VEQ: Modality-Adaptive Quantization for MoE Vision-Language Models
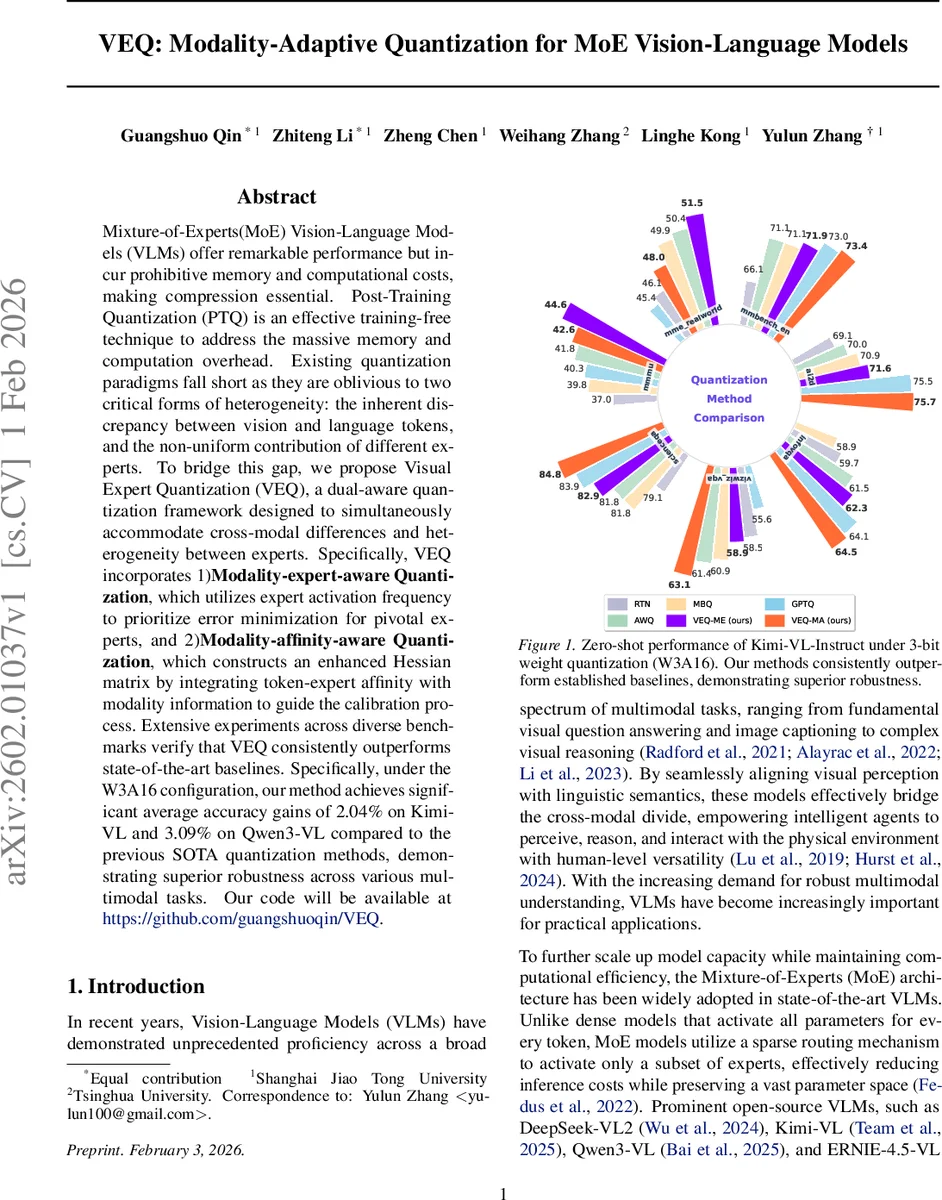
Mixture-of-Experts(MoE) Vision-Language Models (VLMs) offer remarkable performance but incur prohibitive memory and computational costs, making compression essential. Post-Training Quantization (PTQ) is an effective training-free technique to address the massive memory and computation overhead. Existing quantization paradigms fall short as they are oblivious to two critical forms of heterogeneity: the inherent discrepancy between vision and language tokens, and the non-uniform contribution of different experts. To bridge this gap, we propose Visual Expert Quantization (VEQ), a dual-aware quantization framework designed to simultaneously accommodate cross-modal differences and heterogeneity between experts. Specifically, VEQ incorporates 1)Modality-expert-aware Quantization, which utilizes expert activation frequency to prioritize error minimization for pivotal experts, and 2)Modality-affinity-aware Quantization, which constructs an enhanced Hessian matrix by integrating token-expert affinity with modality information to guide the calibration process. Extensive experiments across diverse benchmarks verify that VEQ consistently outperforms state-of-the-art baselines. Specifically, under the W3A16 configuration, our method achieves significant average accuracy gains of 2.04% on Kimi-VL and 3.09% on Qwen3-VL compared to the previous SOTA quantization methods, demonstrating superior robustness across various multimodal tasks. Our code will be available at https://github.com/guangshuoqin/VEQ.
💡 Research Summary
This paper tackles the under‑explored problem of post‑training quantization (PTQ) for mixture‑of‑experts (MoE) vision‑language models (VLMs). While MoE architectures dramatically reduce inference cost by activating only a few experts per token, they introduce two sources of heterogeneity that render existing PTQ methods ineffective: (1) a stark distributional gap between visual and textual tokens, and (2) a highly non‑uniform utilization of experts, where a small subset of “hot” experts processes the majority of tokens. The authors first quantify these gaps. Gradient analysis on 128 COCO samples shows that the average gradient norm of text tokens is 22.4× larger than that of vision tokens, indicating that textual information is far more sensitive to quantization noise. Routing statistics reveal that many experts are rarely or never activated, while a few dominate the model’s output, and that certain experts exhibit strong modality‑specific preferences (some specialize in visual features, others in language).
To address both issues, the authors propose Visual Expert Quantization (VEQ), a dual‑aware PTQ framework consisting of two complementary components:
-
Modality‑Expert‑aware Quantization (VEQ‑ME).
Each expert i receives an importance weight (S_i) derived from its normalized activation frequency across a calibration set. The reconstruction loss is weighted by these scores: (\mathcal{L}_{ME}= \sum_i S_i |W_i^{fp} - Q(W_i^{fp})|^2). Consequently, the quantization error is minimized for the most frequently used experts, preserving the precision of the “hot” experts that drive performance. -
Modality‑Affinity‑aware Quantization (VEQ‑MA).
Building on Hessian‑based PTQ (e.g., GPTQ), the authors augment the Hessian matrix with token‑expert affinity information and modality‑sensitivity factors. They construct an enhanced Hessian (\tilde{H}=A^\top \operatorname{diag}(m) A), where (A) encodes the affinity logits between tokens and experts, and (m) is a modality‑sensitivity vector that assigns larger values to text tokens (reflecting their higher gradient magnitude) and smaller values to vision tokens. This re‑weighted Hessian guides the quantization step to allocate more precision where it matters most.
The framework is evaluated on two state‑of‑the‑art MoE VLMs—Kimi‑VL and Qwen3‑VL—across a suite of multimodal benchmarks (MMMU, MME‑RealWorld, MMBench, InfoVQA, etc.). Experiments focus on the challenging W3A16 configuration (3‑bit weights, 16‑bit activations) and also include lower‑bit settings. VEQ consistently outperforms strong baselines such as A‑WQ, GPTQ, MBQ, SmoothQuant, and SpinQuant. Under W3A16, VEQ yields average accuracy gains of 2.04 % on Kimi‑VL and 3.09 % on Qwen3‑VL relative to the previous best PTQ method. The improvements are robust across tasks and persist even when the calibration data distribution varies, confirming that the method effectively captures both expert‑level and modality‑level heterogeneity.
Key contributions are:
- The first systematic analysis of modality‑specific gradient sensitivity and expert activation imbalance in MoE VLMs.
- A novel importance‑weighted reconstruction loss that prioritizes “hot” experts (VEQ‑ME).
- An affinity‑enhanced Hessian that integrates token‑expert routing scores with modality‑sensitivity, enabling more accurate weight reconstruction (VEQ‑MA).
- Extensive empirical validation showing state‑of‑the‑art quantized performance on large‑scale MoE VLMs.
The paper also outlines future directions: extending the approach to mixed‑precision per‑expert quantization, jointly fine‑tuning the router for quantization‑aware routing, and exploring real‑time streaming scenarios where dynamic routing and quantization must be co‑optimized. VEQ thus provides a practical pathway to compress large MoE multimodal models without sacrificing their impressive capabilities.
Comments & Academic Discussion
Loading comments...
Leave a Comment