Efficient Epistemic Uncertainty Estimation for Large Language Models via Knowledge Distillation
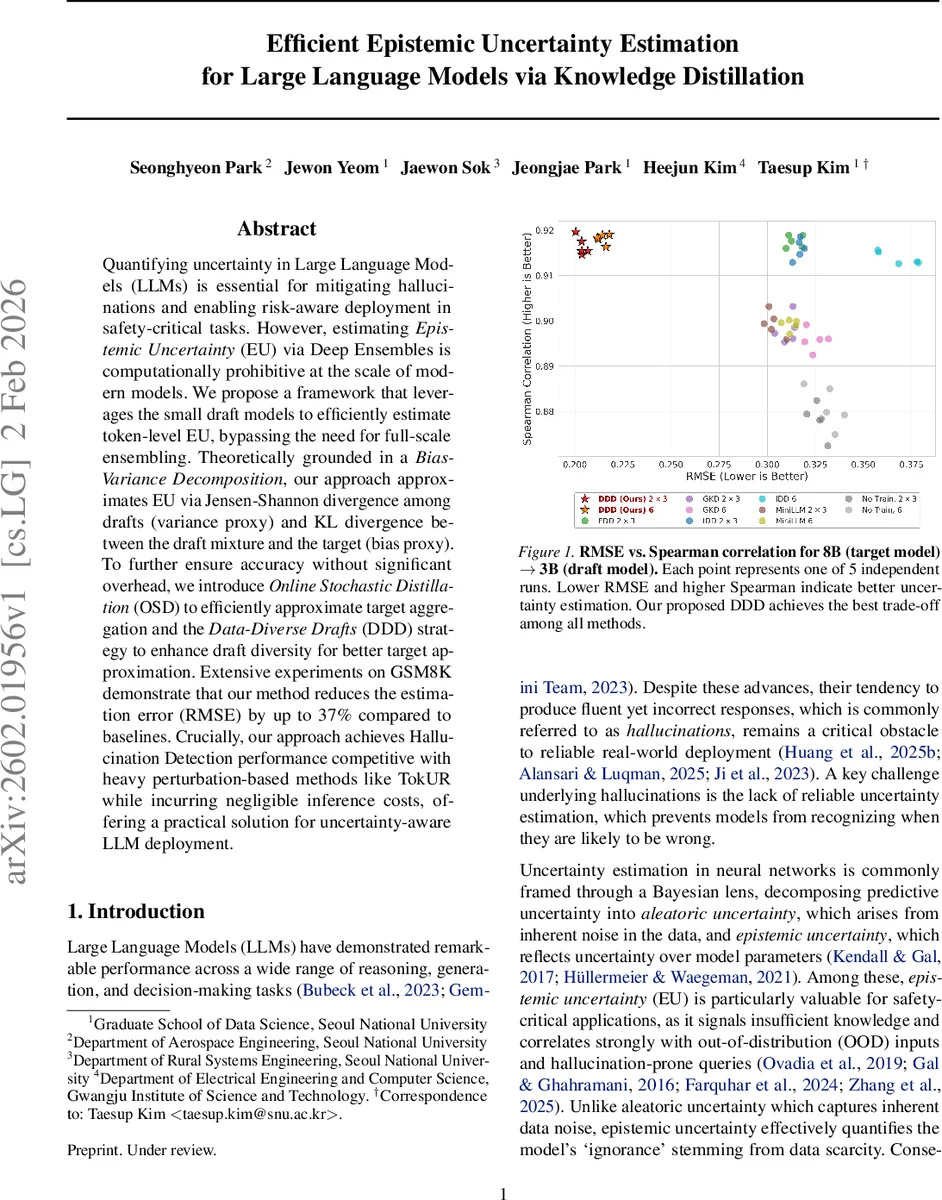
Quantifying uncertainty in Large Language Models (LLMs) is essential for mitigating hallucinations and enabling risk-aware deployment in safety-critical tasks. However, estimating Epistemic Uncertainty(EU) via Deep Ensembles is computationally prohibitive at the scale of modern models. We propose a framework that leverages the small draft models to efficiently estimate token-level EU, bypassing the need for full-scale ensembling. Theoretically grounded in a Bias-Variance Decomposition, our approach approximates EU via Jensen-Shannon divergence among drafts (variance proxy) and KL divergence between the draft mixture and the target (bias proxy). To further ensure accuracy without significant overhead, we introduce Online Stochastic Distillation (OSD) to efficiently approximate target aggregation and the Data-Diverse Drafts (DDD) strategy to enhance draft diversity for better target approximation. Extensive experiments on GSM8K demonstrate that our method reduces the estimation error (RMSE) by up to 37% compared to baselines. Crucially, our approach achieves Hallucination Detection performance competitive with heavy perturbation-based methods like TokUR while incurring negligible inference costs, offering a practical solution for uncertainty-aware LLM deployment.
💡 Research Summary
**
The paper tackles the problem of estimating epistemic uncertainty (EU) for large language models (LLMs) without incurring the prohibitive cost of deep ensembles. The authors observe that modern speculative decoding pipelines already employ multiple lightweight “draft” models that generate candidate tokens for a much larger target model. They reinterpret these drafts as a finite set of approximate posterior samples of the target model and develop a principled framework to estimate EU using only the drafts.
The theoretical contribution begins by recalling the Bayesian definition of EU as the mutual information between model parameters θ and output y, which can be expressed as the expected KL divergence between each parameter‑specific predictive distribution pθ and the Bayesian model average p_T. Direct computation would require many forward passes of the full‑size model. To avoid this, the authors introduce a draft mixture distribution q_mix (the uniform average of K draft models q_k). They prove that the expected KL(pθ‖q_mix) equals EU plus an extra KL(p_T‖q_mix) term, establishing an upper bound: any divergence measured against the draft mixture overestimates true EU unless the mixture perfectly matches the target average.
Next, they make a “proxy posterior” assumption: the expectation over the true posterior can be approximated by a uniform expectation over the discrete set of drafts. Under this assumption, they derive a bias‑variance decomposition of the proxy EU estimator:
E_k
Comments & Academic Discussion
Loading comments...
Leave a Comment