Position: The Need for Ultrafast Training
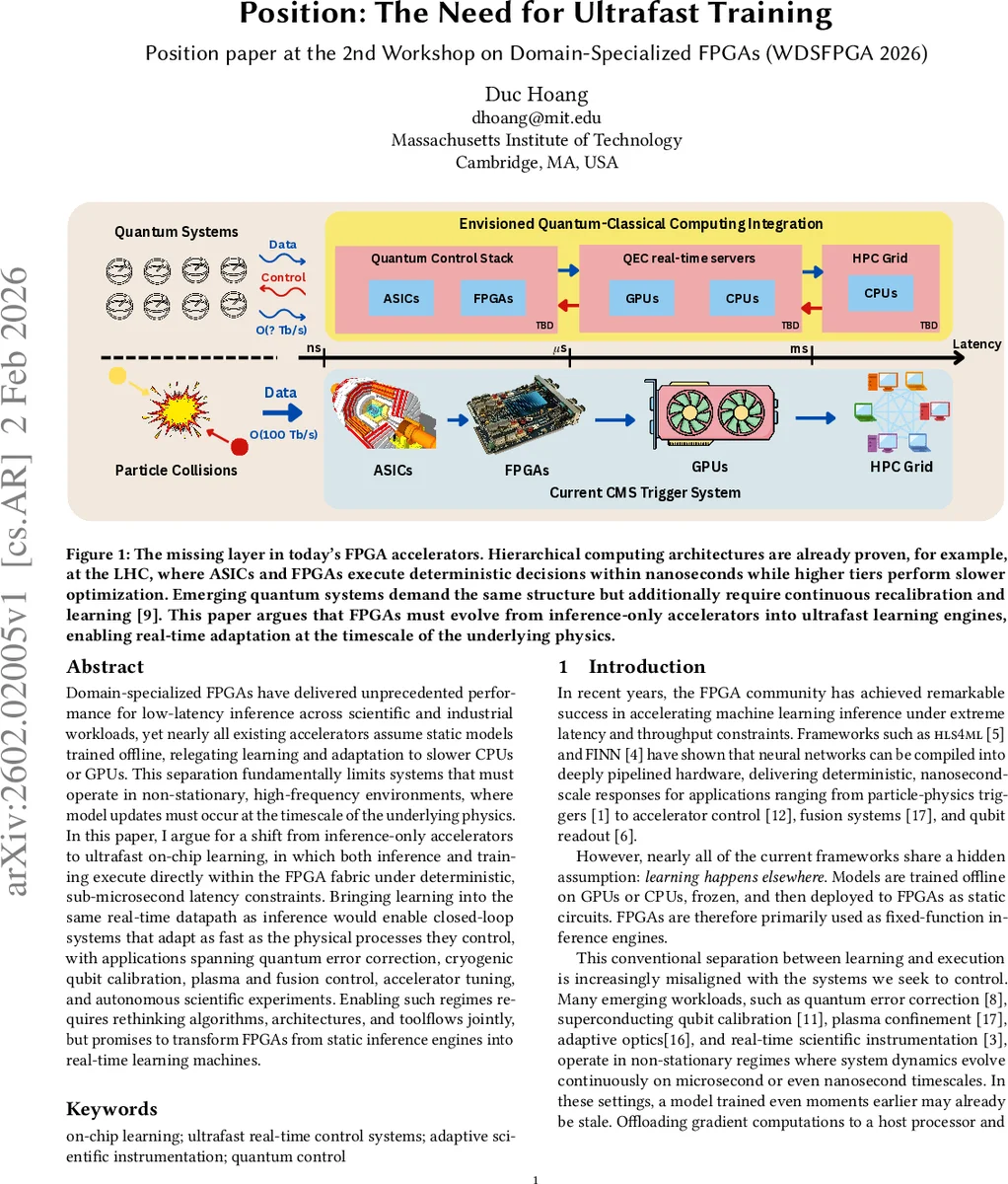
Domain-specialized FPGAs have delivered unprecedented performance for low-latency inference across scientific and industrial workloads, yet nearly all existing accelerators assume static models trained offline, relegating learning and adaptation to slower CPUs or GPUs. This separation fundamentally limits systems that must operate in non-stationary, high-frequency environments, where model updates must occur at the timescale of the underlying physics. In this paper, I argue for a shift from inference-only accelerators to ultrafast on-chip learning, in which both inference and training execute directly within the FPGA fabric under deterministic, sub-microsecond latency constraints. Bringing learning into the same real-time datapath as inference would enable closed-loop systems that adapt as fast as the physical processes they control, with applications spanning quantum error correction, cryogenic qubit calibration, plasma and fusion control, accelerator tuning, and autonomous scientific experiments. Enabling such regimes requires rethinking algorithms, architectures, and toolflows jointly, but promises to transform FPGAs from static inference engines into real-time learning machines.
💡 Research Summary
The paper presents a position that current FPGA‑based machine‑learning accelerators are fundamentally limited by their reliance on static, offline‑trained models. While frameworks such as hls4ml and FINN have demonstrated deterministic, nanosecond‑scale inference for particle‑physics triggers, accelerator control, fusion diagnostics, and qubit readout, they all share the hidden assumption that learning occurs elsewhere—on CPUs or GPUs—before the model is frozen and deployed to the FPGA fabric. This separation becomes a critical bottleneck for emerging scientific and industrial workloads that operate in non‑stationary, high‑frequency environments where the underlying physics evolves on microsecond or even nanosecond time scales. In such regimes, a model trained a few milliseconds earlier may already be obsolete, and the latency of transferring data to a host, performing gradient calculations, and sending updated parameters back exceeds the control‑loop budget, breaking closed‑loop stability.
The author argues for a paradigm shift: ultrafast on‑chip learning, where inference, gradient computation, and parameter updates all execute directly within the FPGA under deterministic sub‑microsecond latency constraints. By collapsing the boundary between learning and execution, FPGA‑based controllers could adapt as fast as the physical processes they regulate, enabling real‑time quantum error correction, cryogenic qubit calibration, plasma confinement, adaptive optics, high‑frequency trading, and autonomous scientific experiments.
The paper identifies four technical challenges that make on‑chip learning substantially harder than inference:
- Deterministic ultra‑low latency – Training must not introduce jitter; every pipeline stage (forward pass, back‑propagation, weight update) must complete within a fixed number of clock cycles.
- Memory bandwidth and capacity – Storing activations, gradients, and optimizer state competes with limited BRAM/URAM resources and port bandwidth, especially in streaming or small‑batch regimes.
- Fixed‑point numerical stability – Gradient updates are highly sensitive to quantization, saturation, and limited dynamic range; naïve fixed‑point back‑propagation can diverge.
- Tool‑chain limitations – Existing HLS and synthesis flows (e.g., FINN, hls4ml) are optimized for static forward graphs. They lack native support for stateful designs, continuous parameter mutation, and worst‑case timing guarantees required for learning.
To address these challenges, the author outlines a speculative research agenda:
- Algorithms – Systematically characterize model families that are amenable to efficient on‑chip training (sparse, structured, binary/ternary networks). Develop streaming‑compatible optimizers (e.g., quantization‑aware SGD, RLS) and define benchmarks that measure trainability under hard real‑time constraints (latency, memory footprint, precision).
- Architectures – Propose FPGA‑level primitives such as sparse update engines, gradient‑accumulation buffers, dual‑port parameter memories, and non‑blocking weight‑swap mechanisms that preserve inference determinism while learning proceeds. Consider blurring the line between “inference fabric” and “training fabric.”
- CAD tools – Extend HLS to support stateful pipelines with explicit timing budgets, automatic scaling of fixed‑point representations, and verification of numerical drift over long‑running training loops. Provide synthesis options that co‑optimize compute, memory, and control paths for worst‑case latency.
A concrete “quantum gap” case study illustrates the potential impact: semiconductor quantum‑dot qubits suffer from low‑frequency charge noise that shifts Coulomb peaks on sub‑microsecond time scales. Current calibration loops are host‑driven, interrupting operation and scaling poorly. By embedding a reinforcement‑learning‑style controller with a fixed‑precision function approximator directly on the FPGA, calibration cycles could run at ≤1 µs, well below typical silicon qubit decoherence times (~10 µs), effectively averaging out slow noise while reacting to faster disturbances, potentially extending coherence by orders of magnitude.
The broader impact section enumerates transformative applications: autonomous self‑tuning scientific instruments (particle detectors, telescopes, medical imagers), real‑time adaptive control for plasma confinement and high‑frequency trading, and continuous quantum‑system stabilization. The author emphasizes that achieving ultrafast on‑chip learning will require joint progress across algorithmic robustness, hardware primitives, and tool‑flow support. If realized, FPGAs would evolve from static inference engines into real‑time learning machines, unlocking adaptive systems that can keep pace with the fastest physical dynamics.
Comments & Academic Discussion
Loading comments...
Leave a Comment