Dissecting Outlier Dynamics in LLM NVFP4 Pretraining
Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with “post-QK” operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
💡 Research Summary
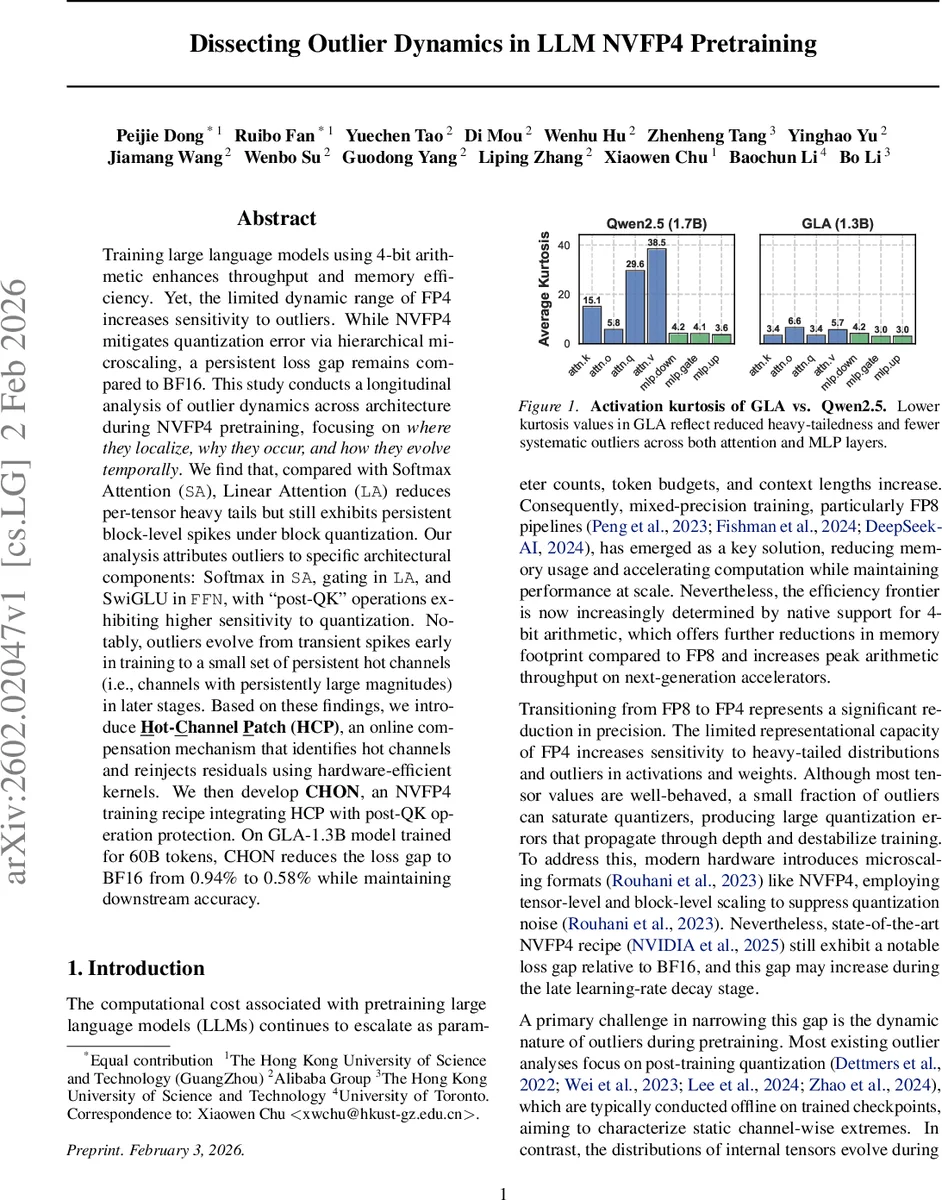
This paper investigates the outlier problem that arises when training large language models (LLMs) with NVIDIA’s 4‑bit floating‑point format (NVFP4). While 4‑bit arithmetic dramatically reduces memory usage and increases throughput, the limited dynamic range of FP4 makes the training process highly sensitive to heavy‑tailed activation distributions. The authors conduct a longitudinal study of outlier dynamics across two representative architectures: a Softmax‑based Transformer (Qwen3) and a Linear‑Attention model (GLA). They instrument the training runs to record per‑tensor and per‑block excess kurtosis, top‑k magnitudes, flush‑to‑zero rates, and quantization error metrics throughout 60 billion token training.
