Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models
The agency expected of Agentic Large Language Models goes beyond answering correctly, requiring autonomy to set goals and decide what to explore. We term this investigatory intelligence, distinguishing it from executional intelligence, which merely completes assigned tasks. Data Science provides a natural testbed, as real-world analysis starts from raw data rather than explicit queries, yet few benchmarks focus on it. To address this, we introduce Deep Data Research (DDR), an open-ended task where LLMs autonomously extract key insights from databases, and DDR-Bench, a large-scale, checklist-based benchmark that enables verifiable evaluation. Results show that while frontier models display emerging agency, long-horizon exploration remains challenging. Our analysis highlights that effective investigatory intelligence depends not only on agent scaffolding or merely scaling, but also on intrinsic strategies of agentic models.
💡 Research Summary
The paper introduces a novel evaluation paradigm for “agentic” large language models (LLMs) that goes beyond the traditional question‑answering setting. The authors define “investigatory intelligence” as the ability of a model to autonomously set goals, explore data, generate and test hypotheses, and decide when to stop, in contrast to “executional intelligence,” which merely executes a given task. To isolate and measure this capability, they propose the Deep Data Research (DDR) task: given only a structured database and a minimal toolset (SQL and Python), an LLM must explore the data without any pre‑specified question, produce insights, and terminate on its own.
To enable large‑scale, objective evaluation, the authors build DDR‑Bench, a checklist‑based benchmark that instantiates DDR over three real‑world scenarios: (1) MIMIC‑IV electronic health records, (2) GLOBEM sport‑and‑exercise psychology data (wearable sensor streams plus survey responses), and (3) a 10‑K corporate financial reporting dataset. Each scenario contains both structured tables and unstructured text (clinical notes, survey comments, financial footnotes). From the unstructured portions, a factual checklist is automatically derived; this checklist serves as the ground‑truth against which the model‑generated insights are verified. The benchmark is deliberately minimal: no explicit query or objective is provided, the agent framework follows a lightweight ReAct (Reason‑Act‑Observe) loop, and there is no upper bound on interaction turns—termination is left entirely to the model.
