EMFormer: Efficient Multi-Scale Transformer for Accumulative Context Weather Forecasting
Long-term weather forecasting is critical for socioeconomic planning and disaster preparedness. While recent approaches employ finetuning to extend prediction horizons, they remain constrained by the issues of catastrophic forgetting, error accumulation, and high training overhead. To address these limitations, we present a novel pipeline across pretraining, finetuning and forecasting to enhance long-context modeling while reducing computational overhead. First, we introduce an Efficient Multi-scale Transformer (EMFormer) to extract multi-scale features through a single convolution in both training and inference. Based on the new architecture, we further employ an accumulative context finetuning to improve temporal consistency without degrading short-term accuracy. Additionally, we propose a composite loss that dynamically balances different terms via a sinusoidal weighting, thereby adaptively guiding the optimization trajectory throughout pretraining and finetuning. Experiments show that our approach achieves strong performance in weather forecasting and extreme event prediction, substantially improving long-term forecast accuracy. Moreover, EMFormer demonstrates strong generalization on vision benchmarks (ImageNet-1K and ADE20K) while delivering a 5.69x speedup over conventional multi-scale modules.
💡 Research Summary
The paper addresses three major challenges in data‑driven long‑term weather forecasting: catastrophic forgetting, error accumulation, and high computational cost during fine‑tuning. To overcome these, the authors propose a three‑stage pipeline—pre‑training, accumulative‑context fine‑tuning, and multi‑step forecasting—centered around a novel architecture called EMFormer (Efficient Multi‑scale Transformer).
EMFormer Architecture
Traditional multi‑scale transformers use separate convolutional branches (e.g., 1×1, 3×3, 5×5 kernels) to capture features at different receptive fields, which incurs significant overhead. EMFormer replaces this with a single “Multi‑Conv” layer that fuses the three kernels into one operation. By zero‑padding the smaller kernels to the size of the largest (5×5) and aligning their centers, the forward pass computes the same output as the three‑branch version but with a single convolution. Crucially, the authors implement a custom CUDA kernel for the backward pass that keeps the gradient streams for each original kernel separate, preserving scale‑specific learning dynamics. Theorem 2.1 formally proves (1) functional equivalence, (2) gradient equivalence, and (3) a reduction of computational complexity from O(N·H·W·r²) to O(H·W·r_max²), yielding a 5.69× speedup in both training and inference.
Accumulative‑Context Fine‑Tuning
In auto‑regressive forecasting, each step’s prediction becomes the next step’s input, leading to error propagation. The authors introduce a memory module that stores the Key‑Value (KV) pairs from previous transformer blocks. At each step, the current query Q interacts with a concatenation of current and cached keys K, producing an attention map A_ttn. After softmax and averaging, a score vector S_cur is obtained. Historical scores S_his are blended with S_cur using a high weighting factor λ = 0.9, preserving the most recent token unchanged. The top N‑2 scores are kept, and the corresponding KV pairs are passed forward, effectively pruning the cache while retaining the most informative context. This accumulative‑context fine‑tuning stabilizes long‑horizon predictions without sacrificing short‑term accuracy.
Sinusoidal‑Weighted Composite Loss
Atmospheric variables exhibit heterogeneous spatial and physical characteristics. To balance these during training, the authors design a loss that combines variable‑specific terms and latitude‑aware terms, each modulated by a sinusoidal schedule ω(t)=sin(π·t/T). Early in training, all components receive similar weight; as training progresses, the schedule emphasizes variables or regions that are harder to learn (e.g., high‑latitude dynamics). Theorem 2.2 demonstrates that this dynamic weighting leads to smoother optimization trajectories and better convergence.
Experimental Evaluation
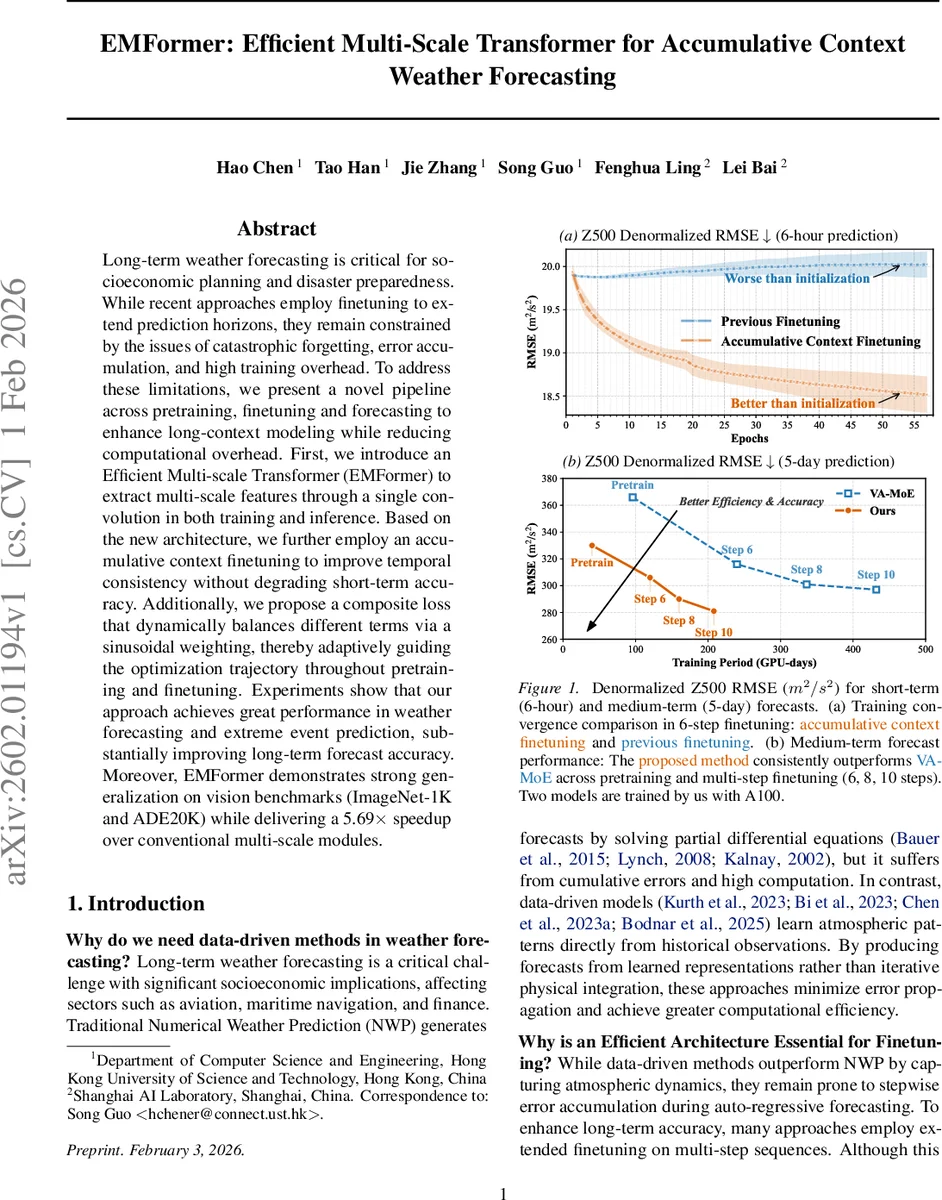
The authors evaluate on the Z500 (500 hPa geopotential height) dataset for both 6‑hour short‑term and 5‑day medium‑term forecasts. Figure 1a shows that accumulative‑context fine‑tuning consistently reduces RMSE across 6 fine‑tuning steps, whereas conventional fine‑tuning degrades performance. Figure 1b compares EMFormer with the state‑of‑the‑art VA‑MoE model across 6, 8, 10 fine‑tuning steps. EMFormer reaches an RMSE of ~280 m² s⁻² after 210 GPU‑days (Step 10), while VA‑MoE requires 430 GPU‑days to achieve ~295 m² s⁻², demonstrating both higher accuracy and lower computational demand.
Beyond meteorology, EMFormer is tested on ImageNet‑1K classification and ADE20K segmentation. It matches or slightly exceeds the performance of existing multi‑scale transformers while preserving the 5.69× speed advantage, indicating strong cross‑domain generalization. Ablation studies on the memory cache length N and blending factor λ reveal that N = 5 and λ = 0.9 provide the best trade‑off between memory usage and forecast stability.
Limitations and Future Work
The memory‑pruning hyper‑parameters are dataset‑dependent, requiring tuning for different forecasting horizons. Very long horizons (several weeks) still exhibit residual error accumulation, suggesting the need for additional regularization or hybrid physics‑based constraints. The current implementation relies on custom CUDA kernels; extending the efficiency gains to other hardware (e.g., TPUs) will require further engineering.
Conclusion
EMFormer, together with accumulative‑context fine‑tuning and a sinusoidal‑weighted loss, offers a unified solution that significantly improves long‑term weather forecasting accuracy while drastically reducing training and inference costs. Its demonstrated effectiveness on vision benchmarks underscores the broader applicability of the proposed multi‑scale efficiency technique. Future research directions include automated memory management, integration with physical models, and hardware‑agnostic optimizations.
Comments & Academic Discussion
Loading comments...
Leave a Comment