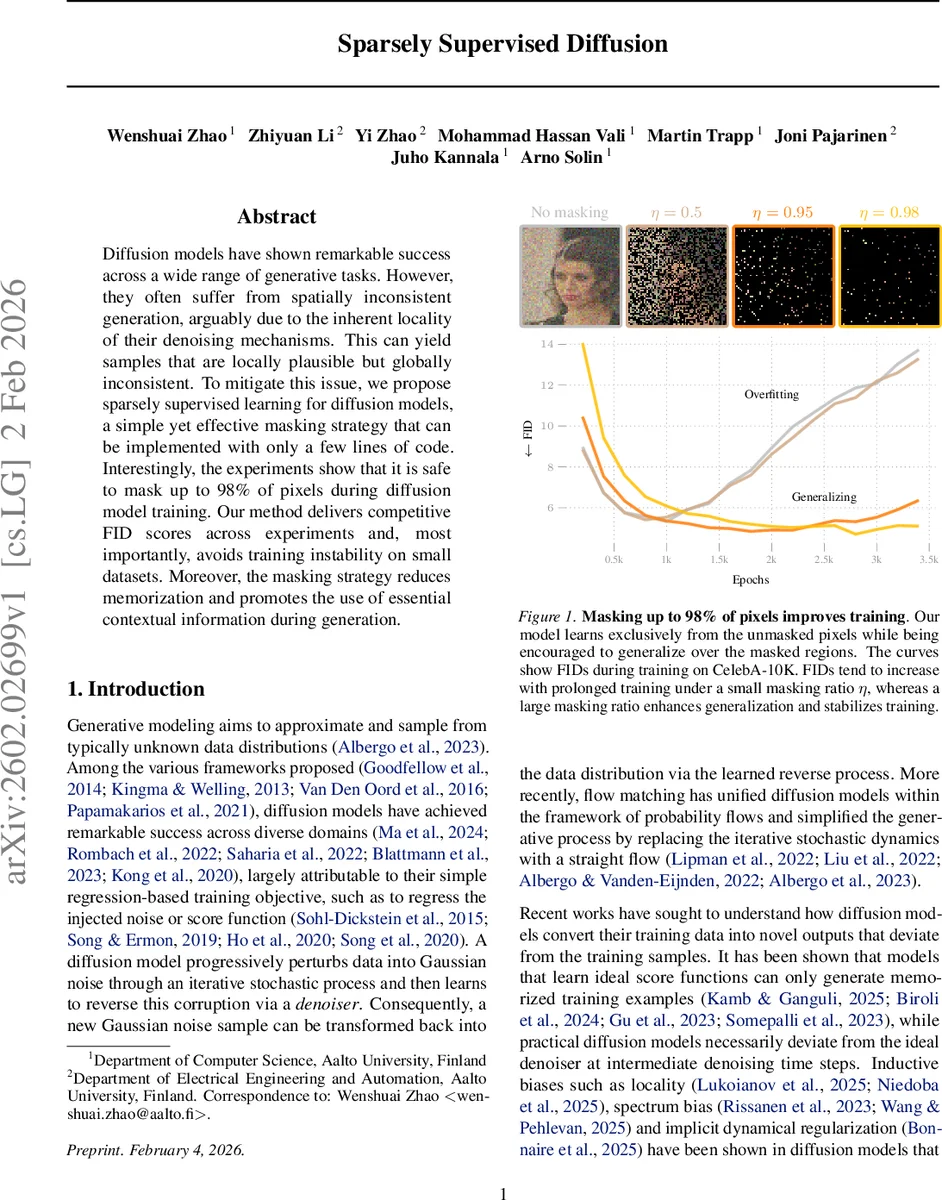
Diffusion models have shown remarkable success across a wide range of generative tasks. However, they often suffer from spatially inconsistent generation, arguably due to the inherent locality of their denoising mechanisms. This can yield samples that are locally plausible but globally inconsistent. To mitigate this issue, we propose sparsely supervised learning for diffusion models, a simple yet effective masking strategy that can be implemented with only a few lines of code. Interestingly, the experiments show that it is safe to mask up to 98% of pixels during diffusion model training. Our method delivers competitive FID scores across experiments and, most importantly, avoids training instability on small datasets. Moreover, the masking strategy reduces memorization and promotes the use of essential contextual information during generation.
💡 Research Summary
The paper introduces Sparsely Supervised Diffusion (SSD), a simple yet powerful training modification for diffusion‑based generative models that addresses the well‑known problem of spatially inconsistent generation. The core idea is to apply a random binary mask to the target image during the regression loss computation, thereby training the model only on the unmasked pixels. The mask ratio η can be set extremely high – the authors demonstrate safe training with up to 98 % of pixels masked.
From a theoretical standpoint, the authors analyze how masking changes the data covariance matrix. If Σ is the original covariance and D its diagonal, the covariance of the masked data ˜Σ becomes ˜Σ = (1‑η)² Σ + η(1‑η) D. This expression shows that masking attenuates off‑diagonal (inter‑dimensional) correlations far more than the diagonal variances, effectively regularizing the spectrum. By projecting onto the eigenvectors of Σ, they derive a scaling factor βᵢ = ˜λᵢ/λᵢ = (1‑η)² + η(1‑η)·(uᵢᵀDuᵢ)/λᵢ, which indicates that high‑frequency directions (small λᵢ) are relatively amplified while low‑frequency directions are suppressed. Consequently, the learning dynamics shift: early training focuses on robust, low‑frequency generalization, while later stages learn finer details without falling into a memorization regime.
Practically, SSD is architecture‑agnostic. It can be applied to classic denoising diffusion models (U‑Net based) as well as to flow‑matching formulations, simply by inserting the mask into the loss. No encoder‑decoder asymmetry or additional reconstruction heads are required, making the implementation a few lines of code.
Empirical evaluation spans several image datasets: CelebA‑10K (a small‑scale face dataset), CelebA‑50K, and CIFAR‑10. The authors compare baseline models (η = 0) with SSD variants at η = 0.8, 0.95, and 0.98. Key findings include:
- Training stability – With high mask ratios, the FID initially rises slightly but then plateaus at a lower level than the unmasked baseline, especially on the small CelebA‑10K set where unmasked training quickly overfits.
- Generalization and memorization – SSD dramatically reduces the tendency to memorize training images, as evidenced by stable FID curves even after many thousands of training steps.
- Spatial consistency – Visual inspection shows that SSD‑trained models produce globally coherent images; the model learns to infer missing pixels from broader context rather than relying on local neighborhoods.
- Efficiency – Masking reduces the number of loss terms per batch, leading to modest memory savings and slightly faster per‑step computation.
Overall, SSD achieves competitive FID scores comparable to or slightly better than the baseline, while offering pronounced benefits in terms of robustness on limited data, reduced memorization, and improved global image coherence.
The paper concludes by suggesting future directions such as adaptive mask schedules, exploring patch‑level masks, and extending the sparsely supervised paradigm to other generative frameworks like VAEs or GANs. SSD thus presents a low‑cost, high‑impact modification that can be readily adopted by the diffusion community to enhance both performance and reliability.
Comments & Academic Discussion
Loading comments...
Leave a Comment