FUPareto: Bridging the Forgetting-Utility Gap in Federated Unlearning via Pareto Augmented Optimization
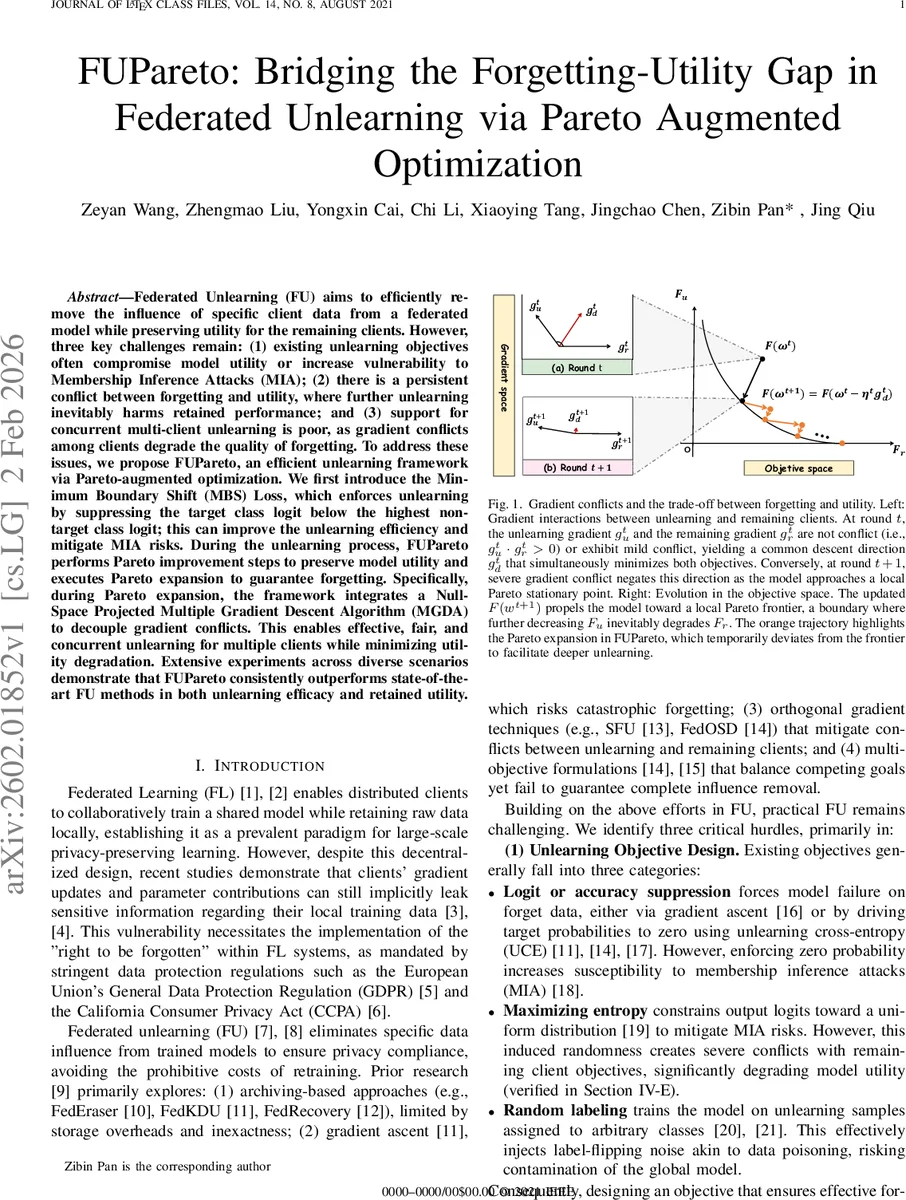
Federated Unlearning (FU) aims to efficiently remove the influence of specific client data from a federated model while preserving utility for the remaining clients. However, three key challenges remain: (1) existing unlearning objectives often compromise model utility or increase vulnerability to Membership Inference Attacks (MIA); (2) there is a persistent conflict between forgetting and utility, where further unlearning inevitably harms retained performance; and (3) support for concurrent multi-client unlearning is poor, as gradient conflicts among clients degrade the quality of forgetting. To address these issues, we propose FUPareto, an efficient unlearning framework via Pareto-augmented optimization. We first introduce the Minimum Boundary Shift (MBS) Loss, which enforces unlearning by suppressing the target class logit below the highest non-target class logit; this can improve the unlearning efficiency and mitigate MIA risks. During the unlearning process, FUPareto performs Pareto improvement steps to preserve model utility and executes Pareto expansion to guarantee forgetting. Specifically, during Pareto expansion, the framework integrates a Null-Space Projected Multiple Gradient Descent Algorithm (MGDA) to decouple gradient conflicts. This enables effective, fair, and concurrent unlearning for multiple clients while minimizing utility degradation. Extensive experiments across diverse scenarios demonstrate that FUPareto consistently outperforms state-of-the-art FU methods in both unlearning efficacy and retained utility.
💡 Research Summary
Federated Unlearning (FU) seeks to erase the influence of specific client data from a globally trained model without the cost of full retraining, a requirement driven by privacy regulations such as GDPR and CCPA. Existing FU approaches fall into four categories: (1) archival methods that replay stored updates but suffer from high storage overhead and inexactness; (2) gradient‑ascent or unlearning cross‑entropy losses that push target class probabilities toward zero, which creates extreme output distributions and makes the model vulnerable to Membership Inference Attacks (MIA); (3) orthogonal‑gradient techniques that try to protect the utility of remaining clients but struggle with gradient conflicts when multiple clients request unlearning simultaneously; and (4) multi‑objective formulations that balance forgetting and utility but often converge to a local Pareto‑stationary point, after which further forgetting inevitably degrades utility.
The paper introduces FUPareto, a novel framework that tackles these limitations through three intertwined components. First, the Minimum Boundary Shift (MBS) loss is defined as L_MBS = ReLU(z_c – z_next – δ), where z_c is the logit of the true class, z_next is the highest logit among the remaining classes, and δ (10⁻³) is a small margin. Unlike prior objectives that force the target probability to zero or enforce a uniform distribution, MBS only requires the model to cross the nearest decision boundary, thereby minimizing parameter changes and avoiding anomalous output distributions that facilitate MIA. The loss automatically vanishes once the boundary is crossed, providing a self‑terminating and stable optimization signal.
Second, the optimization process alternates between a Pareto improvement step and a Pareto expansion step. In the improvement phase, the authors employ Multiple Gradient Descent Algorithm (MGDA) to compute a common descent direction g_d that simultaneously improves three objectives: the unlearning loss for each forgetting client (U), the utility loss for the remaining clients (R), and a fairness‑guidance term F_p that penalizes disparity among clients. Gradients g_u, g_r, g_p are concatenated into a matrix G, and a low‑dimensional quadratic program yields optimal coefficients λ* that weight each objective. The resulting direction g_d = Gλ* drives the model toward a local Pareto frontier where both forgetting and utility improve together.
When the model reaches this frontier, further reduction of the unlearning loss would increase the utility loss—a phenomenon known as Pareto stagnation. To break out of this impasse, the Pareto expansion step projects the unlearning gradient onto the null‑space of the utility gradients, producing a component g_u^⊥ that is orthogonal to the utility direction. Adding g_u^⊥ to the common descent direction forces deeper forgetting while keeping the impact on utility minimal. After a few expansion iterations, the algorithm returns to the improvement phase to realign the model with the frontier, thus continuously deepening forgetting without sacrificing performance.
Third, FUPareto extends naturally to concurrent multi‑client unlearning. Multiple forgetting clients generate conflicting gradients not only with the remaining clients but also among themselves. The null‑space projection within MGDA resolves these intra‑unlearning conflicts, while the fairness‑guidance term (implemented as F_p = arccos(pᵀF/‖F‖) with p_i = 0 for forgetting clients and p_j = 1 for retained clients) ensures that the forgetting loss is distributed evenly across all unlearning requests, embodying a “forget‑first” principle.
Empirical evaluation spans CIFAR‑10, CIFAR‑100, and FEMNIST under heterogeneous (non‑IID) data partitions. The authors compare against state‑of‑the‑art baselines such as FedEraser, FedOSD, SFU, and FUGAS. Metrics include forgetting efficacy (drop in target‑class accuracy), retained utility (overall accuracy on non‑target data), MIA success rate, and fairness (variance of forgetting loss across clients). FUPareto consistently achieves a larger reduction in target accuracy (often >70 % drop) while limiting utility loss to under 2 %, reduces MIA success by more than 30 % relative to baselines, and maintains low variance in multi‑client scenarios.
Theoretical analysis (provided in the appendix) proves that the Pareto improvement step converges to a Pareto‑optimal region under standard smoothness assumptions, and that the null‑space expansion step guarantees descent in the unlearning loss without increasing the utility loss beyond a bounded factor.
In summary, FUPareto contributes (1) a minimally invasive MBS loss that balances forgetting and privacy, (2) a dynamic Pareto‑augmented optimization loop that prevents stagnation at the Pareto frontier, and (3) a null‑space projected MGDA that resolves gradient conflicts for simultaneous multi‑client unlearning. The framework delivers superior forgetting performance, higher retained utility, and stronger resistance to membership inference attacks, marking a significant advance in practical federated unlearning.
Comments & Academic Discussion
Loading comments...
Leave a Comment