Minimizing Mismatch Risk: A Prototype-Based Routing Framework for Zero-shot LLM-generated Text Detection
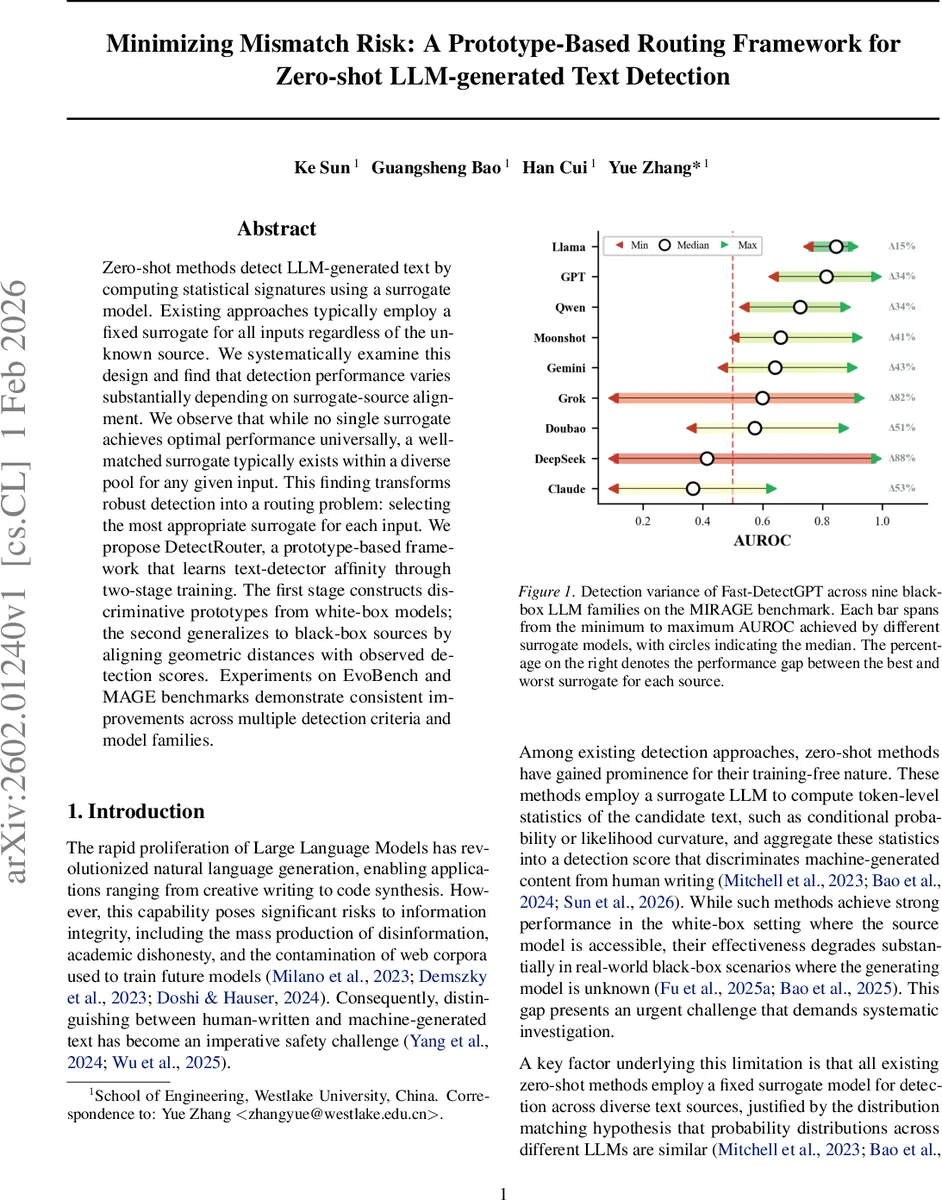
Zero-shot methods detect LLM-generated text by computing statistical signatures using a surrogate model. Existing approaches typically employ a fixed surrogate for all inputs regardless of the unknown source. We systematically examine this design and find that detection performance varies substantially depending on surrogate-source alignment. We observe that while no single surrogate achieves optimal performance universally, a well-matched surrogate typically exists within a diverse pool for any given input. This finding transforms robust detection into a routing problem: selecting the most appropriate surrogate for each input. We propose DetectRouter, a prototype-based framework that learns text-detector affinity through two-stage training. The first stage constructs discriminative prototypes from white-box models; the second generalizes to black-box sources by aligning geometric distances with observed detection scores. Experiments on EvoBench and MAGE benchmarks demonstrate consistent improvements across multiple detection criteria and model families.
