DR$^2$Seg: Decomposed Two-Stage Rollouts for Efficient Reasoning Segmentation in Multimodal Large Language Models
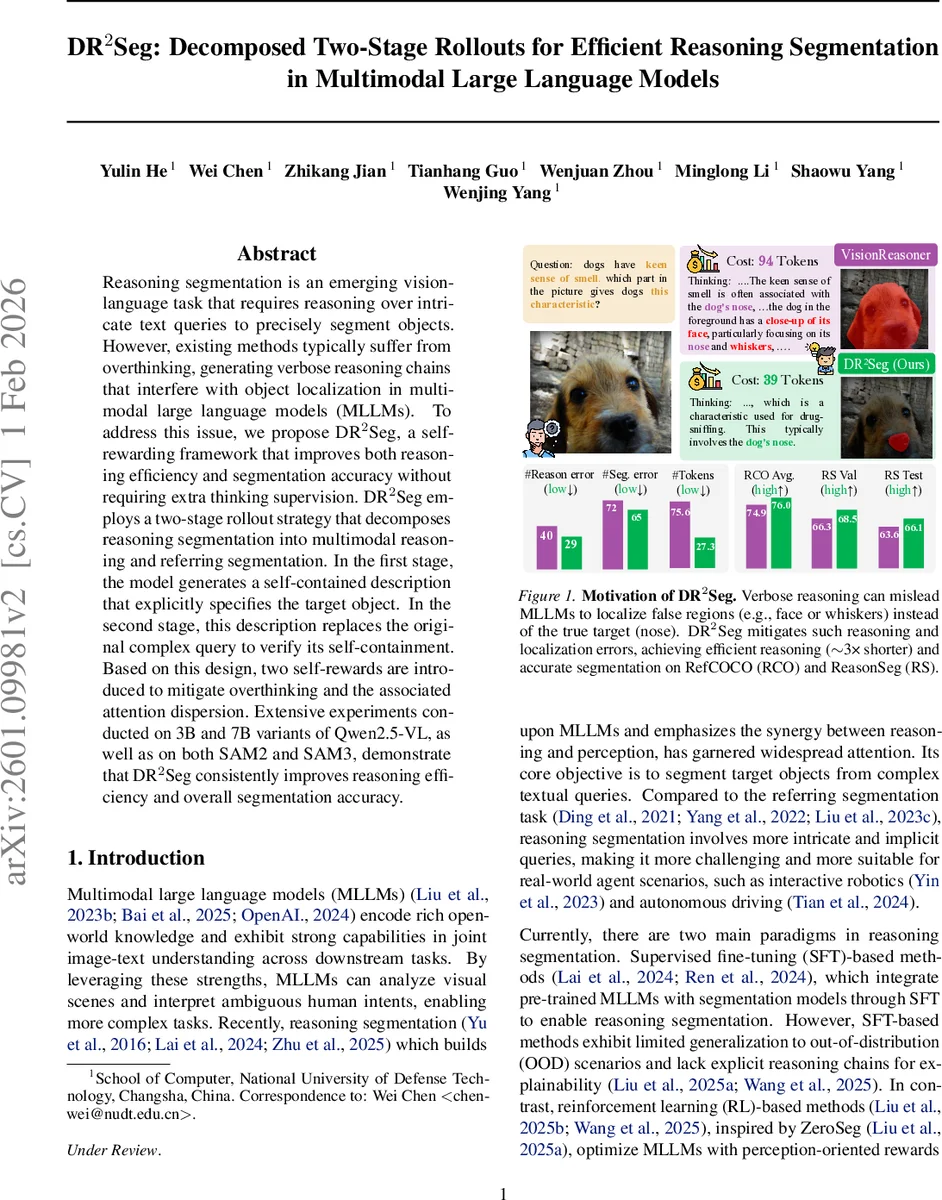
Reasoning segmentation is an emerging vision-language task that requires reasoning over intricate text queries to precisely segment objects. However, existing methods typically suffer from overthinking, generating verbose reasoning chains that interfere with object localization in multimodal large language models (MLLMs). To address this issue, we propose DR$^2$Seg, a self-rewarding framework that improves both reasoning efficiency and segmentation accuracy without requiring extra thinking supervision. DR$^2$Seg employs a two-stage rollout strategy that decomposes reasoning segmentation into multimodal reasoning and referring segmentation. In the first stage, the model generates a self-contained description that explicitly specifies the target object. In the second stage, this description replaces the original complex query to verify its self-containment. Based on this design, two self-rewards are introduced to mitigate overthinking and the associated attention dispersion. Extensive experiments conducted on 3B and 7B variants of Qwen2.5-VL, as well as on both SAM2 and SAM3, demonstrate that DR$^2$Seg consistently improves reasoning efficiency and overall segmentation accuracy.
💡 Research Summary
Reasoning segmentation, which asks multimodal large language models (MLLMs) to produce a segmentation mask from a free‑form textual query, has been hampered by “overthinking”: models generate long, verbose reasoning chains that waste compute and distract visual attention, leading to poorer object localization. DR²Seg (pronounced “DR2Seg”) tackles this problem with a pure self‑rewarding framework that requires no external expert model or extra supervision. The core idea is a two‑stage rollout. In the first rollout the model receives the image I and the original query Q and outputs a structured response consisting of a thinking chain R₁, a self‑contained description D that explicitly names the target object, and an answer A₁ (e.g., a point or bounding box). In the second rollout the original query is replaced by D alone; the model now produces a new thinking chain R₂ and an answer A₂. If A₂ matches the ground‑truth answer A*, the description D is deemed faithful and receives a description reward R_desc based on answer accuracy. This mechanism enforces that the description alone is sufficient for correct segmentation, effectively verifying the quality of the first‑stage reasoning.
A second self‑reward, the length‑based reward R_len, encourages concise reasoning. Token counts N₁=|R₁| and N₂=|R₂| are compared; if N₂<N₁ the model receives a positive reward, otherwise a penalty. To avoid trivial scaling (both N₁ and N₂ growing together), an absolute length anchor N₀ and a scaling factor γ are introduced, and the final reward is clipped to
Comments & Academic Discussion
Loading comments...
Leave a Comment