SFMP: Fine-Grained, Hardware-Friendly and Search-Free Mixed-Precision Quantization for Large Language Models
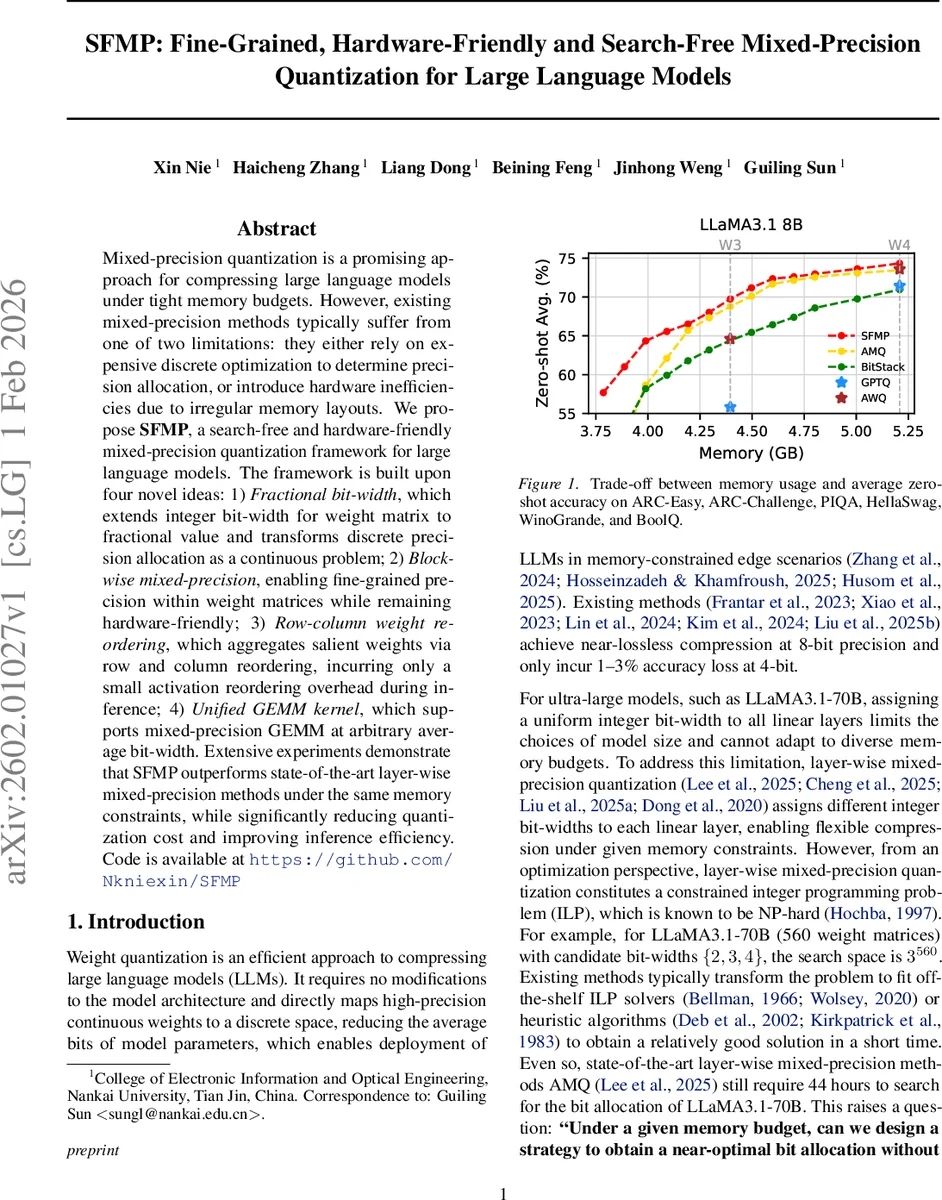
Mixed-precision quantization is a promising approach for compressing large language models under tight memory budgets. However, existing mixed-precision methods typically suffer from one of two limitations: they either rely on expensive discrete optimization to determine precision allocation, or introduce hardware inefficiencies due to irregular memory layouts. We propose SFMP, a search-free and hardware-friendly mixed-precision quantization framework for large language models. The framework is built upon four novel ideas: Fractional bit-width, which extends integer bit-width for weight matrix to fractional value and transforms discrete precision allocation as a continuous problem; 2)Block-wise mixed-precision, enabling fine-grained precision within weight matrices while remaining hardware-friendly; 3)Row-column weight reordering, which aggregates salient weights via row and column reordering, incurring only a small activation reordering overhead during inference; 4)Unified GEMM kernel, which supports mixed-precision GEMM at arbitrary average bit-width. Extensive experiments demonstrate that SFMP outperforms state-of-the-art layer-wise mixed-precision methods under the same memory constraints, while significantly reducing quantization cost and improving inference efficiency. Code is available at https://github.com/Nkniexin/SFMP
💡 Research Summary
SFMP (Search‑Free Mixed‑Precision) tackles the two major drawbacks of existing mixed‑precision quantization for large language models (LLMs): the need for costly discrete optimization to allocate bit‑widths under a memory budget, and the hardware inefficiencies caused by irregular memory layouts in fine‑grained schemes. The framework introduces four novel components that together enable a fast, accurate, and hardware‑friendly quantization pipeline.
-
Fractional Bit‑Width – Instead of forcing each weight matrix to use an integer bit‑width, SFMP treats the target average bit‑width b as a real number. The candidate set is reduced to the floor and ceiling of b (⌊b⌋, ⌈b⌉). Using a global salience map derived from a diagonal Fisher Information approximation, the method computes the α‑quantile τ_α (where α = b – ⌊b⌋) and assigns the higher bit‑width to the most salient weights, the lower one to the rest. This yields an optimal allocation without any ILP or heuristic search.
-
Block‑Wise Mixed‑Precision – To make the allocation hardware‑friendly, the weight matrix is partitioned into non‑overlapping 2‑D blocks of size (m_b, n_b). Block salience is defined as the sum of element‑wise salience within the block. The same τ_α threshold is applied at the block level, resulting in each block being quantized either with ⌊b⌋ or ⌈b⌉ bits. Block sizes (e.g., 256 × 128 or 512 × 128) are chosen to align with common GPU GEMM tiling strategies, ensuring regular memory access patterns and efficient parallelism.
-
Row‑Column Weight Reordering – Empirical analysis shows that salience tends to concentrate along rows or columns rather than forming compact blocks. To align high‑salience weights with the block structure, SFMP computes row‑wise and column‑wise salience sums, sorts them in descending order, and applies the resulting permutations to the weight matrix. The reordered matrix ˜W clusters salient elements into contiguous blocks, improving the effectiveness of block‑wise allocation. Reordering is performed offline; during inference the corresponding inverse permutations are applied to the activation matrix, incurring negligible overhead.
-
Unified Mixed‑Precision GEMM Kernel – The block‑wise format leads to weight tensors where each block may have a different bit‑width, but the overall average is fractional. SFMP implements a single GEMM kernel that handles this heterogeneity by decomposing each quantized block into binary (1‑bit) sub‑matrices and using a one‑bit lookup‑table (LUT) based GEMM. For a q‑bit block, the operation is expressed as a linear combination of q one‑bit GEMMs, each performed via LUT look‑ups and accumulations, eliminating runtime weight unpacking. This approach yields a unified compute path for any average bit‑width and dramatically reduces memory bandwidth consumption.
Experimental evaluation on LLaMA 3.1‑70B, LLaMA 3.1‑8B, and other LLMs demonstrates that, under identical memory budgets, SFMP consistently outperforms state‑of‑the‑art layer‑wise mixed‑precision methods such as AMQ. It achieves 1–2 % higher zero‑shot accuracy on benchmarks (ARC‑Easy, PIQA, HellaSwag, etc.) while delivering 30–50 % higher inference throughput. Moreover, the quantization process itself is accelerated from ~44 hours (search‑based) to under 0.15 hours, confirming the “search‑free” claim.
In summary, SFMP provides a practical solution for deploying ultra‑large LLMs on memory‑constrained devices. By converting the bit‑allocation problem into a simple salience‑driven thresholding, structuring the allocation at the block level, aligning salience through row‑column reordering, and executing everything with a unified LUT‑based GEMM kernel, the framework simultaneously optimizes model accuracy, memory efficiency, and hardware performance. This makes it a compelling candidate for real‑time inference on edge hardware where both storage and compute resources are limited.
Comments & Academic Discussion
Loading comments...
Leave a Comment