IntraSlice: Towards High-Performance Structural Pruning with Block-Intra PCA for LLMs
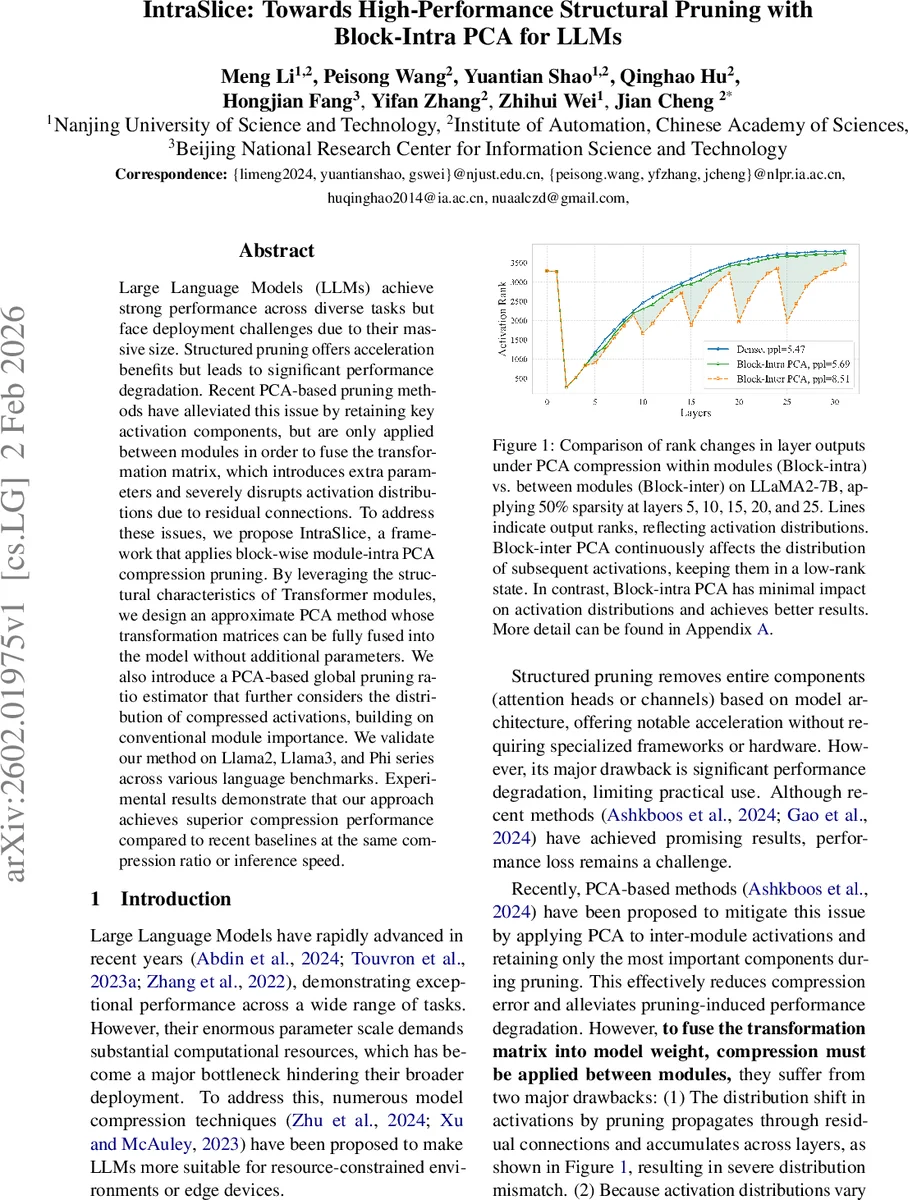
Large Language Models (LLMs) achieve strong performance across diverse tasks but face deployment challenges due to their massive size. Structured pruning offers acceleration benefits but leads to significant performance degradation. Recent PCA-based pruning methods have alleviated this issue by retaining key activation components, but are only applied between modules in order to fuse the transformation matrix, which introduces extra parameters and severely disrupts activation distributions due to residual connections. To address these issues, we propose IntraSlice, a framework that applies block-wise module-intra PCA compression pruning. By leveraging the structural characteristics of Transformer modules, we design an approximate PCA method whose transformation matrices can be fully fused into the model without additional parameters. We also introduce a PCA-based global pruning ratio estimator that further considers the distribution of compressed activations, building on conventional module importance. We validate our method on Llama2, Llama3, and Phi series across various language benchmarks. Experimental results demonstrate that our approach achieves superior compression performance compared to recent baselines at the same compression ratio or inference speed.
