Reassessing Active Learning Adoption in Contemporary NLP: A Community Survey
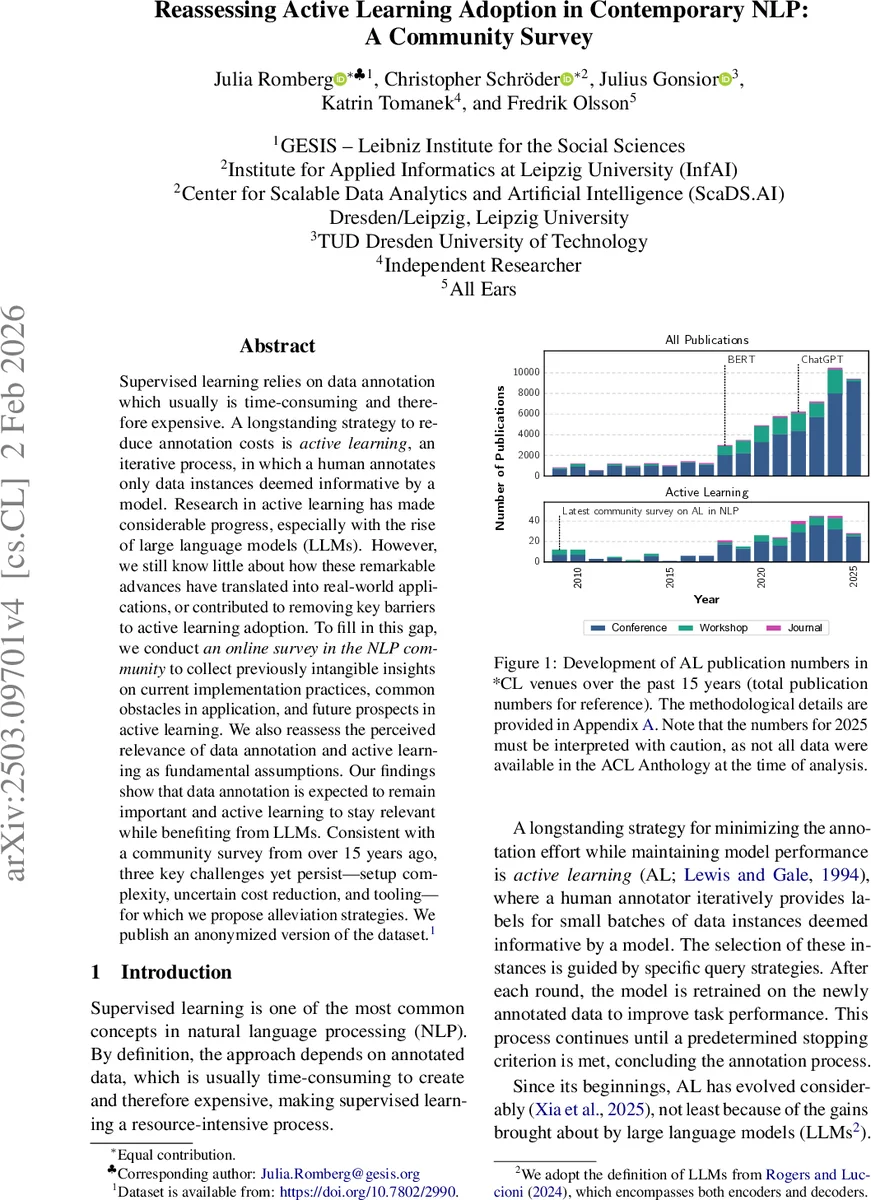
Supervised learning relies on data annotation which usually is time-consuming and therefore expensive. A longstanding strategy to reduce annotation costs is active learning, an iterative process, in which a human annotates only data instances deemed informative by a model. Research in active learning has made considerable progress, especially with the rise of large language models (LLMs). However, we still know little about how these remarkable advances have translated into real-world applications, or contributed to removing key barriers to active learning adoption. To fill in this gap, we conduct an online survey in the NLP community to collect previously intangible insights on current implementation practices, common obstacles in application, and future prospects in active learning. We also reassess the perceived relevance of data annotation and active learning as fundamental assumptions. Our findings show that data annotation is expected to remain important and active learning to stay relevant while benefiting from LLMs. Consistent with a community survey from over 15 years ago, three key challenges yet persist – setup complexity, uncertain cost reduction, and tooling – for which we propose alleviation strategies. We publish an anonymized version of the dataset.