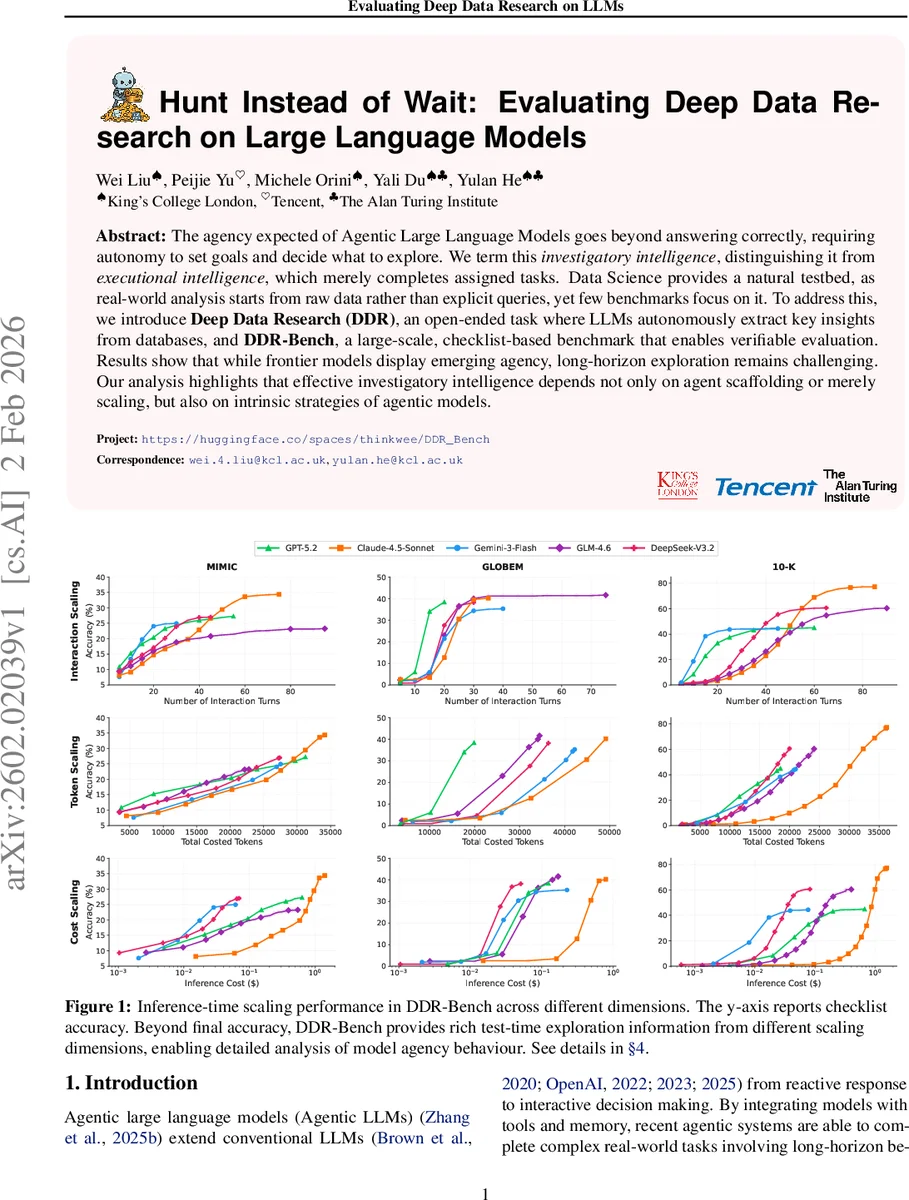
The authors evaluate several state‑of‑the‑art LLMs—including GPT‑4, Claude‑Sonnet 4.5, Gemini‑Flash, GLM‑4.6, and DeepSeek‑V3.2—under identical DDR‑Bench conditions. Results show that average checklist accuracy ranges only between 30 % and 45 %, far below human expert performance. Accuracy improves with the number of interaction turns initially, but plateaus or even declines after roughly 20–30 turns, indicating that long‑horizon reasoning suffers from error accumulation and inefficient tool usage. Token consumption and inference cost rise sharply with longer trajectories, revealing poor cost‑effectiveness. Behavioral analysis uncovers distinct patterns: some models quickly learn the database schema and focus on high‑value tables, yet later stages exhibit repetitive or random SQL queries, redundant data retrieval, and a lack of systematic hypothesis testing.
The authors argue that these shortcomings are not merely a matter of model size or parameter count; rather, they stem from missing “intrinsic investigatory strategies.” Current models lack meta‑cognitive mechanisms to recognize information gaps, quantify uncertainty, and dynamically re‑prioritize goals during exploration. To bridge this gap, the paper suggests (a) augmenting LLMs with robust long‑term memory and planning modules, (b) introducing explicit metrics for termination decisions, and (c) integrating checklist‑style feedback into the training loop to teach models how to self‑evaluate factual claims.
DDR‑Bench itself is designed for extensibility: new domains (e.g., finance, manufacturing) and additional tools (graph queries, time‑series analysis) can be incorporated with minimal effort, providing a standardized testbed for future research on autonomous data‑analysis agents.
In summary, the work defines a new dimension of LLM capability—investigatory intelligence—formalizes it through the DDR task, and supplies a scalable, objective benchmark (DDR‑Bench) to measure it. Empirical findings reveal that even the most advanced LLMs display only nascent agency, struggling with long‑horizon, error‑free exploration and strategic goal setting. The paper highlights the need for architectural and training advances that embed genuine investigative reasoning into LLMs, paving the way toward truly autonomous AI analysts.
Comments & Academic Discussion
Loading comments...
Leave a Comment