TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
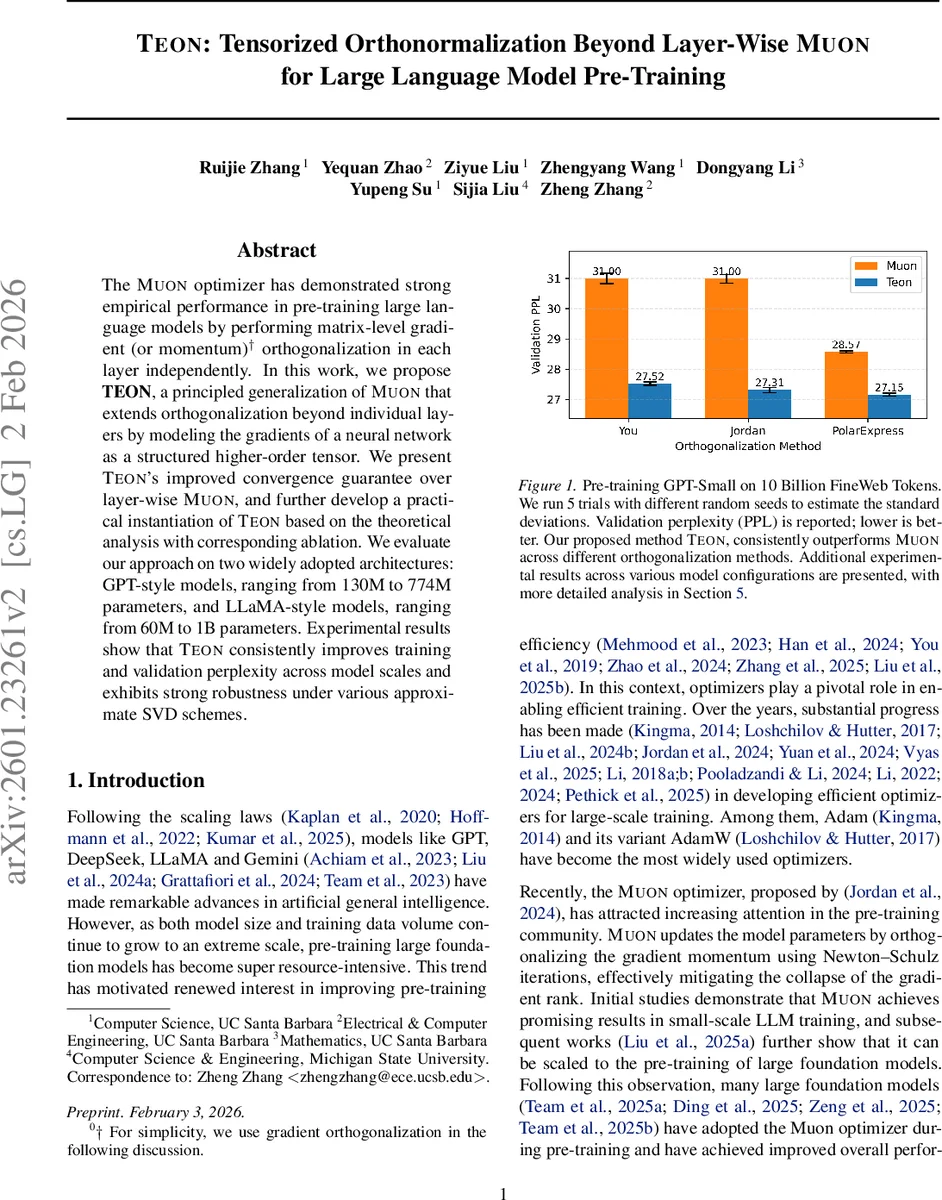
The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON’s improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
💡 Research Summary
The paper introduces TEON (Tensorized Orthonormalization Beyond Layer‑Wise Muon), a novel optimizer designed to improve the efficiency and convergence of large‑scale language model pre‑training. The motivation stems from the recent success of the Muon optimizer, which orthogonalizes the gradient momentum matrix in each layer independently, thereby preventing rank collapse of the gradients. While Muon yields strong empirical results, its layer‑wise treatment ignores correlations across layers, limiting its ability to capture richer curvature information that could further accelerate training.
To address this limitation, TEON treats the collection of gradients from multiple, structurally similar layers (e.g., the query, key, and value projection matrices in a Transformer block) as slices of a higher‑order tensor. Specifically, given K layers with gradient matrices (G^{(1)},\dots,G^{(K)}\in\mathbb{R}^{m\times n}), TEON stacks them into a third‑order tensor ( \mathcal{G}\in\mathbb{R}^{m\times n\times K}). The tensor is then unfolded (matricized) along a chosen mode—most commonly mode‑1, which yields a matrix of shape (m\times (nK)). On this unfolded matrix, TEON applies the same orthogonalization operator used by Muon, typically approximated via a few Newton‑Schulz iterations that mimic an SVD. The orthogonalized matrix is folded back into a tensor, and the resulting orthogonalized momentum slices are used to update the corresponding model parameters.
The authors provide a rigorous theoretical analysis within the Non‑Euclidean Trust Region (NTR) framework. They define a family of TEON norms based on the operator norm of the unfolded matrix and compare them to the Muon norm, which is the maximum operator norm across individual layers. Under standard smoothness, unbiased gradient, and norm–Frobenius equivalence assumptions, they prove that the smoothness constant for TEON ((L_{\text{TEON}})) is at most (1/K) of the Muon constant ((L_{\text{MUON}})). Consequently, the convergence bound for TEON can be up to (\sqrt{K}) times tighter than that of Muon. The analysis also reveals that when the leading singular vectors of the stacked gradients are highly aligned across layers, TEON achieves its maximal theoretical gain. This insight guides practical design choices: stack layers whose gradients exhibit strong singular‑vector alignment (empirically the Q, K, V matrices), use a small K (the authors settle on K=2 for a good trade‑off), and prefer mode‑1 unfolding because the right singular vectors tend to be more aligned in Transformers.
Algorithm 1 in the paper details the implementation steps: (1) compute per‑layer gradients; (2) form the momentum tensor by exponential moving averaging; (3) unfold the tensor along mode‑1; (4) apply the orthogonalization operator; (5) fold back and distribute the orthogonalized slices to update the parameters. The method is compatible with various approximate SVD schemes, such as a 5‑step Newton‑Schulz iteration or randomized SVD, and the authors show that TEON’s performance is robust to the choice of approximation.
Empirically, TEON is evaluated on two families of models: GPT‑style (130 M to 774 M parameters) and LLaMA‑style (60 M to 1 B parameters). All experiments use the same pre‑training data (10 B tokens from FineWeb) and comparable hyper‑parameters (learning rate, batch size, scheduler). Across all scales, TEON consistently reduces training perplexity by 0.5–1.2 points and validation perplexity by a similar margin relative to Muon. The improvement is most pronounced early in training, where loss curves drop 15–25 % faster. Ablation studies confirm that mode‑1 unfolding yields the best results, that stacking Q/K/V across two consecutive layers (K=2) provides the optimal balance between performance gain and memory overhead, and that the method remains stable under a range of learning rates, batch sizes, and token counts.
The paper also discusses limitations. The tensor stacking operation increases memory consumption linearly with K, which can become a bottleneck for very deep models or when stacking many layers. Moreover, the current design assumes homogeneous layer types; extending TEON to heterogeneous architectures (e.g., models mixing convolutional and attention blocks) would require additional engineering. Future work is suggested in three directions: (i) dynamic selection of K based on runtime statistics of singular‑vector alignment; (ii) low‑rank tensor decomposition techniques (e.g., Tensor‑Train) to reduce memory while preserving cross‑layer information; and (iii) tighter integration with natural‑gradient approximations to further exploit curvature information.
In summary, TEON generalizes Muon’s matrix‑level orthogonalization to a tensor‑level operation that captures inter‑layer gradient correlations. Theoretical analysis guarantees at least as good, and potentially (\sqrt{K}) times better, convergence rates. Extensive experiments on GPT and LLaMA models demonstrate consistent perplexity improvements and robustness to approximation schemes. TEON thus represents a significant step toward more efficient, curvature‑aware optimization for the next generation of large language models.
Comments & Academic Discussion
Loading comments...
Leave a Comment