SAPO: Self-Adaptive Process Optimization Makes Small Reasoners Stronger
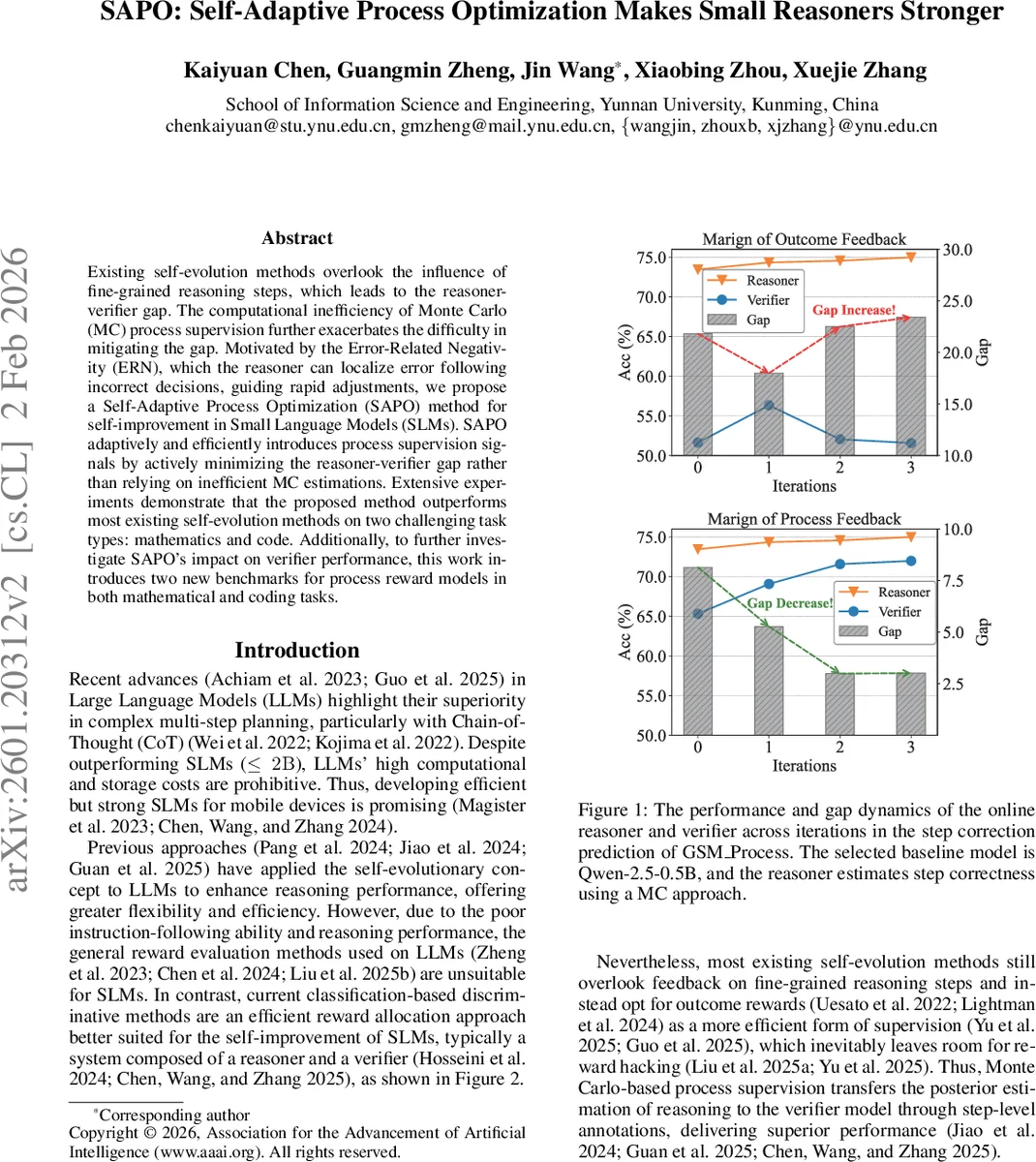
Existing self-evolution methods overlook the influence of fine-grained reasoning steps, which leads to the reasoner-verifier gap. The computational inefficiency of Monte Carlo (MC) process supervision further exacerbates the difficulty in mitigating the gap. Motivated by the Error-Related Negativity (ERN), which the reasoner can localize error following incorrect decisions, guiding rapid adjustments, we propose a Self-Adaptive Process Optimization (SAPO) method for self-improvement in Small Language Models (SLMs). SAPO adaptively and efficiently introduces process supervision signals by actively minimizing the reasoner-verifier gap rather than relying on inefficient MC estimations. Extensive experiments demonstrate that the proposed method outperforms most existing self-evolution methods on two challenging task types: mathematics and code. Additionally, to further investigate SAPO’s impact on verifier performance, this work introduces two new benchmarks for process reward models in both mathematical and coding tasks.
