Probe and Skip: Self-Predictive Token Skipping for Efficient Long-Context LLM Inference
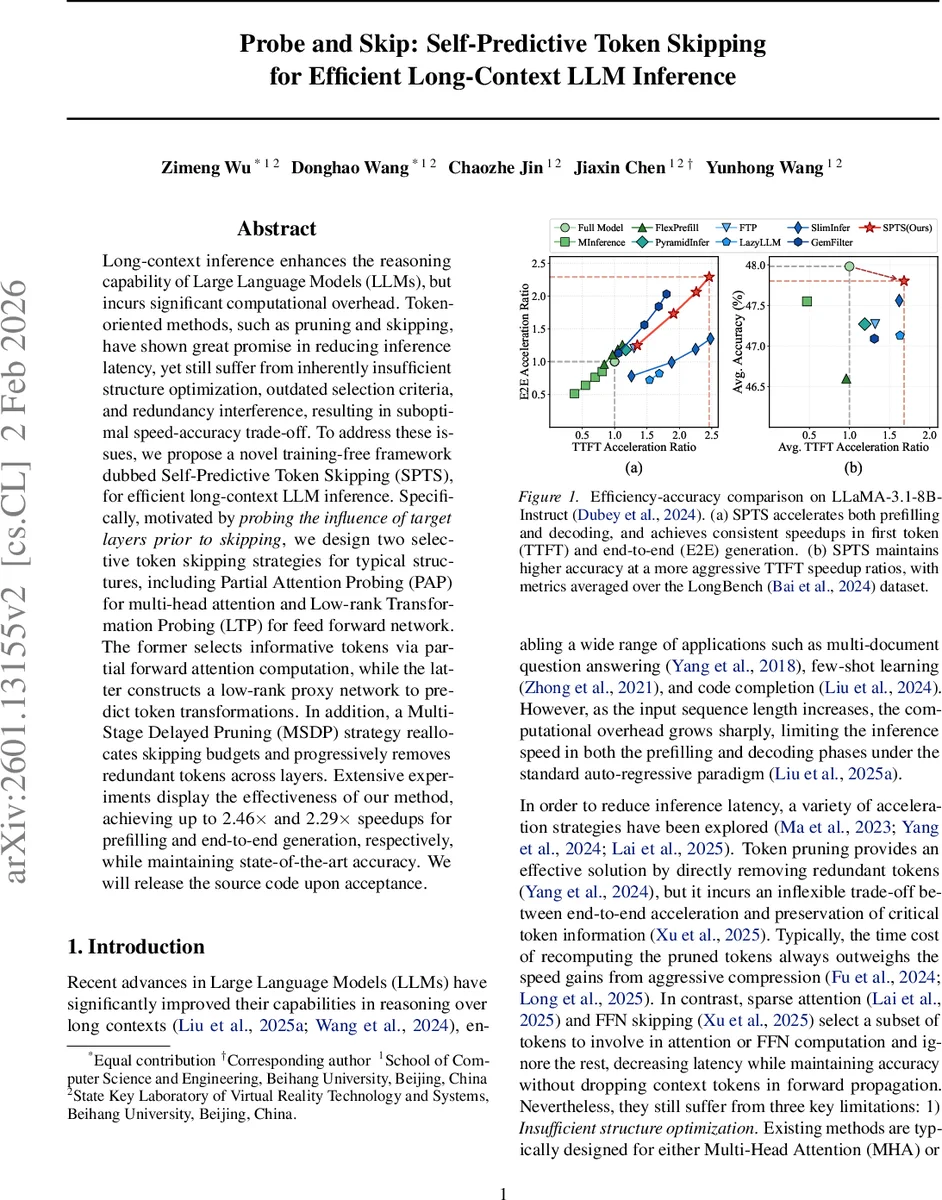
Long-context inference enhances the reasoning capability of Large Language Models (LLMs), but incurs significant computational overhead. Token-oriented methods, such as pruning and skipping, have shown great promise in reducing inference latency, yet still suffer from inherently insufficient structure optimization, outdated selection criteria, and redundancy interference, resulting in suboptimal speed-accuracy trade-off. To address these issues, we propose a novel training-free framework dubbed Self-Predictive Token Skipping (SPTS), for efficient long-context LLM inference. Specifically, motivated by probing the influence of target layers prior to skipping, we design two selective token skipping strategies for typical structures, including Partial Attention Probing (PAP) for multi-head attention and Low-rank Transformation Probing (LTP) for feed forward network. The former selects informative tokens via partial forward attention computation, while the latter constructs a low-rank proxy network to predict token transformations. In addition, a Multi-Stage Delayed Pruning (MSDP) strategy reallocates skipping budgets and progressively removes redundant tokens across layers. Extensive experiments display the effectiveness of our method, achieving up to 2.46$\times$ and 2.29$\times$ speedups for prefilling and end-to-end generation, respectively, while maintaining state-of-the-art accuracy. We will release the source code upon acceptance.
