Mixtera: A Data Plane for Foundation Model Training
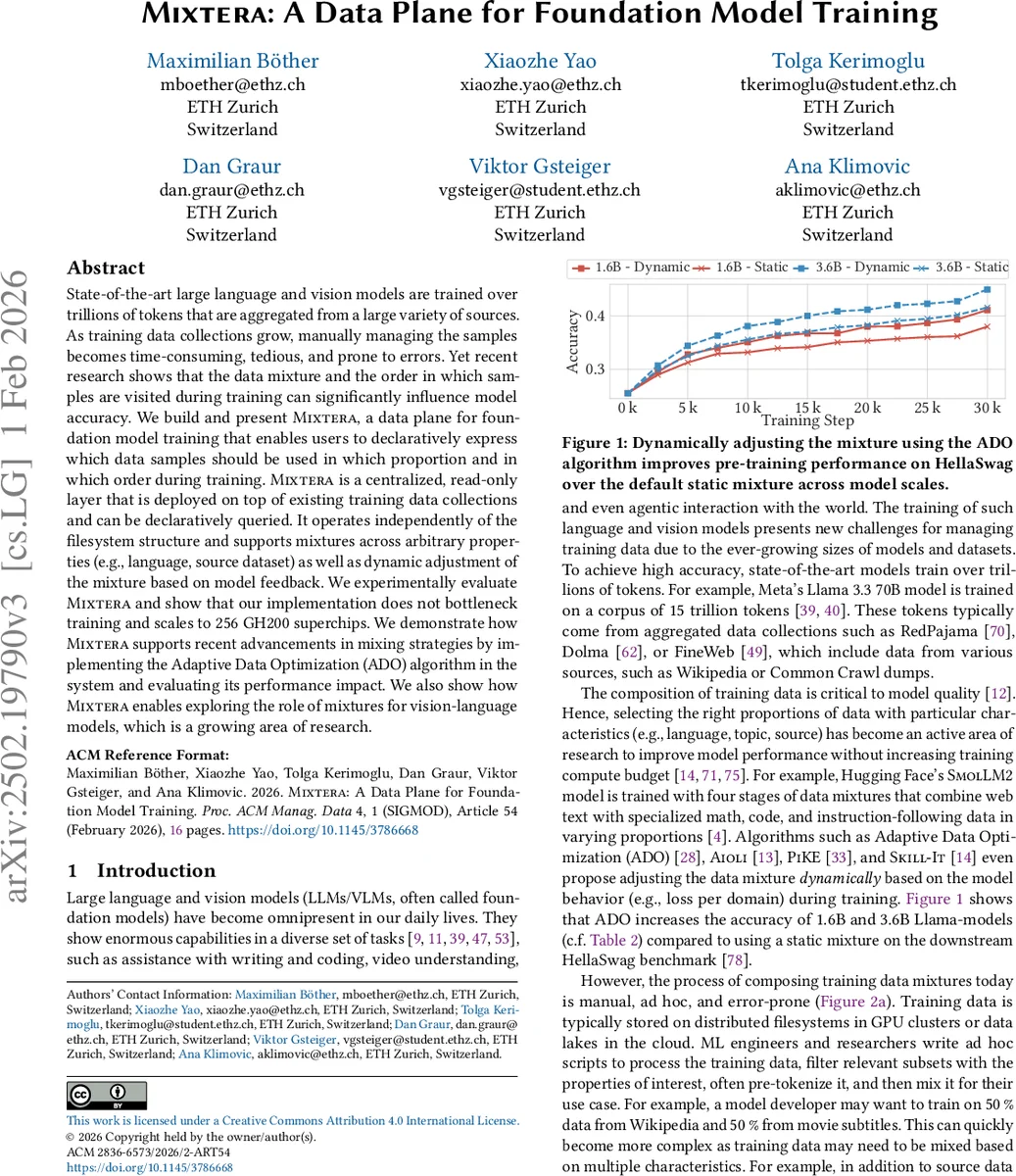
State-of-the-art large language and vision models are trained over trillions of tokens that are aggregated from a large variety of sources. As training data collections grow, manually managing the samples becomes time-consuming, tedious, and prone to errors. Yet recent research shows that the data mixture and the order in which samples are visited during training can significantly influence model accuracy. We build and present Mixtera, a data plane for foundation model training that enables users to declaratively express which data samples should be used in which proportion and in which order during training. Mixtera is a centralized, read-only layer that is deployed on top of existing training data collections and can be declaratively queried. It operates independently of the filesystem structure and supports mixtures across arbitrary properties (e.g., language, source dataset) as well as dynamic adjustment of the mixture based on model feedback. We experimentally evaluate Mixtera and show that our implementation does not bottleneck training and scales to 256 GH200 superchips. We demonstrate how Mixtera supports recent advancements in mixing strategies by implementing the proposed Adaptive Data Optimization (ADO) algorithm in the system and evaluating its performance impact. We also explore the role of mixtures for vision-language models.