💡 Research Summary
The paper addresses a fundamental limitation of current zero‑shot detection methods for large language model (LLM)‑generated text: the use of a single, fixed surrogate model to compute statistical signatures regardless of the unknown source model. Through extensive cross‑evaluation on nine open‑source LLMs, the authors demonstrate that detection performance varies dramatically with surrogate‑source alignment. When the surrogate matches the source, AUROC scores can exceed 0.9, but mismatched surrogates can drop performance to near‑random levels (AUROC ≈ 0.2). This variance is structured: models sharing architectural lineage (e.g., GPT‑Neo vs. GPT‑J) retain higher mutual affinity, while structurally distinct models suffer large gaps.
To explain this phenomenon, the authors derive a “Mismatch Risk Bound” showing that the absolute error between the ideal detection statistic (computed under the true source distribution) and the proxy statistic (computed under the surrogate) is bounded by the square root of the KL‑divergence between the source and surrogate distributions. Consequently, the optimal surrogate for any given text is the one that minimizes this KL‑divergence, turning robust detection into a routing problem: select, per input, the surrogate whose distribution is closest to the unknown source.
DetectRouter is introduced as a prototype‑based routing framework that operationalizes this insight. The system consists of two training stages.
Stage 1 – Discriminative Prototype Construction: Using a set of white‑box LLMs (where source labels are known), the authors generate multi‑task data (direct generation, polishing, rewriting) to capture model‑specific stylistic fingerprints. An encoder Eθ maps texts into a metric space, and each detector (i.e., each surrogate model) is represented by a set of learnable prototypes. Training optimizes a cross‑entropy loss that clusters embeddings around their ground‑truth prototypes, a margin‑based separation loss that pushes prototypes of different detectors apart, and a norm regularization term. The result is a well‑structured embedding space with tight intra‑class clusters and clear inter‑class margins.
Stage 2 – Black‑Box Generalization via Distributional Alignment: For black‑box sources (e.g., GPT‑4, Claude, Gemini) where true labels are unavailable, the authors collect detection scores from the entire surrogate pool. They then align the geometric distances in the embedding space with these observed score distributions by minimizing a KL‑divergence‑based loss that encourages texts to be close to the prototype of the surrogate that yields the highest detection score. This indirect supervision enables the router to infer distributional affinity without explicit source labels.
At inference time, a given text is encoded, the nearest prototype across all detectors is identified, and the corresponding surrogate’s detection criterion (e.g., likelihood, Fast‑DetectGPT) is applied. This nearest‑prototype query implements the routing decision “choose the surrogate that minimizes estimated KL‑divergence.”
The authors evaluate DetectRouter on two comprehensive benchmarks: EvoBench (covering diverse models, prompts, and domains) and MAGE (featuring proprietary models such as GPT‑4, Claude, Gemini, DeepSeek). Six detection criteria are tested: likelihood, rank, log‑rank, entropy, Fast‑DetectGPT, and a composite metric. Across all settings, DetectRouter consistently outperforms fixed‑surrogate baselines, achieving average AUROC improvements ranging from 5.4 % to 139.4 % and a mean gain of 36.1 % over baselines. Notably, for Fast‑DetectGPT the average AUROC reaches 90.85 % on EvoBench and 77.92 % on MAGE, surpassing the previous state‑of‑the‑art by 9.84 and 4 percentage points respectively. Ablation studies examine the impact of prototype count, embedding dimensionality, temperature scaling, and routing error, confirming the robustness of the approach.
The paper concludes that dynamic, data‑driven surrogate selection dramatically mitigates the “mismatch risk” inherent in zero‑shot LLM detection. DetectRouter’s prototype‑based design is modular and can be attached to any existing zero‑shot detector, requiring only the addition of new prototypes when new surrogates become available. Limitations include increased memory and retrieval cost with large prototype sets and the current focus on plain text (extensions to code, tables, or multimodal data are left for future work). Potential future directions involve multi‑prototype ensembles, cost‑aware routing, and integration into real‑time content‑moderation pipelines. Overall, the work provides a theoretically grounded and empirically validated solution that transforms zero‑shot LLM‑generated text detection from a static to an adaptive, routing‑centric paradigm.
Comments & Academic Discussion
Loading comments...
Leave a Comment