Don't Judge a Book by its Cover: Testing LLMs' Robustness Under Logical Obfuscation
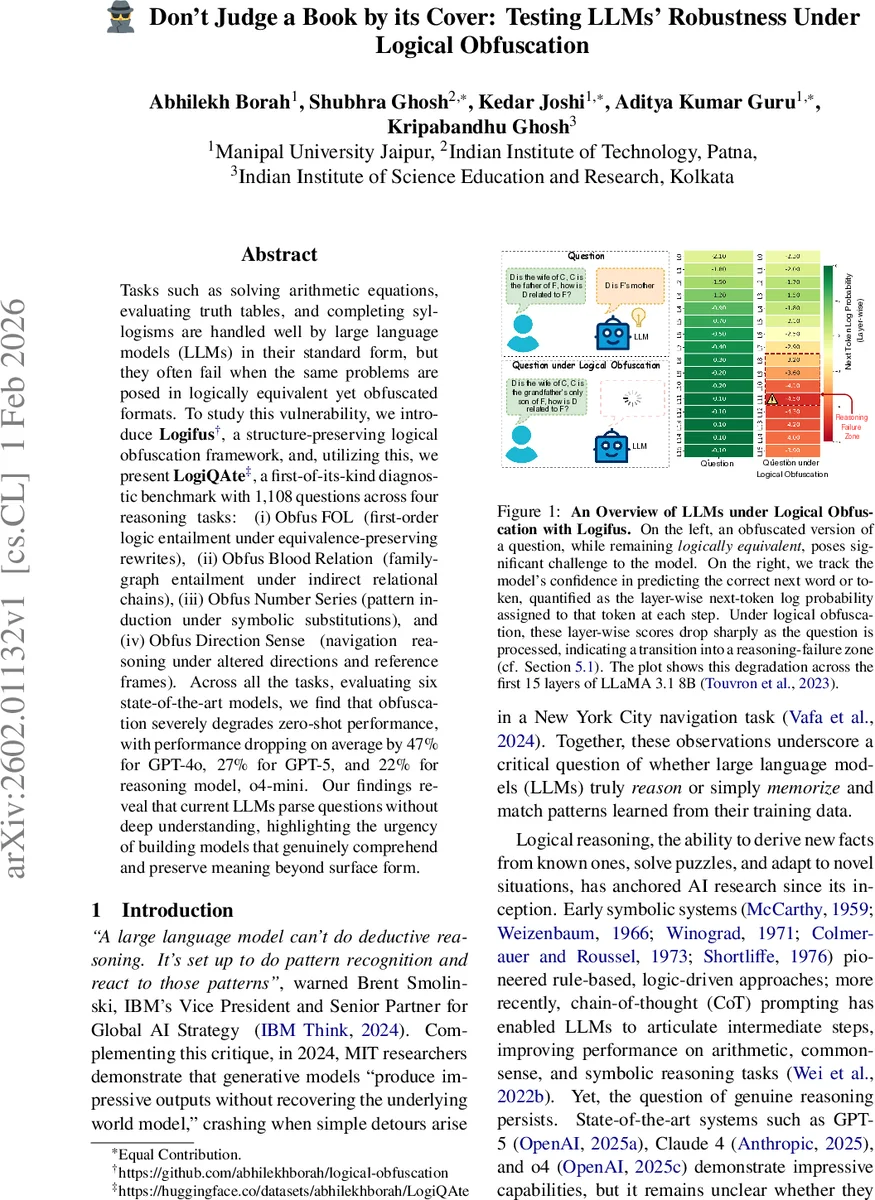
Tasks such as solving arithmetic equations, evaluating truth tables, and completing syllogisms are handled well by large language models (LLMs) in their standard form, but they often fail when the same problems are posed in logically equivalent yet obfuscated formats. To study this vulnerability, we introduce Logifus, a structure-preserving logical obfuscation framework, and, utilizing this, we present LogiQAte, a first-of-its-kind diagnostic benchmark with 1,108 questions across four reasoning tasks: (i) Obfus FOL (first-order logic entailment under equivalence-preserving rewrites), (ii) Obfus Blood Relation (family-graph entailment under indirect relational chains), (iii) Obfus Number Series (pattern induction under symbolic substitutions), and (iv) Obfus Direction Sense (navigation reasoning under altered directions and reference frames). Across all the tasks, evaluating six state-of-the-art models, we find that obfuscation severely degrades zero-shot performance, with performance dropping on average by 47% for GPT-4o, 27% for GPT-5, and 22% for reasoning model, o4-mini. Our findings reveal that current LLMs parse questions without deep understanding, highlighting the urgency of building models that genuinely comprehend and preserve meaning beyond surface form.
💡 Research Summary
The paper introduces a novel robustness test for large language models (LLMs) called logical obfuscation, which rewrites questions into logically equivalent but surface‑different forms while preserving their underlying logical structure. The authors present Logifus, a systematic algorithm that applies a suite of logic‑preserving transformations such as De Morgan’s laws, double‑negation elimination, multi‑hop relational rewrites, symbolic substitutions, arithmetic transformations, and direction‑frame changes. Using Logifus, they construct LogiQAte, a diagnostic benchmark comprising 1,108 carefully curated items across four reasoning domains: (i) Obfus FOL – first‑order logic entailment, (ii) Obfus Blood Relation – family‑graph reasoning with indirect kinship chains, (iii) Obfus Number Series – pattern induction under symbolic and arithmetic obfuscations, and (iv) Obfus Direction Sense – navigation puzzles with altered directional vocabularies.
Dataset creation involved sourcing high‑quality base questions from existing resources (e.g., FOLIO, educational puzzle sites), simplifying premises with GPT‑4o, and then rigorously validating logical equivalence through two human annotators (Cohen’s κ > 0.88) and automated theorem proving (Prover9) where applicable. Each base question was paired with an obfuscated counterpart, ensuring identical correct answers.
The authors evaluate six state‑of‑the‑art models—including GPT‑4o, GPT‑5, Claude‑4, o4‑mini, LLaMA‑3.1‑8B, and an additional open‑source model—under zero‑shot, few‑shot, and chain‑of‑thought prompting. Across all tasks, logical obfuscation causes a substantial performance drop, averaging a 28.8 % relative decrease in accuracy. The degradation is most severe for GPT‑4o (‑47 %), followed by GPT‑5 (‑27 %) and o4‑mini (‑22 %). Tasks with deeper relational chains (Obfus Blood Relation Level 2) and complex directional rewrites exhibit the steepest declines.
Further analysis reveals that models rely heavily on surface memorization: detection rates for memorized answers rise from 50 % on original questions to 82 % on obfuscated ones, indicating that models are matching patterns rather than reasoning. Layer‑wise next‑token log‑probability traces show a 50‑80 % collapse in confidence during later transformer layers when processing obfuscated inputs, suggesting a failure to maintain logical coherence in deeper reasoning stages.
The paper’s contributions are fourfold: (1) the Logifus algorithm for generating logically equivalent but syntactically diverse question variants; (2) the LogiQAte benchmark, the first large‑scale diagnostic suite targeting logical obfuscation across multiple reasoning modalities; (3) a comprehensive empirical study exposing a critical brittleness in current LLMs despite their impressive performance on standard benchmarks; and (4) diagnostic insights into model behavior through memorization tests and layer‑wise confidence analysis.
The findings underscore that contemporary LLMs largely perform pattern matching rather than genuine logical inference, and that robustness to logically equivalent reformulations remains an open challenge. Future work should explore architectures that explicitly encode logical structure, hybrid systems that integrate external theorem provers, and training regimes that promote invariance to logical obfuscation. LogiQAte and Logifus provide valuable tools for measuring progress toward these goals.
Comments & Academic Discussion
Loading comments...
Leave a Comment