Ultrafast On-chip Online Learning via Spline Locality in Kolmogorov-Arnold Networks
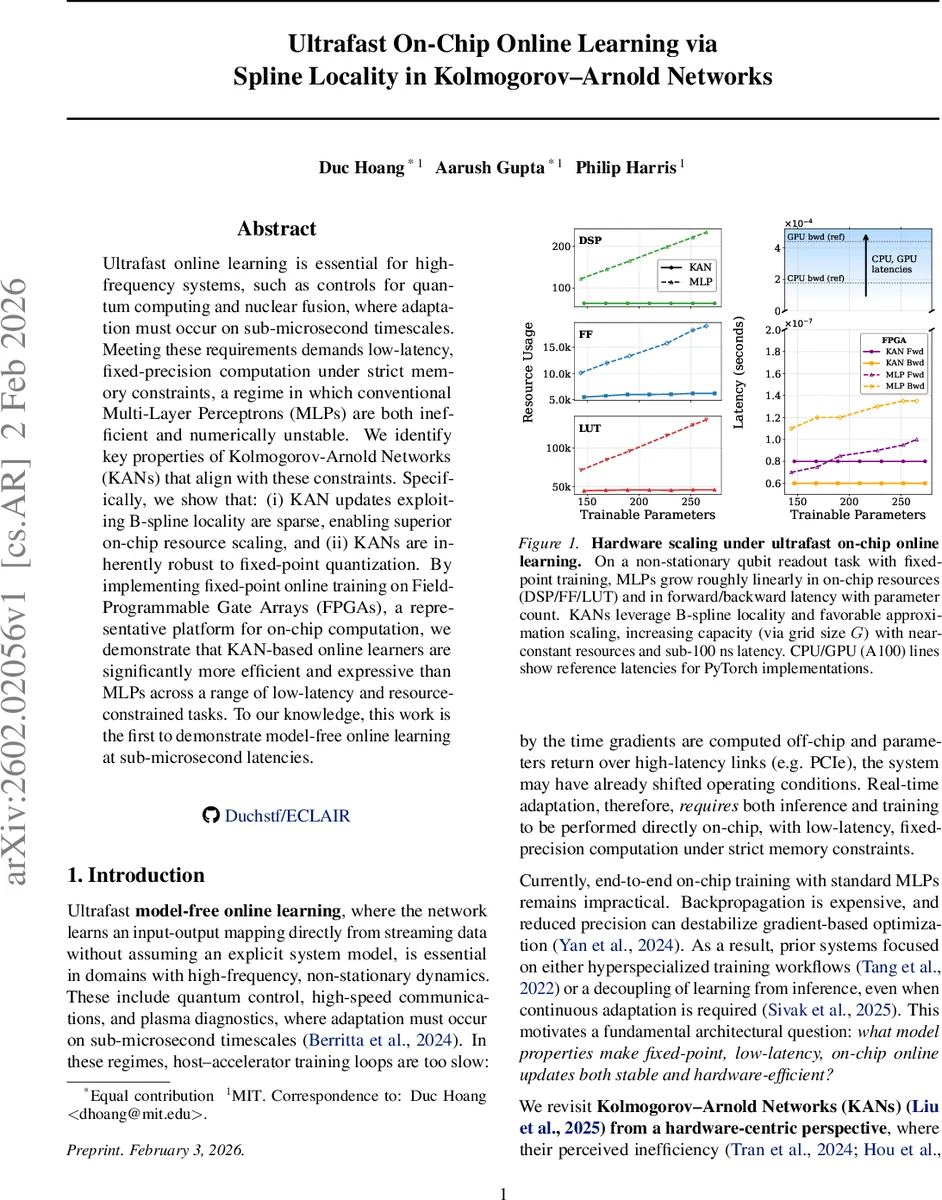
Ultrafast online learning is essential for high-frequency systems, such as controls for quantum computing and nuclear fusion, where adaptation must occur on sub-microsecond timescales. Meeting these requirements demands low-latency, fixed-precision computation under strict memory constraints, a regime in which conventional Multi-Layer Perceptrons (MLPs) are both inefficient and numerically unstable. We identify key properties of Kolmogorov-Arnold Networks (KANs) that align with these constraints. Specifically, we show that: (i) KAN updates exploiting B-spline locality are sparse, enabling superior on-chip resource scaling, and (ii) KANs are inherently robust to fixed-point quantization. By implementing fixed-point online training on Field-Programmable Gate Arrays (FPGAs), a representative platform for on-chip computation, we demonstrate that KAN-based online learners are significantly more efficient and expressive than MLPs across a range of low-latency and resource-constrained tasks. To our knowledge, this work is the first to demonstrate model-free online learning at sub-microsecond latencies.
💡 Research Summary
The paper tackles the problem of achieving sub‑microsecond online learning on resource‑constrained on‑chip hardware, a requirement for high‑frequency applications such as quantum‑computer control and nuclear‑fusion plasma diagnostics. Conventional multi‑layer perceptrons (MLPs) are ill‑suited for this regime because dense matrix‑vector multiplications and back‑propagation become prohibitively expensive in fixed‑point arithmetic, leading to numerical instability and excessive latency.
The authors revisit Kolmogorov‑Arnold Networks (KANs), whose layers consist of learnable univariate spline maps expressed as linear combinations of B‑spline basis functions. Two theoretical properties are highlighted:
-
Local Support of B‑splines – each input activates at most p + 1 basis functions (p is the spline order). Consequently, per‑sample gradient computation touches only O(p) coefficients per edge, independent of the total number of parameters N. Theorem 3.3 formalizes that the update cost for a KAN scales as s·G + s·C_update(MLP) (with s = p + 1), dramatically lower than the dense O(N) cost of an MLP.
-
Robustness to Fixed‑Point Quantization – because a KAN activation is a convex combination of learned coefficients, its output is bounded by the min/max of those coefficients (Theorem 3.4). Moreover, gradients involve the B‑spline values, which lie in
Comments & Academic Discussion
Loading comments...
Leave a Comment