Logic-Oriented Retriever Enhancement via Contrastive Learning
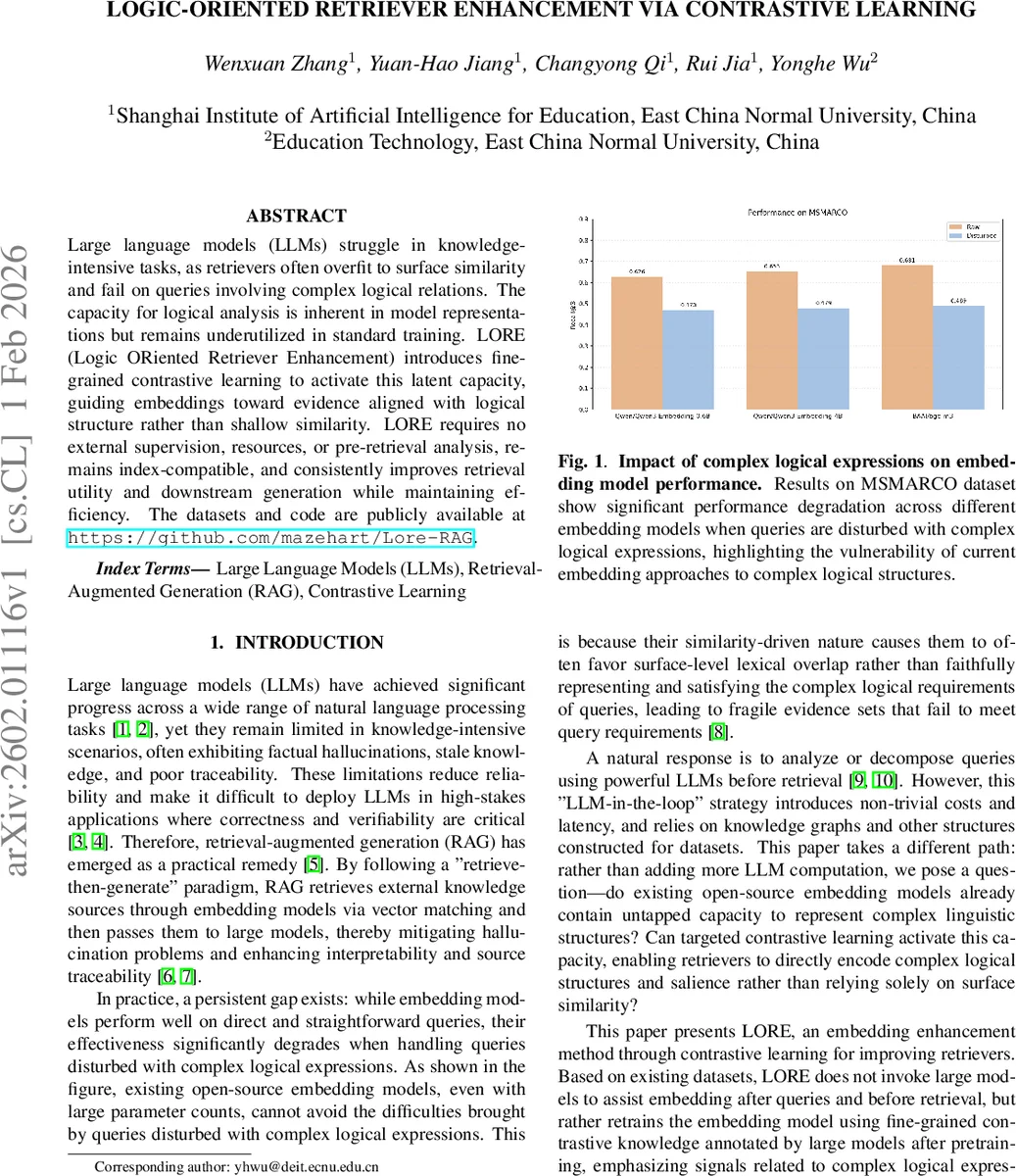
Large language models (LLMs) struggle in knowledge-intensive tasks, as retrievers often overfit to surface similarity and fail on queries involving complex logical relations. The capacity for logical analysis is inherent in model representations but remains underutilized in standard training. LORE (Logic ORiented Retriever Enhancement) introduces fine-grained contrastive learning to activate this latent capacity, guiding embeddings toward evidence aligned with logical structure rather than shallow similarity. LORE requires no external upervision, resources, or pre-retrieval analysis, remains index-compatible, and consistently improves retrieval utility and downstream generation while maintaining efficiency. The datasets and code are publicly available at https://github.com/mazehart/Lore-RAG.
