Latent Debate: A Surrogate Framework for Interpreting LLM Thinking
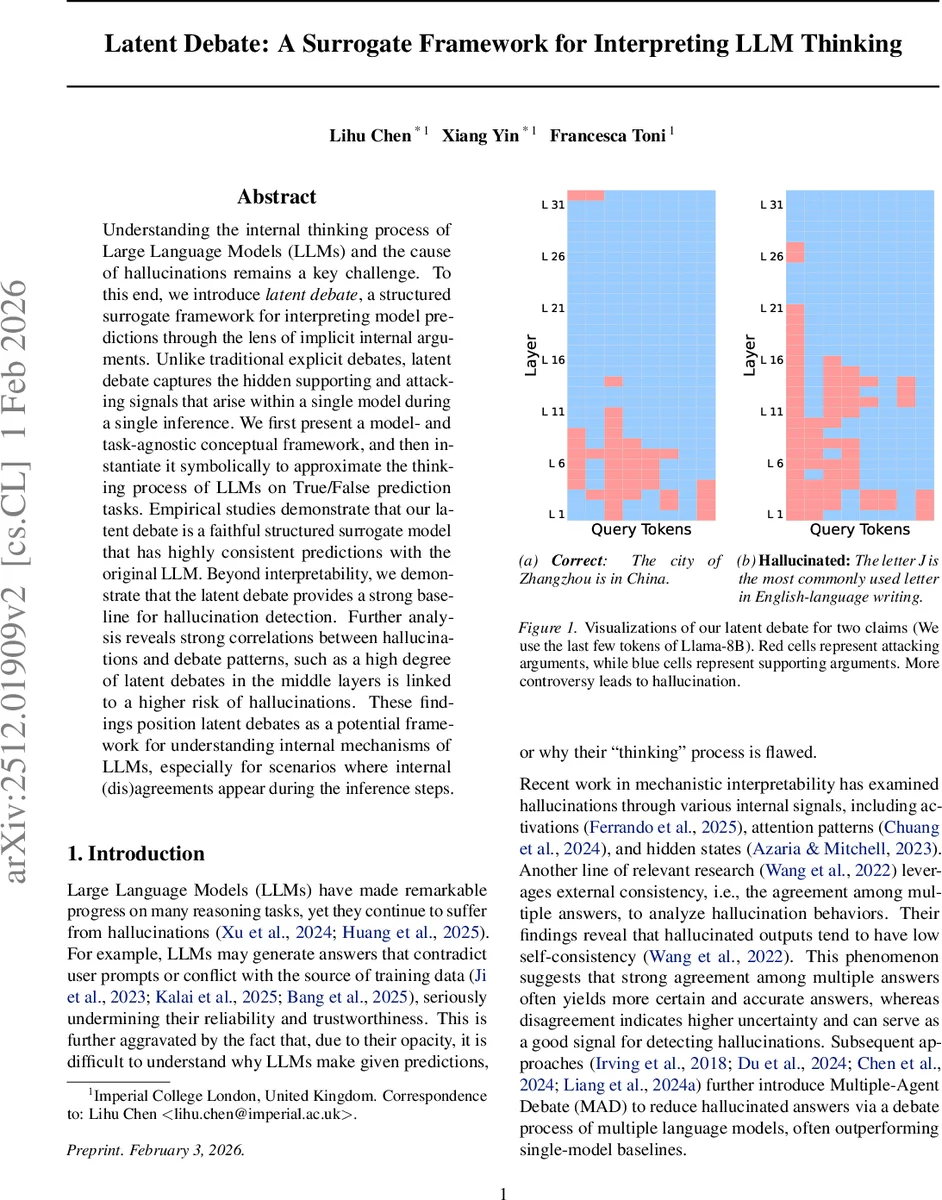
Understanding the internal thinking process of Large Language Models (LLMs) and the cause of hallucinations remains a key challenge. To this end, we introduce latent debate, a novel framework for interpreting model predictions through the lens of implicit internal arguments. Unlike the current work of self-consistency and multi-agent debate, which relies on explicit debates among multiple answers or multiple models, latent debate captures the hidden supporting and attacking signals that arise within a single model during a single inference. We first present a model- and task-agnostic conceptual framework, and then instantiate it symbolically to approximate the thinking process of LLMs on True/False prediction tasks. Empirical studies demonstrate that latent debate is a faithful structured surrogate model that has highly consistent predictions with the original LLM. Beyond interpretability, we demonstrate that latent debate provides a strong baseline for hallucination detection. Further analysis reveals strong correlations between hallucinations and debate patterns, such as a high degree of latent debates in the middle layers is linked to a higher risk of hallucinations. These findings position latent debate as a potential framework for understanding internal mechanisms of LLMs, especially for scenarios where internal (dis)agreements appear during the inference steps.
💡 Research Summary
Paper Overview
The authors introduce “latent debate,” a novel framework for interpreting the internal decision‑making of large language models (LLMs) by modeling hidden supporting and attacking signals that arise within a single inference pass. Unlike prior approaches such as self‑consistency or multi‑agent debate, which rely on multiple outputs or multiple models, latent debate treats the model’s own intermediate representations as “latent arguments” that implicitly argue for or against a claim. The framework consists of three abstract components: (1) latent arguments (raw internal signals), (2) an argument interpreter (maps latent arguments to human‑readable opinions), and (3) a thinking module (aggregates the interpreted arguments to produce a final decision).
Concrete Instantiation
The authors instantiate the framework for decoder‑based Transformers on binary True/False tasks. For each token of the input claim and for each hidden layer (except the final output layer), the hidden state (h^{(l)}n) is taken as a latent argument. The argument interpreter projects this hidden state into the vocabulary space using the unembedding matrix (W{\text{unemb}}) and applies a softmax over the two tokens “True” and “False”. The resulting probability difference is treated as an initial strength (\tau) in the interval (
Comments & Academic Discussion
Loading comments...
Leave a Comment