💡 Research Summary
The paper introduces Self‑Adaptive Process Optimization (SAPO), a novel self‑evolution framework designed to improve the reasoning abilities of Small Language Models (SLMs) while addressing the “reasoner‑verifier gap” that hampers current methods. Traditional self‑evolution approaches either rely solely on outcome‑based rewards or use Monte‑Carlo (MC) rollouts to supervise each reasoning step. MC‑based supervision, however, is computationally prohibitive: for an 8‑step problem with 10 sampled trajectories, labeling 10 k problems would require 800 k rollouts.
SAPO draws inspiration from the Error‑Related Negativity (ERN) observed in human cognition, where the brain quickly detects and localizes errors after an incorrect decision. Analogously, SAPO’s verifier assigns a scalar score ˆc_j to every step s_j in a sampled trajectory. By computing the score difference Δ_j = ˆc_j − 1 − ˆc_j, the step with the largest Δ_j is taken as the potential first error position ˆt. Only two additional rollouts (from steps ˆt‑1 and ˆt) are then performed to verify and correct the step‑level label. This “first‑error detection” strategy reduces supervision cost from thousands of rollouts to a handful while still providing high‑quality process signals.
The corrected labels are used to fine‑tune the verifier, which in turn produces more accurate step‑level rewards. The verifier’s cumulative reward for a trajectory is r(τ)=∑_j ˆc_j. Preference pairs (τ_w, τ_l) are constructed when the reward gap exceeds a threshold η, forming a dataset D_pref. SAPO employs the ORPO (Optimized Rejection‑based Preference Optimization) loss to align the reasoner with these preferences, iteratively improving both components.
Algorithm 1 outlines the full training loop: (1) start from a pretrained SLM, (2) apply supervised fine‑tuning (SFT) to obtain an initial reasoner M₀, (3) generate an initial step‑label set using a binary estimator Ω, (4) fine‑tune a verifier V₀ on these labels, and then repeat for T iterations: sample new trajectories, score them with the current verifier, detect the first error, verify with minimal rollouts, update the verifier, compute new preference rewards, and finally align the reasoner.
Experiments were conducted on three modern SLM backbones—Qwen‑2.5‑0.5B, Llama‑3.2‑1B, and Gemma‑2‑2B—across two domains: mathematics (GSM8K and MATH) and code generation (MBPP and HumanEval). Both in‑domain and out‑of‑domain (OOD) settings were evaluated. SAPO was compared against a wide range of baselines, including standard Chain‑of‑Thought (CoT), plain SFT, Rejection‑Sampling Fine‑Tuning (RFT) and its DPO variant, Online‑RFT, Reasoning Preference Optimization (RPO), and Group Relative Policy Optimization (GRPO).
Results show that SAPO consistently outperforms most baselines. For mathematics, SAPO‑iter3 reaches up to 49.73 % accuracy on GSM8K, surpassing the best baseline (GRPO at 46.24 %). On code, SAPO‑iter3 achieves a Pass@1 of 36.67 % on MBPP, again beating the strongest competitor (GRPO at 35.20 %). Gains are also evident in OOD evaluations (MATH and HumanEval).
To assess verifier quality independently, the authors introduce two new benchmarks: GSM Process (3 786 examples) and MBPP Process (1 499 examples). Each example contains two reasoning paths annotated by GPT‑4o with the first incorrect step. These datasets enable fine‑grained measurement of step‑correction prediction accuracy. SAPO‑trained verifiers achieve the highest scores on both benchmarks, confirming that the first‑error detection and minimal‑rollout correction strategy yields superior process supervision.
In summary, the paper makes three key contributions: (1) a cost‑effective self‑evolution framework (SAPO) that replaces exhaustive MC rollouts with first‑error detection and targeted verification, (2) two novel step‑level verification benchmarks for mathematics and coding, and (3) extensive empirical evidence that SAPO narrows the reasoner‑verifier gap and delivers state‑of‑the‑art performance for small models on multi‑step reasoning tasks. This work demonstrates that small, resource‑constrained models can achieve strong reasoning capabilities when equipped with adaptive, efficient process supervision.
Comments & Academic Discussion
Loading comments...
Leave a Comment