💡 Research Summary
The paper addresses a critical weakness of current retrieval‑augmented generation (RAG) pipelines: embedding‑based retrievers tend to over‑rely on surface lexical similarity and consequently fail when queries contain complex logical expressions (e.g., conjunctions, contrasts, conditionals). While prior work has tried to plug LLMs into the pre‑retrieval stage or to enrich retrieval with external knowledge graphs, these solutions introduce extra latency, require additional supervision, and are not easily transferable across tasks.
LORE (Logic‑ORiented Retriever Enhancement) proposes a different route: it assumes that open‑source embedding models already encode latent logical reasoning capabilities that are simply under‑exploited. By fine‑tuning only the query encoder with a specially crafted contrastive loss, LORE activates this latent capacity without changing the document encoder or the underlying index.
Dataset construction (CoEnTrain) starts from an existing corpus of (query, candidate chunks) pairs with binary relevance labels. For each query, a subset of false‑labeled chunks is sampled as distractors. An LLM is then prompted to rewrite the query, embedding the distractor content while preserving the original intent. The rewritten query is annotated with a discourse relation drawn from Rhetorical Structure Theory (RST) (e.g., Parallel, Contrastive). This yields three tiers for each candidate: Positive (P), Distractor (N1), and General Negative (N2).
The contrastive objective uses two encoders: a frozen document encoder (M_d) and a trainable query encoder (M_q). Cosine similarities (s_k) are temperature‑scaled and then shifted in logit space: (\tilde{s}_k = s_k/\tau) for positives, (\tilde{s}_k = s_k/\tau + \log(\beta)) for distractors, and (\tilde{s}_k = s_k/\tau + \log(\alpha)) for general negatives, with (\beta > \alpha > 0). This weighting penalizes distractors more heavily than generic negatives, encouraging the model to learn fine‑grained distinctions. The probability of a positive sample excludes other positives from the denominator, preventing dilution. The loss is the InfoNCE‑style negative log‑likelihood summed over all positives.
Experiments fine‑tuned Qwen3‑Embedding‑0.6B and BGE‑M3 on a single A800 GPU (learning rate (1!\times!10^{-5}), (\tau=0.05), (\alpha=1.0), (\beta=3.0), 1 epoch, batch size 32). Evaluation used Recall@k (k = 3, 5, 10) on three benchmarks: MS MARCO, HotpotQA, and MuSiQue. Both raw and “disturbed” test sets (queries rewritten with logical distractors) were evaluated.
Results (Table 1) show that LORE consistently outperforms the raw models and a baseline InfoNCE fine‑tuning. On disturbed data, LORE improves Positive Recall by 2–5 percentage points and dramatically reduces the recall of distractor (N1) chunks, confirming that the tier‑weighted loss successfully teaches the encoder to ignore superficially similar but logically irrelevant passages. Notably, only MS MARCO received fine‑grained annotations, yet HotpotQA and MuSiQue also benefited, indicating strong cross‑task generalization.
The authors discuss training dynamics: early epochs mistakenly rank distractors higher due to lexical overlap, but as training proceeds the N1 scores drop below N2, while positives remain stable, confirming the hierarchical separation enforced by the loss.
Limitations include the relatively narrow set of logical structures covered (eight RST relations) and the dependence on LLM‑driven query rewriting for dataset creation. Future work aims to automate fine‑grained annotation across more realistic queries, extend to multilingual and multimodal settings, and explore richer logical patterns.
In summary, LORE offers a lightweight, index‑compatible method to endow existing embedding retrievers with a deeper understanding of logical query structure. By leveraging contrastive learning with tiered weighting, it unlocks latent reasoning abilities without additional external resources, yielding measurable gains on both standard and logically perturbed retrieval tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment