Sparse Autoencoder Features for Classifications and Transferability
Sparse Autoencoders (SAEs) provide potentials for uncovering structured, human-interpretable representations in Large Language Models (LLMs), making them a crucial tool for transparent and controllable AI systems. We systematically analyze SAE for interpretable feature extraction from LLMs in safety-critical classification tasks. Our framework evaluates (1) model-layer selection and scaling properties, (2) SAE architectural configurations, including width and pooling strategies, and (3) the effect of binarizing continuous SAE activations. SAE-derived features achieve macro F1 > 0.8, outperforming hidden-state and BoW baselines while demonstrating cross-model transfer from Gemma 2 2B to 9B-IT models. These features generalize in a zero-shot manner to cross-lingual toxicity detection and visual classification tasks. Our analysis highlights the significant impact of pooling strategies and binarization thresholds, showing that binarization offers an efficient alternative to traditional feature selection while maintaining or improving performance. These findings establish new best practices for SAE-based interpretability and enable scalable, transparent deployment of LLMs in real-world applications. Full repo: https://github.com/shan23chen/MOSAIC.
💡 Research Summary
This paper investigates the use of Sparse Autoencoders (SAEs) as a tool for extracting human‑interpretable features from large language models (LLMs) and applying those features to safety‑critical binary classification tasks. The authors address three primary questions: (1) which model layers and scales yield the most useful representations, (2) how architectural choices of the SAE—particularly its width and pooling strategy—affect downstream performance, and (3) whether binarizing the continuous SAE activations can improve efficiency without sacrificing accuracy.
Experimental Setup
The study uses the publicly released Gemma‑2 family (2 B, 9 B, and instruction‑tuned 9 B‑IT) together with pre‑trained SAEs provided by Gemma‑Scope. For each model three layers are examined (early, middle, late: 5/12/19 for 2 B and 9/20/31 for the larger models). Two SAE widths are evaluated per model (16 K/65 K for 2 B; 16 K/131 K for 9 B/9 B‑IT). No new SAEs are trained; the pipeline only extracts hidden states and the corresponding SAE activations.
Three safety‑relevant binary tasks are used: jailbreak detection, harmful‑prompt screening, and multilingual toxicity detection (datasets drawn from MTEB and other open sources). Baselines consist of a classic TF‑IDF bag‑of‑words model and a linear probe on the last‑token hidden state. Classification is performed with a simple logistic regression model trained via 5‑fold cross‑validation; this is the sole learned component of the pipeline.
Pooling and Binarization
Since SAE activations are produced per token, the authors explore two aggregation strategies: (a) summing all token‑level vectors (no max‑pooling) and (b) selecting the top‑N activations per token (N = 20 or 50) before summation. After aggregation, a binarization step thresholds each dimension at > 1, converting the real‑valued feature vector into a binary 0/1 vector. Binarization is motivated by memory efficiency, a built‑in non‑linearity akin to ReLU, and implicit feature selection.
Key Findings
-
Layer and Model Scale – Middle‑layer SAE features consistently outperform early and late layers, achieving macro F1 scores around 0.85–0.90. Larger models (9 B, 9 B‑IT) yield higher average performance than the 2 B model, reflecting richer hidden representations.
-
SAE Width – Wider SAEs (65 K/131 K) provide modest gains over narrower ones, but at a noticeable computational cost. The authors suggest 65 K–131 K as a practical trade‑off.
-
Pooling Strategy – Top‑N pooling can slightly improve performance when N is increased, yet it requires extra computation to identify the strongest activations. Simple summation of all token activations performs competitively, especially when followed by binarization.
-
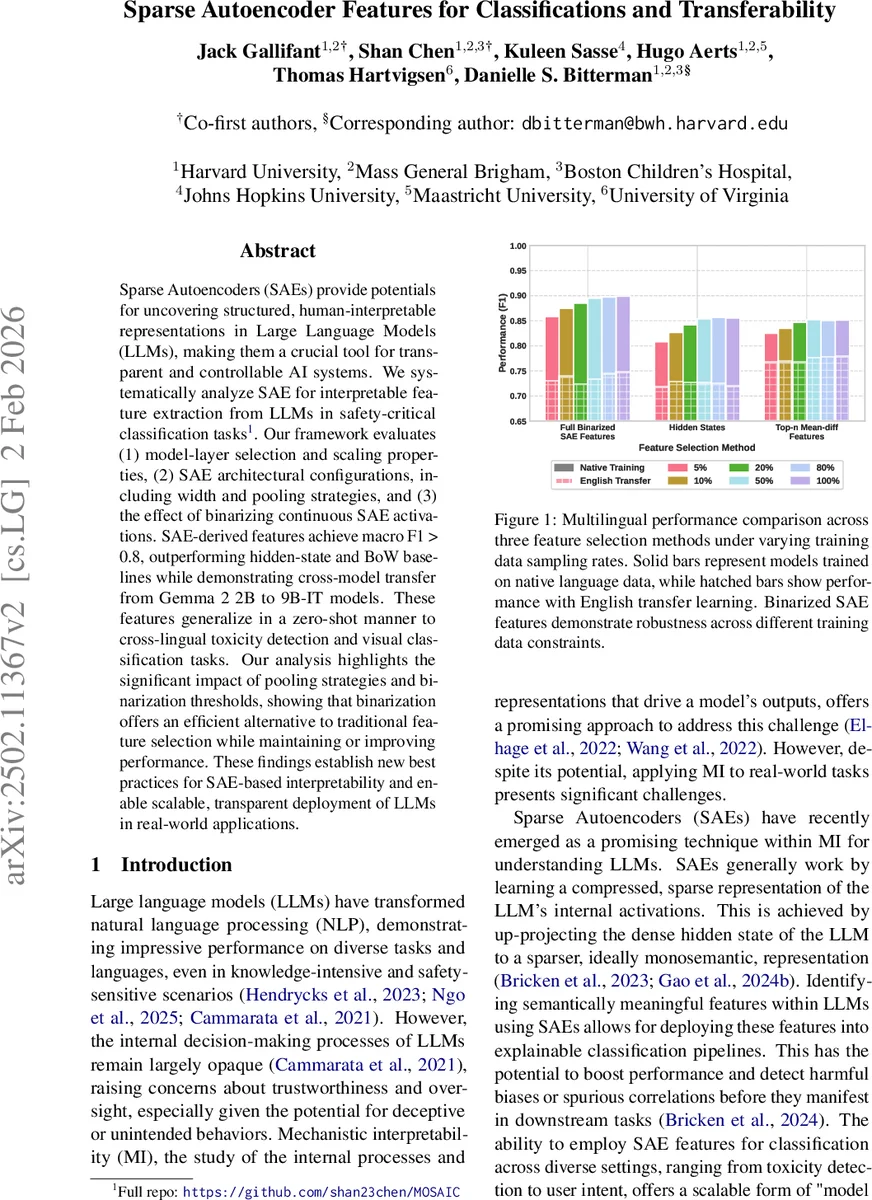
Binarization – Binary SAE features outperform both non‑binarized summed features and the two baselines across most tasks. The benefit is most pronounced in low‑resource regimes (training data ≤ 20 % of the full set), where binary features exhibit greater robustness.
-
Cross‑Model Transfer – Features extracted from the 2 B model transfer almost unchanged to the 9 B and 9 B‑IT models, indicating that SAE dimensions capture model‑agnostic semantic concepts.
-
Multilingual and Multimodal Transfer – English‑trained SAE features retain high macro F1 (> 0.78) on toxicity datasets in other languages, demonstrating zero‑shot cross‑lingual generalization. A preliminary experiment applying text‑trained SAE features to a vision‑language model (PaliGemma‑2) shows promising zero‑shot visual classification performance, suggesting broader multimodal applicability.
-
Baseline Comparison – Across all configurations, SAE‑based features surpass the TF‑IDF and hidden‑state probes, with the best configuration (middle layer, binary, top‑20 pooling) achieving the highest scores.
Reproducibility
All code, data loading scripts, and hyper‑parameter settings are released under an Apache‑2.0 license on GitHub (https://github.com/shan23chen/MOSAIC). A YAML configuration file controls model selection, layer indices, SAE width, and dataset paths, enabling exact replication on three NVIDIA A6000 GPUs (CUDA 12.4).
Conclusions and Future Work
The study establishes that SAEs provide a scalable, interpretable feature extraction mechanism for LLMs, delivering superior classification performance while offering memory‑efficient binary representations. The authors recommend using middle‑layer SAE features, a width of at least 65 K, and either top‑N pooling (with modest N) or full summation followed by binarization for practical deployments. Limitations include focus on binary classification, a limited set of pooling hyper‑parameters, and evaluation on models up to 9 B parameters. Future research should explore multi‑class and multi‑label tasks, larger model families (e.g., 30 B+), and deeper multimodal transfer scenarios. Overall, the paper provides a solid empirical foundation and best‑practice guidelines for leveraging SAE‑derived features in transparent, safety‑critical AI systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment