Efficient Deep Demosaicing with Spatially Downsampled Isotropic Networks
In digital imaging, image demosaicing is a crucial first step which recovers the RGB information from a color filter array (CFA). Oftentimes, deep learning is utilized to perform image demosaicing. Given that most modern digital imaging applications occur on mobile platforms, applying deep learning to demosaicing requires lightweight and efficient networks. Isotropic networks, also known as residual-in-residual networks, have been often employed for image demosaicing and joint-demosaicing-and-denoising (JDD). Most demosaicing isotropic networks avoid spatial downsampling entirely, and thus are often prohibitively expensive computationally for mobile applications. Contrary to previous isotropic network designs, this paper claims that spatial downsampling to a signficant degree can improve the efficiency and performance of isotropic networks. To validate this claim, we design simple fully convolutional networks with and without downsampling using a mathematical architecture design technique adapted from DeepMAD, and find that downsampling improves empirical performance. Additionally, empirical testing of the downsampled variant, JD3Net, of our fully convolutional networks reveals strong empirical performance on a variety of image demosaicing and JDD tasks.
💡 Research Summary
The paper tackles the problem of designing lightweight yet high‑performance deep networks for image demosaicing, a critical first step in the image‑sensor‑processing (ISP) pipeline, especially on mobile devices where computational resources are limited. Traditional isotropic (or residual‑in‑residual) networks for demosaicing keep the spatial resolution constant throughout the trunk, which leads to very high FLOP counts because the full‑resolution feature maps are processed at every layer. While this design works well for tasks such as super‑resolution, it is inefficient for demosaicing where the input is already high‑resolution.
The authors propose to deliberately introduce spatial downsampling into isotropic networks. Their new architecture, JD3Net, follows a simple recipe: a d×d convolution at the input reduces the resolution by a factor d, then B blocks of a simplified NAFBlock (without any channel‑attention mechanism) are applied at the reduced resolution, and finally a 1×1 convolution followed by a d×d PixelShuffle restores the original spatial size. This design preserves the isotropic property (the trunk still processes a uniform resolution) while dramatically reducing the number of multiply‑adds per forward pass.
To choose the hyper‑parameters (width w, depth B, downsampling ratio d) in a principled way, the authors adapt the Zero‑Shot Neural Architecture Search (Zero‑Shot NAS) method DeepMAD. DeepMAD maximizes an entropy‑based score under constraints on FLOPs and a width‑to‑depth ratio ρ = B / w. However, the original entropy formulation depends on the absolute spatial size of the feature map, which is undesirable for image‑restoration networks that must handle arbitrary resolutions. The authors modify the score to use channel density (channels per output pixel) instead of total channel count, yielding a resolution‑invariant metric:
H_L = log(c_{L+1} / d²) + Σ_i log(c_i k_i² / g_i)
where c_i, k_i, and g_i are the channel count, kernel size, and group count of layer i, respectively. They then solve a constrained optimization problem: maximize H_L subject to ρ ≤ ρ_max, d ≤ 4, and a FLOP budget. The solution consistently selects d > 1, confirming that downsampling improves the entropy (and thus the expressive capacity) of isotropic networks under a fixed computational budget.
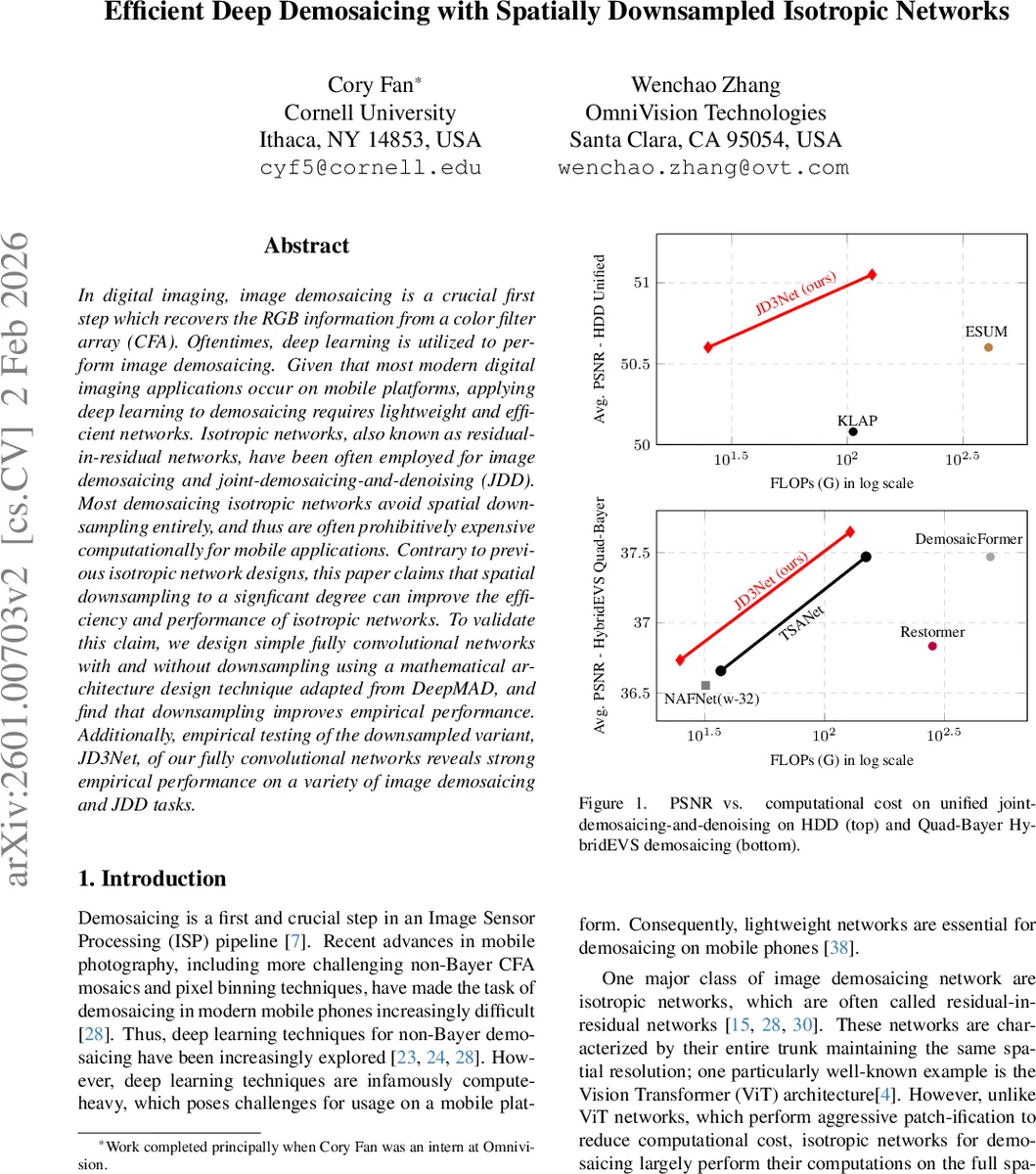
Two network sizes are instantiated: JD3Net‑S (≈25 GFLOPs for a 256×256 image) targeting mobile scenarios, and JD3Net (≈128 GFLOPs) for higher‑end performance. Both are trained on the Hard Demosaicing Dataset (HDD) with 150 epochs, Adam optimizer, and MSE loss. Validation on the ISO‑3200 noisy split shows that the downsampled versions outperform their non‑downsampled counterparts by 0.2–0.3 dB in PSNR, with the smaller model gaining a notable 0.29 dB improvement.
Comprehensive evaluation across four noise levels (ISO 800, 1600, 3200, 6400) and multiple CFA patterns (standard Bayer, non‑Bayer, Quad‑Bayer HybridEVS) demonstrates that JD3Net maintains superior performance while using far fewer FLOPs. On the unified joint demosaicing‑and‑denoising task, JD3Net‑S achieves only 0.1 dB lower PSNR than the state‑of‑the‑art ESUM model but runs 16.3× faster; JD3Net itself surpasses ESUM by 0.35 dB while being 3.2× faster. Qualitative results (Fig. 4) show sharper textures and fewer artifacts despite the reduced computational budget.
The paper’s contributions are threefold: (1) Empirical evidence that spatial downsampling can dramatically improve the FLOP‑to‑performance trade‑off of isotropic demosaicing networks; (2) A modified DeepMAD entropy metric that is resolution‑invariant, enabling principled architecture selection for image‑restoration tasks; (3) Demonstration that a simple convolutional backbone without attention mechanisms can achieve state‑of‑the‑art demosaicing and joint demosaicing‑denoising performance when combined with downsampling.
These findings are highly relevant for on‑device ISP pipelines, where power and latency constraints are strict. By showing that a modest downsampling factor (3–4×) yields both computational savings and accuracy gains, the work opens a practical pathway for deploying deep demosaicing models on smartphones, tablets, and other edge devices. Future research may extend the downsampling‑centric isotropic design to other restoration problems such as denoising, deblurring, or color‑space conversion, and explore adaptive downsampling strategies that vary with scene content or sensor characteristics.
Comments & Academic Discussion
Loading comments...
Leave a Comment