💡 Research Summary
The paper tackles the growing computational burden of long‑context inference in large language models (LLMs) by introducing a training‑free token‑skipping framework called Self‑Predictive Token Skipping (SPTS). Existing token‑pruning and token‑skipping methods suffer from three fundamental problems: insufficient structural optimization (they focus on either the multi‑head attention (MHA) or feed‑forward network (FFN) but not both, or they aggressively prune at the cost of performance), outdated selection criteria (they rely on signals from previous layers that do not reflect a token’s importance in the target layer), and redundancy interference (keeping all tokens throughout deep layers forces repeated evaluation of irrelevant tokens, degrading the signal‑to‑noise ratio).
SPTS’s core principle is “self‑predictive skipping”: a token is eligible for skipping only if its impact on the target layer is negligible. To operationalize this, the authors design two selective‑skipping mechanisms tailored to the two dominant Transformer blocks.
-
Partial Attention Probing (PAP) for MHA – Before the full MHA computation, the key projections for all tokens are pre‑computed, while the query is computed only for the last token (the token that ultimately generates the next output). A lightweight attention score is derived by dot‑producting this query with all keys, normalizing with softmax, and averaging across heads. Tokens with the highest scores are deemed most influential for the last token and are kept active; the rest are bypassed and follow the residual shortcut. Because only active tokens’ query and value projections are needed, the KV cache can be compressed on‑the‑fly, yielding savings during both pre‑fill and decoding.
-
Low‑rank Transformation Probing (LTP) for FFN – FFN transformations are token‑wise, so the magnitude of a token’s change is a natural importance signal. Computing the exact change online would defeat the purpose of skipping, so the authors construct a low‑rank proxy network f that approximates the original FFN. The proxy is built by pruning dimensions of the intermediate activation that have minimal saliency, measured on a calibration set of hidden states. Saliency for each dimension is the average of the top‑ρ fraction of absolute activation values across the calibration tokens. The proxy’s output provides an inexpensive estimate of each token’s transformation magnitude; combined with the PAP attention scores, it yields a final importance ranking. Tokens with larger estimated changes are kept active, while the rest are skipped.
Both PAP and LTP produce a set of active token indices T_active for a given layer, and the residual connection passes the untouched tokens unchanged, as formalized in Equation 2.
To avoid the “all‑or‑nothing” problem of applying a fixed budget across the entire network, SPTS incorporates Multi‑Stage Delayed Pruning (MSDP). The model is divided into several stages; within each stage the candidate token set remains fixed, and pruning is only performed at stage boundaries. Early stages retain a generous token budget to preserve rich contextual information, while later stages progressively shrink the budget, thereby reducing redundancy and preventing the same low‑importance tokens from being evaluated repeatedly. Empirical Jaccard similarity analysis shows that MSDP dramatically lowers overlap between successive token selections, confirming reduced redundancy.
The authors evaluate SPTS on LLaMA‑3.1‑8B‑Instruct and a suite of long‑context benchmarks (LongBench, multi‑document QA, few‑shot learning, code completion). Results demonstrate up to 2.46× speedup in the pre‑fill phase and 2.29× speedup in end‑to‑end generation, with less than 0.2 % absolute drop in benchmark accuracy. Compared against strong baselines such as FlashAttention, sparse‑attention methods, and recent token‑pruning/skipping approaches, SPTS consistently offers a better speed‑accuracy trade‑off while also reducing KV‑cache memory usage thanks to selective caching.
In summary, the paper’s contributions are threefold: (1) a novel, training‑free token‑skipping framework (SPTS) that works for both MHA and FFN; (2) two self‑predictive selection mechanisms—Partial Attention Probing and Low‑rank Transformation Probing—that leverage lightweight probes to estimate token importance in the target layer; (3) a Multi‑Stage Delayed Pruning strategy that dynamically reallocates token budgets across layers to suppress redundancy. Together these innovations provide a practical path toward efficient long‑context inference without sacrificing model performance, and open avenues for future work on adaptive budget allocation and hardware‑aware integration.
Comments & Academic Discussion
Loading comments...
Leave a Comment