GPD: Guided Progressive Distillation for Fast and High-Quality Video Generation
Diffusion models have achieved remarkable success in video generation; however, the high computational cost of the denoising process remains a major bottleneck. Existing approaches have shown promise in reducing the number of diffusion steps, but they often suffer from significant quality degradation when applied to video generation. We propose Guided Progressive Distillation (GPD), a framework that accelerates the diffusion process for fast and high-quality video generation. GPD introduces a novel training strategy in which a teacher model progressively guides a student model to operate with larger step sizes. The framework consists of two key components: (1) an online-generated training target that reduces optimization difficulty while improving computational efficiency, and (2) frequency-domain constraints in the latent space that promote the preservation of fine-grained details and temporal dynamics. Applied to the Wan2.1 model, GPD reduces the number of sampling steps from 48 to 6 while maintaining competitive visual quality on VBench. Compared with existing distillation methods, GPD demonstrates clear advantages in both pipeline simplicity and quality preservation.
💡 Research Summary
The paper tackles the long‑standing bottleneck of video diffusion models: the costly iterative denoising process required to generate high‑quality videos. While prior works have attempted to reduce the number of diffusion steps, they either rely on distribution‑matching techniques that need large real‑video datasets or on trajectory‑straightening methods that force a student model to mimic a highly curved multi‑step teacher trajectory in a single step. Both approaches suffer from quality loss, especially in the video domain where temporal consistency and fine‑grained details are crucial.
Guided Progressive Distillation (GPD) introduces a new training paradigm that simultaneously accelerates sampling and preserves visual fidelity. The core ideas are:
-
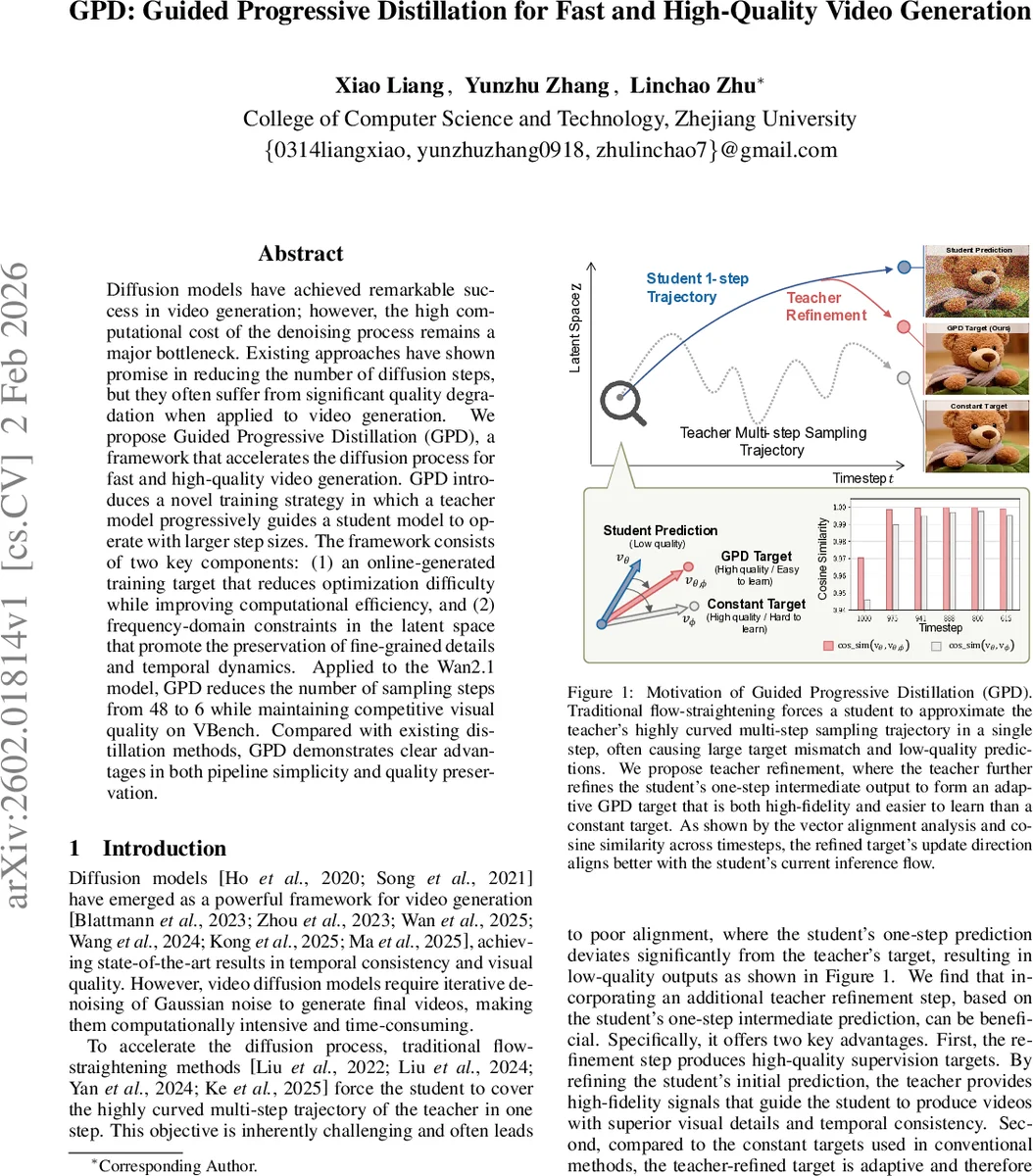
Online‑generated teacher‑refined targets – Instead of using static, pre‑computed teacher trajectories, GPD dynamically refines the student’s intermediate prediction during training. A frozen copy of the student from the previous stage predicts a (k‑1)‑step intermediate latent, which the teacher then refines with one additional step. The resulting latent defines a “velocity” target that is both high‑quality (because it has been refined by the teacher) and easier for the current student to learn (its direction aligns better with the student’s current inference flow, as shown by cosine‑similarity analysis). This online target eliminates the distribution shift that occurs when a student’s own errors accumulate at inference time.
-
Frequency‑domain high‑frequency loss – Video quality heavily depends on preserving high‑frequency spatial and temporal components (edges, textures, fast motion). GPD transforms the latent video into the 3‑D frequency domain via FFT, applies a Gaussian high‑pass filter, and computes an L2 loss between the student’s and teacher‑refined high‑frequency components. The loss weight λ(t) is activated only in the later half of the diffusion timeline (t ≤ 0.5 T), reflecting the observation that high‑frequency information gradually emerges as the diffusion timestep decreases. This encourages the student to retain fine details that are often smoothed out by trajectory‑straightening.
-
Progressive distillation schedule – Training is divided into K stages. Stage 1 learns a 1‑step student; each subsequent stage linearly increases the step size (k = 2…K). The student from the previous stage initializes the next, ensuring a smooth transition from low‑curvature to higher‑curvature trajectories. The loss at stage k combines the velocity loss (L_v) with the time‑aware high‑frequency loss (L_hf).
The algorithm iterates over diffusion timesteps, generates online targets, computes L_v, optionally adds L_hf (only in the final stage and for the latter half of timesteps), and updates the student parameters. Because the teacher refines the student’s own intermediate state, the method requires far fewer pre‑computed teacher trajectories, reducing memory overhead and overall training cost (≈30 % less than offline distillation).
Experimental validation – The authors apply GPD to the Wan2.1‑1.3B video diffusion model, training on the OpenSora text‑to‑video dataset (480 × 832 resolution, 81 frames). Using four A100 GPUs, they distill the model from 48 sampling steps down to 6 steps (an 8× speed‑up). On the VBench benchmark, GPD achieves a total score of 84.04 %, surpassing prior acceleration pipelines such as AccVideo (5 steps, 83.28 %) and CausVid (3 steps, 83.65 %). Detailed metrics show improvements in text‑video alignment, semantic consistency, background stability, and multi‑object relationships. Ablation studies confirm that removing the high‑frequency loss degrades edge sharpness and motion fidelity, while using static teacher targets leads to higher cosine‑similarity gaps and poorer visual quality.
In summary, GPD presents a unified solution that (i) provides high‑fidelity, adaptively generated supervision via teacher refinement, (ii) explicitly preserves high‑frequency details through a frequency‑domain loss, and (iii) employs a progressive step‑size schedule for stable convergence. The method dramatically reduces inference time while maintaining or improving video quality, marking a significant step toward practical, real‑time video generation with diffusion models.
Comments & Academic Discussion
Loading comments...
Leave a Comment