💡 Research Summary
IntraSlice addresses the pressing need to deploy large language models (LLMs) on resource‑constrained hardware by introducing a novel intra‑module structured pruning framework that leverages block‑wise Principal Component Analysis (PCA). Existing structured pruning methods either remove entire heads or channels, which yields hardware‑friendly speedups but often incurs severe performance loss due to the non‑linear nature of transformer components and the residual connections that propagate distribution shifts across layers. Recent PCA‑based approaches (e.g., SliceGPT) mitigate this by compressing inter‑module activations and retaining the most informative components, yet they must keep the PCA transformation matrix separate from the model weights. This introduces extra parameters, requires online computation in the residual path, and still disrupts activation statistics because the compression is applied between modules.
IntraSlice fundamentally changes the pruning granularity: it performs PCA compression inside each transformer module, specifically within the Multi‑Head Attention (MHA) and Feed‑Forward Network (FFN) blocks. By exploiting the structural characteristics of these modules, the authors design two complementary techniques that enable the PCA transformation matrices to be fully fused into the original weight tensors, eliminating any additional parameters or runtime overhead.
Adaptive Head Compression with Block‑PCA (MHA)
- Each attention head’s importance is quantified by a channel‑wise score that multiplies the Frobenius norm of the head’s activation slice with the norm of its corresponding weight slice.
- A reconstruction score for a head under a given compression rank is derived from the eigenvalues of the head’s activation covariance (or Hessian) matrix, reflecting how much variance is retained after keeping the top‑p principal components.
- Heads are greedily pruned based on the lowest reconstruction scores. The remaining heads share the target compression dimensionality, and each head receives a block‑diagonal PCA matrix.
- Crucially, the query‑key PCA matrix (Q₁) is merged directly into the query and key projection weights, while the value‑output PCA matrix (Q₂) is constructed as a dense block‑wise matrix that can be fused into the output weight. This full fusion eliminates the need for any extra computation in the residual branch. For models using Rotary Position Embedding, Q₁ is simplified to a pairwise channel‑selection matrix with negligible impact on compression quality.
Progressive Sliced Iterative PCA (FFN)
- FFNs contain non‑linear activation functions (e.g., GELU) that prevent straightforward linear compression. Traditional iterative PCA would require repeatedly loading the full activation tensor, which is prohibitive for billions of parameters.
- The authors propose slicing the activation data along the feature dimension into smaller blocks. For each slice, a local PCA optimization updates a portion of the compression matrix Q_c while accumulating contributions from previously processed slices (the cumulative term C).
- After each slice update, the reconstruction matrix Q_r is recomputed analytically using a regularized least‑squares formula. The process iterates a few times, but is only invoked for layers with relatively high pruning ratios (≈10 % of layers), keeping overall overhead low.
- This sliced approach dramatically reduces memory traffic and enables effective compression of highly non‑linear FFN layers without sacrificing reconstruction fidelity.
Global Non‑Uniform Pruning Ratio Estimation
- The framework augments mask‑based importance metrics (as used in SoBP) with a PCA‑aware simulation of post‑compression activation distributions. By estimating how the rank of compressed activations changes after applying the intra‑module PCA, the method adjusts pruning ratios per block to balance importance and distribution shift.
- This yields a data‑driven, non‑uniform sparsity schedule that outperforms uniform pruning and recent global‑search methods such as OWL, BESA, and Týr‑the‑Prune.
Experimental Validation
- The authors evaluate IntraSlice on Llama2‑7B, Llama3‑8B, and the Phi series across a suite of language benchmarks (e.g., zero‑shot QA, summarization, and reasoning tasks).
- Compression ratios ranging from 30 % to 50 % are applied. In every setting, IntraSlice achieves lower perplexity and higher task‑specific accuracy than baselines including SliceGPT, SP³, DISP‑LLM, and coarse‑grained layer pruning.
- Ablation studies confirm that intra‑module (block‑intra) PCA preserves activation rank far better than inter‑module (block‑inter) PCA, leading to reduced error accumulation through residual connections.
- Runtime measurements show that because all PCA matrices are fused into the original weights, inference speedups match those of conventional structured pruning without the extra latency of on‑the‑fly matrix multiplications.
Key Contributions
- Introduction of a block‑intra PCA framework that handles the non‑linearity of transformer modules and enables full weight fusion without extra parameters.
- Development of Adaptive Head Compression and Progressive Sliced Iterative PCA to address MHA and FFN specific challenges.
- A PCA‑aware global pruning ratio estimator that jointly considers traditional importance scores and the impact of compression on activation distributions.
- Comprehensive empirical evidence that the method consistently outperforms state‑of‑the‑art structured pruning techniques across multiple LLM families and tasks.
In summary, IntraSlice offers a practical, high‑performance pathway to compress large language models by moving PCA‑based compression inside transformer modules, thereby preserving activation statistics, eliminating additional runtime overhead, and delivering superior accuracy‑speed trade‑offs. This work paves the way for more efficient LLM deployment in real‑world applications where latency and memory constraints are critical.
Comments & Academic Discussion
Loading comments...
Leave a Comment