Where do outliers appear?
In Softmax Attention, the Softmax operation itself creates extreme pre‑softmax logits, leading to high kurtosis and large L∞ norms. The “post‑QK” stages—specifically the value projection (W_v) and the final output projection—exhibit the largest quantization errors under block‑wise NVFP4 scaling. In Linear Attention, the gating mechanism (gk‑proj) and the subsequent output projection are the primary outlier sources. Although the overall tensor‑level kurtosis is lower than in Softmax models, certain 16 × 16 blocks still contain spikes that challenge block‑quantization.
Why do outliers emerge?
Softmax forces the model to allocate near‑zero attention weights to irrelevant tokens, which requires pre‑softmax logits with a very wide dynamic range. Empirically, the authors observe decreasing post‑softmax entropy, rising pre‑softmax kurtosis, and increasing maximum logit values, confirming this mechanism. In GLA, the gating function uses an exponential with a scaling factor t > 2; to achieve both near‑zero and near‑one gating values, the input must span roughly –120 to +80, a range that cannot be faithfully represented in FP4. SwiGLU in the feed‑forward network also contributes outliers because its quadratic growth (‖x‖²) combined with weight alignment (induced by L2 regularization) concentrates large magnitudes in a few channels.
How do outliers evolve over time?
During the early phase of training (first ~5 k steps), kurtosis and top‑k magnitudes fluctuate wildly, producing transient spikes. As training progresses beyond ~10 k steps, these spikes subside and a small set of channels consistently retain large magnitudes. The authors term these “hot channels.” Hot channels are identifiable by their persistent high magnitude and low flush‑to‑zero rate, and they become the dominant source of accumulated quantization error, widening the loss gap in later stages.
Mitigation: Hot‑Channel Patch (HCP) and CHON recipe
The paper introduces Hot‑Channel Patch, a lightweight online compensation technique. Every N steps (e.g., 1 k), the top‑k channels of each tensor are identified; the residual (original FP4‑scaled value minus the quantized value) is stored in an auxiliary FP16 buffer. During the forward pass, this residual is added back to the quantized output, effectively correcting the most error‑prone channels without full‑precision recomputation. The authors prove (Theorem A.7) that HCP reduces the upper bound on mean‑squared error by more than 30 % compared with naïve NVFP4.
In addition, a sensitivity analysis shows that “post‑QK” operations are the most vulnerable to quantization error. The CHON (Compensated Hot‑channel Optimization for NVFP4) recipe therefore preserves these operations in higher precision (FP16 or FP8) while keeping the rest of the network in NVFP4. This selective precision allocation adds only a modest memory and compute overhead (≈2‑3 % extra cycles) but yields a substantial accuracy gain.
Experimental results
Applying CHON to a 1.3 B‑parameter GLA model trained for 60 B tokens reduces the loss gap relative to a BF16 baseline from 0.94 % to 0.58 %. Down‑stream benchmarks (GLUE, MMLU, code generation tasks) show less than 0.1 % degradation in accuracy. The same recipe is evaluated on supervised fine‑tuning and reinforcement‑learning‑from‑human‑feedback (RLHF) stages, where it maintains performance and mitigates gradient spikes that often occur during policy updates.
Implications
The study demonstrates that outlier behavior in ultra‑low‑precision training is not a static phenomenon; it varies with architecture, specific operation stages, and training progress. Simple block‑wise scaling is insufficient; a dynamic, hierarchical mitigation strategy is required. Hot‑channel detection and correction provide a hardware‑friendly way to address persistent outliers without costly recomputation, suggesting a viable path toward practical 4‑bit LLM training at scale.
Overall, the paper offers a comprehensive diagnosis of NVFP4‑induced outliers, a principled analysis of their origins, and an effective, low‑overhead solution that narrows the performance gap between 4‑bit and higher‑precision training.
Comments & Academic Discussion
Loading comments...
Leave a Comment