💡 Research Summary
Mixtera addresses a critical bottleneck in the training of large language and vision models: the management and mixing of massive, heterogeneous data collections. Current open‑source pipelines rely on ad‑hoc scripts that filter and reorganize files on distributed file systems or cloud object stores. This approach is manual, error‑prone, incurs substantial storage overhead due to data duplication, and offers no declarative interface for specifying mixtures or tracking data lineage. Moreover, it cannot accommodate dynamic mixing strategies that adjust the data distribution during training based on model feedback.
The authors propose Mixtera, a read‑only data plane that sits on top of existing storage back‑ends. Mixtera follows a client‑server architecture. During a one‑time indexing phase the server scans the entire dataset and stores a compact metadata table for every sample (source, language, token count, quality scores, domain tags, etc.). At training time users submit declarative SPJ‑style queries that describe the desired mixture across arbitrary properties (e.g., “30 % Wikipedia‑en, 20 % CommonCrawl‑de, remainder other sources”). The server translates the query into fixed‑size “chunks” – lists of pointers to the selected samples – and streams these chunks to the training workers. Workers fetch the actual files on demand, eliminating the need to materialize a mixed copy of the data.
Key technical contributions include:
- Declarative mixture specification – Users can express complex, multi‑property mixtures without reorganizing the underlying file hierarchy.
- Dynamic mixture support – Mixtera can re‑evaluate the query on the fly using model‑generated signals (loss per domain, learning speed, etc.) and generate new chunks that reflect the updated distribution, all while the training job continues.
- Scalable chunk streaming – By decoupling metadata handling from raw data reads, Mixtera scales to the ingestion bandwidth required by 256 GH200 superchips (over a petabyte of data) with less than 2 % impact on overall training throughput.
- Broad format compatibility – It works with JSONL(.zst), Parquet, CSV, and WebDataset formats, preserving compatibility with existing data loaders.
The system is evaluated on two scales of Llama models (1.6 B and 3.6 B parameters). By integrating the Adaptive Data Optimization (ADO) algorithm—a recent dynamic mixing technique that fits a power‑law loss curve per domain and adjusts sampling probabilities accordingly—Mixtera demonstrates measurable accuracy gains on the HellaSwag benchmark (≈1.3 % and 1.5 % absolute improvement over a static mixture). Importantly, these gains are achieved without any noticeable slowdown; the data plane’s overhead remains negligible.
A comparative table shows that, unlike existing loaders (Hugging Face Datasets, Mosaic, Streaming), Mixtera uniquely supports dynamic mixtures on arbitrary properties, native 3‑D parallelism, and checkpoint‑friendly streaming. The authors also illustrate Mixtera’s applicability to vision‑language models, where mixtures can be defined simultaneously over image source and caption language, enabling balanced multimodal training.
Limitations are acknowledged: the initial metadata indexing step can be time‑consuming for petabyte‑scale corpora, and rare property values may lead to insufficient samples in a chunk, requiring additional re‑sampling logic. Future work will explore online index updates, cost‑aware re‑sampling strategies, and tighter integration with popular training frameworks such as DeepSpeed, Megatron‑LM, and TorchData.
In summary, Mixtera provides a practical, high‑performance data plane that abstracts away the complexities of data filtering, mixing, and dynamic adaptation for foundation model training. By offering a declarative interface, scalable chunk delivery, and seamless integration with existing pipelines, it reduces engineering effort, cuts storage costs, and enables researchers to experiment with sophisticated mixing algorithms—ultimately contributing to higher‑quality large‑scale models.
Comments & Academic Discussion
Loading comments...
Leave a Comment