💡 Research Summary
This paper presents the first large‑scale community survey that investigates the real‑world adoption of Active Learning (AL) in Natural Language Processing (NLP) in the era of Large Language Models (LLMs). The authors designed a 52‑question online questionnaire, organized into seven logical groups that branch based on whether respondents have experienced a lack of annotated data, have used AL at all, and whether they have applied AL with human annotators. The survey was distributed through mailing lists, a curated list of 610 authors of prior AL papers, social media, and annotation‑tool providers, and ran for six weeks (December 15 2024 – January 26 2025). A total of 144 participants completed the questionnaire, yielding an 84 % completion rate among those who entered the survey. Demographically, respondents are predominantly based in Europe, work mainly in academia (≈74 %) but also in industry (≈31 %), hold backgrounds in Computer Science or Computational Linguistics, and have 3–10 years of NLP experience.
The study is structured around five research questions (RQs):
-
RQ1 – Relevance of data annotation today: 138 respondents who have faced annotation shortages were asked about the continued need for labeled data. 80 % agree that many problems will still be solved via supervised learning; 94 % consider annotated data a limiting factor overall, 75 % for specific languages, and 91 % for complex tasks. Only 30 % view generative‑AI data synthesis as a viable alternative, indicating that LLMs have not eliminated the annotation bottleneck.
-
RQ2 – How does AL compare to alternative methods? 63 participants (≈44 % of the sample) reported having used AL. The primary motivation was cost reduction (87 %), followed by gaining practical experience (46 %), identifying difficult annotation cases (24 %), and improving data quality (8 %). Among those who never used AL, 25 % had never heard of it, 49 % lacked expertise, 37 % feared implementation overhead, 32 % cited a lack of suitable tools, and 18 % were concerned about sampling bias. Despite these concerns, 54 % of non‑users would consider AL for future projects, and 38 % remain uncertain due to insufficient knowledge.
-
RQ3 – Current implementation practices: Respondents who have applied AL describe a classic loop of “select a small batch → annotate → retrain”. Query strategies are dominated by uncertainty sampling and diversity‑based methods, often combined. Since 2022, there is a noticeable shift toward using LLMs as backbone models, with many participants experimenting with prompt‑engineering plus AL. However, practical obstacles such as choosing the right query strategy, limited GPU/TPU resources, and managing annotator wait times remain prominent.
-
RQ4 – Observed and anticipated developments: Participants report increased interest in “LLM‑driven query strategies”, “few‑shot or zero‑shot prompting for data synthesis”, and “integrated annotation platforms”. Yet they anticipate that the three long‑standing barriers—setup complexity, uncertain cost‑benefit, and inadequate tooling—will continue to hinder broader adoption unless addressed.
-
RQ5 – Comparison with the 2009 Olsson survey: The same three challenges identified over fifteen years ago still dominate the landscape. The novelty lies in the transformation of the “sampling complexity” challenge into a more sophisticated “model and query‑strategy selection” problem due to LLMs. The authors therefore argue that while the nature of the obstacles has evolved, their persistence underscores a need for systematic engineering solutions.
Based on these findings, the authors propose three alleviation strategies:
- Modular AL frameworks – a plug‑in architecture that allows practitioners to swap models, query strategies, and stopping criteria without rewriting the entire pipeline, thereby reducing setup complexity.
- Standardized cost‑effectiveness metrics – automatic reporting of “annotation cost per performance gain” to make the economic impact of AL transparent and comparable across projects.
- Open‑source integrated tooling – a community‑driven annotation platform that natively supports AL loops, providing UI components for batch selection, annotator assignment, and real‑time model updates.
The paper contributes a publicly released, anonymized dataset of the survey responses, detailed methodological documentation (including branching logic and distribution channels), and a discussion linking the empirical results to prior literature on AL, LLMs, and data‑efficient learning.
In conclusion, the study confirms that supervised learning and data annotation remain central in NLP despite the rise of LLMs, and that Active Learning is still perceived as a valuable technique for reducing annotation costs. However, the same three barriers identified a decade and a half ago—setup complexity, ambiguous cost savings, and lack of mature tools—continue to impede widespread adoption. Addressing these issues through modular frameworks, transparent cost metrics, and open‑source tooling is essential for translating the theoretical gains of AL into practical, scalable solutions in modern LLM‑driven NLP pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment