Sample-Efficient Diffusion-based Control of Complex Physics Systems
Controlling complex physics systems is important in diverse domains. While diffusion-based methods have demonstrated advantages over classical model-based approaches and myopic sequential learning methods in achieving global trajectory consistency, t…
Authors: Hongyi Chen, Jingtao Ding, Jianhai Shu
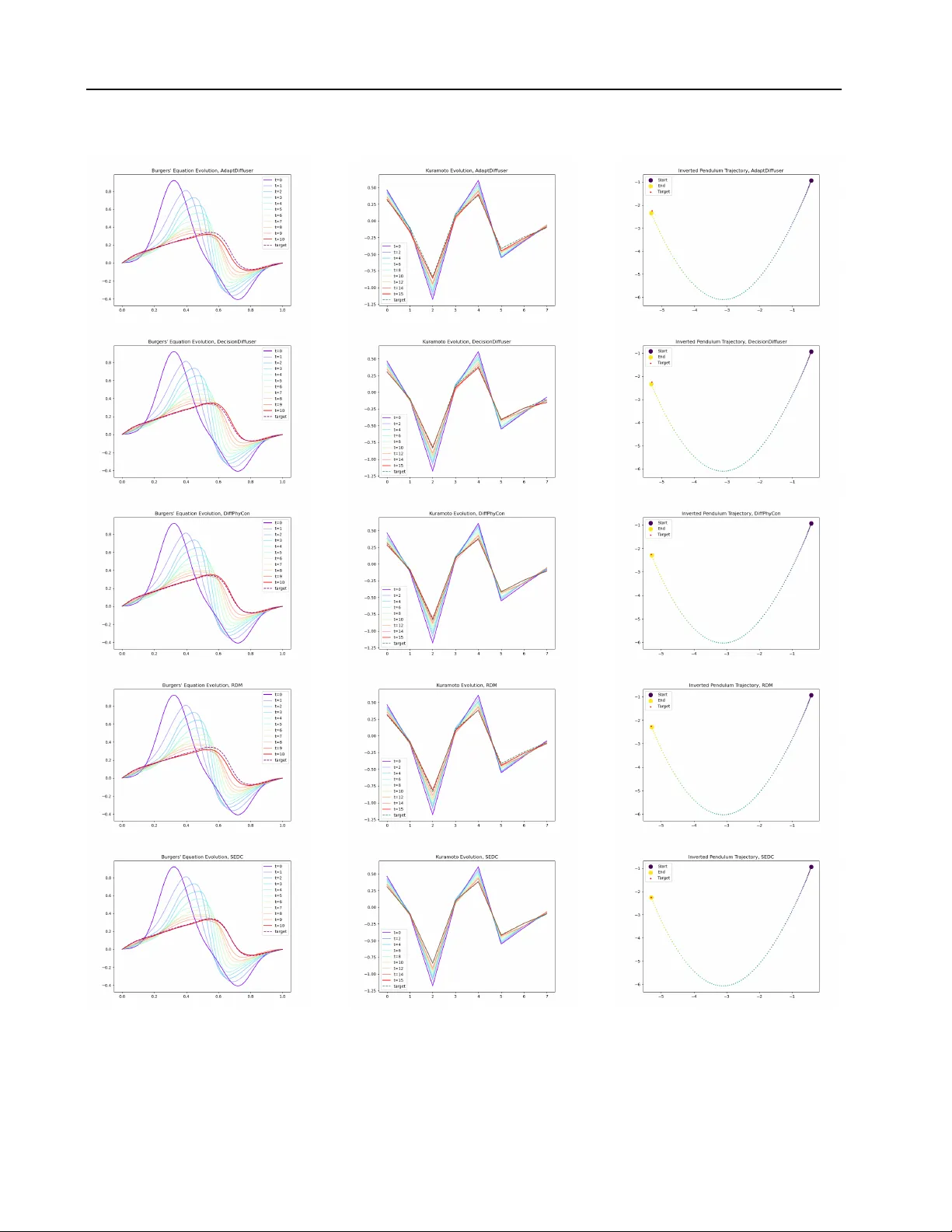
Sample-Efficient Diffusion-based Contr ol of Complex Physics Systems Hongyi Chen 1 2 Jingtao Ding 3 Jianhai Shu 3 Xinchun Y u 1 Xiaojun Liang 2 Y ong Li 3 Xiao-Ping Zhang 1 Abstract Controlling complex physics systems is impor - tant in div erse domains. While diffusion-based methods hav e demonstrated advantages o ver clas- sical model-based approaches and myopic sequen- tial learning methods in achie ving global trajec- tory consistency , they are limited by sample ef- ficiency . This paper presents SEDC (Sample- Ef ficient Diffusion-based Control), a nov el frame- work addressing core challenges in complex physics systems: high-dimensional state-control spaces, strong nonlinearities, and the gap between non-optimal training data and near -optimal con- trol laws. Our approach introduces a novel con- trol paradigm by architecturally decoupling state- control modeling and decomposing dynamics, while a guided self-finetuning process iterati vely refines the control law towards optimality . W e validate SEDC across div erse complex nonlinear systems, including high-dimensional fluid dynam- ics (Burgers), chaotic synchronization netw orks (Kuramoto), and real-world power grid stability control (Swing Equation). Our method achie v es 39.5%-47.3% better control accuracy than state- of-the-art baselines while using only 10% of the training samples. The implementation is av ailable at here . 1. Introduction The control of complex physics systems plays a critical role across di v erse domains, from industrial automation ( Bag- gio et al. , 2021 ) to biological networks ( Gu et al. , 2015 ). Giv en the challenges in deriving go verning equations for empirical systems, data-driv en control methods—which de- sign control modules directly based on experimental data collected from the system, bypassing the need for explicit mathematical modeling—hav e gained prominence for their 1 Shenzhen International Graduate School, Tsinghua Univer - sity , Shenzhen, China 2 Pengcheng Laboratory , Shenzhen, China 3 Department of EE, Beijing, China. Correspondence to: Jingtao Ding < dingjt15@tsinghua.org.cn > . Pr eprint. F ebruary 3, 2026. robust real-w orld applicability ( Baggio et al. , 2021 ; Janner et al. , 2022 ; Ajay et al. , 2022 ; Zhou et al. , 2024 ; Liang et al. , 2023 ; W ei et al. , 2024b ). T raditional Proportional-Integral-Deriv ative (PID) ( Li et al. , 2006 ) and Model Predictiv e Control (MPC) ( Schwenzer et al. , 2021 ) methods are limited in complex nonlinear sys- tems. PID controllers struggle with nonlinearities, while MPC’ s performance depends on model accuracy and is com- putationally intensiv e for long-horizon tasks. Data-driv en approaches hav e emerged to address these issues, including supervised learning, sequential learning approaches, and diffusion-based methods. Supervised trajectory fitting base- lines (e.g., BC ( Pomerleau , 1988 )) and sequential learning methods (e.g., BPPO ( Zhuang et al. , 2023 )) often make myopic, step-by-step decisions, leading to suboptimal out- comes in long-horizon tasks. In contrast, diffusion-based methods ( Janner et al. , 2022 ; Ajay et al. , 2022 ; Zhou et al. , 2024 ; Liang et al. , 2023 ; W ei et al. , 2024b ) treat control as a global trajectory generation problem. By generating the entire control plan in a single sample, they achie ve compre- hensiv e optimization over the full trajectory , av oiding the pitfalls of iterati ve methods and enabling superior long-term performance. The success of dif fusion models is dependent on their ability to learn complex trajectory distrib utions. Ho we ver , in prac- tice, the av ailable trajectory data is often non-optimal and sparse due to collection under empirical rules or random actuation and high operational costs. This presents a key challenge for dif fusion-based methods: synthesizing ef fec- tiv e control laws from limited and suboptimal data. First, limited data volume impedes sample-efficient modeling in high-dimensional physics systems. Existing diffusion- based controllers ( W ei et al. , 2024a ; b ; Hu et al. , 2025 ) at- tempt to directly generate long-term ( T steps) state-control trajectories by learning a T × ( P + M ) -dimensional distribu- tion of system states y P and control inputs u M . This joint distribution implicitly encodes system dynamics of state transitions under external control inputs, which often leads to ph ysically inconsistent trajectories when training samples are insufficient ( Janner et al. , 2022 ). Second, synthesiz- ing control laws f or nonlinear systems remains an open challenge both theoretically and practically . Traditional analytical methods ( Baggio et al. , 2021 ) designed for linear systems fail to perform rob ustly when applied to nonlinear 1 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems systems. While diffusion-based approaches ( Janner et al. , 2022 ; Ajay et al. , 2022 ; Zhou et al. , 2024 ; Zhong et al. , 2025 ; Hu et al. , 2025 ) employ deep neural networks (e.g., U-Net architectures) as denoising modules to capture nonlin- earity , synthesizing ef fecti ve control la ws from limited data remains particularly challenging for complex systems with strong nonlinearity , such as fluid dynamics ( Brunton et al. , 2020 ) and power grids ( Baggio et al. , 2021 ). Third, ex- tracting impro ved contr ol laws from non-optimal train- ing data poses fundamental difficulties. Diffusion-based methods ( Janner et al. , 2022 ) struggle when training data sig- nificantly deviates from optimal solutions. Although recent work ( W ei et al. , 2024b ) introduces reweighting mechanism to expand the solution space during generation, discov er - ing truly near-optimal control la ws remains elusi ve without explicit optimization guidance. T o address these challenges, we propose SEDC ( S ample- E fficient D if fusion-based C ontrol), a novel dif fusion-based frame work for synthesizing control laws of comple x physics systems with limited, non-optimal data. At its core, SEDC reformulates the control problem as a denoising diffusion process that samples control sequences optimized for reach- ing desired states while minimizing ener gy consumption. W e then solve the sample ef ficiency challenge by address- ing its three key aspects. T o address the curse of dimen- sionality , we introduce Decoupled State Diffusion (DSD), which simplifies the modeling complexity of the genera- tiv e task. By diffusing only on the more structured state space, rather than the complex joint state-control space, DSD achie ves higher sample ef ficiency . A separate in verse dynamics model is then used to ensure physical consistency . T o tackle strong nonlinearity , we propose Dual-Mode De- composition (DMD) by designing a dual-UNet denoising module with residual connections. This architecture decom- poses system dynamics into hierarchical linear and nonlin- ear components, enabling structured modeling of complex systems. T o bridge the gap between non-optimal training data and optimal control laws, we introduce the Guided Self-finetuning (GSF) mechanism, which progressively syn- thesizes guided control trajectories for iterati ve finetuning, facilitating manifold e xpansion beyond initial training data and con vergence to ward near-optimal control la ws. Our contributions are summarized as follo ws: • W e introduce a data-driv en framew ork that signifi- cantly enhances sample efficiency in controlling high- dimensional nonlinear systems via diffusion models. • Experiments on three complex nonlinear systems show that SEDC outperforms traditional, sequential, and diffusion-based baselines, achieving a 39.5%–47.3% im- prov ement in accuracy with a better accurac y-energy bal- ance. • SEDC matches top-tier performance using only 10% of training data. W e further demonstrate its scalability on 2D PDEs and robustness to non-in vertible systems. • W e confirm the method’ s computational efficienc y and provide extensiv e ablation studies to verify the specific contribution of each architectural component. 2. Related W ork Data-driv en control encompasses various paradigms, which can be broadly categorized by their approach to trajectory generation. One major paradigm is iterative, feedback-based contr ol . Classical methods like PID controllers ( Li et al. , 2006 ) operate via real-time error correction b ut face limita- tions in high-dimensional complex scenarios. More contem- porary approaches center on system identification, such as Dynamic Mode Decomposition ( T u , 2013 ) and Koopman operator theory ( Mauroy et al. , 2020 ). These methods first learn an explicit dynamics model from data and then de- sign a controller, often within a Model Predictiv e Control (MPC) frame work ( Schwenzer et al. , 2021 ). While robust for real-time adaptation, this two-stage paradigm is suscep- tible to compounding errors, particularly in sample-scarce settings. Inaccuracies in the learned model can accumulate ov er long horizons, degrading control performance. Sequen- tial learning approaches such as supervised trajectory fitting ( Pomerleau , 1988 ) and reinforcement learning ( Haarnoja et al. , 2018 ; Zhuang et al. , 2023 ) of fer adaptiv e methods but can struggle with long-horizon credit assignment and compounding errors due to their myopic, step-by-step na- ture ( Ross et al. , 2011 ). In contrast, global trajectory planning reframes control as a holistic generation problem, for which denoising dif fusion models ( Ho et al. , 2020 ; Dhariwal & Nichol , 2021 ; Kong et al. , 2020 ; Ho et al. , 2022 ) ha ve emerged as a po werful tool. By generating the entire control plan as a single, coherent sample, these methods capture long-term dependencies and av oid the pitfalls of iterativ e error accumulation. Seminal works ( Janner et al. , 2022 ; Ajay et al. , 2022 ) demonstrated this potential in robotics, but their generic architectures struggle with strong nonlinearities; our Dual-Mode Decom- position (DMD) architecture addresses this with a structured inducti ve bias. Subsequent research has tackled specific lim- itations. DiffPhyCon ( W ei et al. , 2024b ) uses re weighting to synthesize trajectories extending beyond the training distri- bution. This approach, howe ver , requires training separate denoising networks to model decomposed energy functions (one for the prior and one for the conditional distribution). Moreov er , its joint state-control modeling can exacerbate the curse of dimensionality , which our Decoupled State Diffu- sion (DSD) alleviates by dif fusing ov er the state space alone. T o bridge the data-optimality gap, AdaptDiffuser ( Liang et al. , 2023 ) fine-tunes on discriminator-filtered trajecto- ries, whereas our Guided Self-finetuning (GSF) employs 2 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems L i near ada pt i on Q uadr at i c adapt i on 1 - D U - net 1 - D U - net R es i dual C onnect i on Den o is er L inea r D enoi se r Tra ining In ve r se D ynam ic s R an d o m ly Sam p led T rai n D e c oupled S tate D if fusion Gui ded Self - F i netuni n g F o rw a rd D i f f use Inference D enoi se r In ve r se Dynam ics I npai nt i ng C ondi t i oni ng Input : st ar t and t ar get st at e … Si m ul a te fo r Ev a l ua t i o n G ui danc e D e c oupled S tate D if fusion D ua l - M ode D e c ompos it ion F in e tun e Data Pool A d d D at a P ool st at es co nt r ol s Data Pool SEDC I n f er en ce F igure 1. Ov ervie w of SEDC. The framework consists of a training/finetuning (top panel), inference process (middle panel) and finetuning process (bottom panel). The core denoising network employs our Dual-Mode Decomposition (DMD) architecture (right panel). Both training and inference lev erage Decoupled State Diffusion (DSD) by dif fusing only on states and using a separate in verse dynamics model to recov er controls. a simpler , filter-free loop. Beyond standard architectures, advanced approaches ha ve emerged to address specific phys- ical challenges—such as WDNO ( Hu et al. , 2024 ) for multi- resolution dynamics and SafeDif fCon ( Hu et al. , 2025 ) for safety constraints. Howe ver , these methods typically pri- oritize simulation fidelity or boundary satisfaction, rather than the sample-ef ficient synthesis of near-optimal control policies from sparse, suboptimal data. 3. Backgrounds 3.1. Problem Setting The dynamics of a controlled complex system can be repre- sented by the differential equation ˙ y t = Φ( y t , u t ) , where y t ∈ R N represents the system state and u t ∈ R M denotes the control input. W e assume the system satisfies the control- lability condition without loss of generality: for any initial state y ∗ 0 and target state y f , there exists a finite time T and a corresponding control input u that can drive the system from y ∗ 0 to y f . This assumption ensures the technical fea- sibility of our control objecti ves. In practical applications, beyond achieving state transitions, we need to optimize the energy consumption during the control process. The energy cost can be quantified using the L2-norm integral of the control input: J ( y , u ) = R T 0 | u ( t ′ ) | 2 dt ′ . Consider a dataset D = { u ( i ) , y ( i ) } P i =1 containing P non-optimal control trajectories, where each trajectory consists of: (1) complete state trajectories y ( i ) = y ( i ) 0 , ..., y ( i ) T sampled at fixed time interv als; (2) corresponding control input se- quences u ( i ) = u ( i ) 0 , ..., u ( i ) T − 1 . Our objective is satisfying the boundary constraint (reaching y f from y ∗ 0 ) and mini- mize the energy cost J ( y , u ) within the feasible solution space. Formally , this is a constrained optimization problem: min u J ( y , u ) s.t. y T = y f (T arget Satisfaction) , Ψ( u , y ) = 0 (Dynamics Consistency) , (1) where y ∈ R T × N is the corresponding complete state tra- jectory gi ven y 0 = y ∗ 0 . Ψ( u , y ) = 0 represents the system dynamics constraint implicitly defined by dataset D . This constraint effecti vely serves as a data-dri ven representation of the unknown dynamics equation ˙ y t = Φ( y t , u t ) . Our ke y idea is to train a dif fusion-based model to directly produce near-optimal control trajectories u [0: T − 1] , provid- ing a starting state y ∗ 0 , the target y f and optimized by the cost J . Next, we summarize the details of the diffusion- based framew ork. 3.2. Diffusion Model Diffusion models ha ve become the leading generativ e mod- els, showing exceptional results across image synthesis, audio generation and other applications ( Ho et al. , 2020 ; Dhariwal & Nichol , 2021 ; Song & Ermon , 2019 ). These models operate by progressiv ely adding noise to sequential 3 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems data in the forward process and then learning to reverse this noise corruption through a denoising process. W e formulate control as a conditional generative task. The forwar d pr o- cess progressiv ely corrupts a clean trajectory x 0 into Gaus- sian noise x K ∼ N ( 0 , I ) ov er K steps. The re verse pr o- cess learns a denoising network x θ to reconstruct the clean trajectory from noise, conditioned on system constraints (e.g., y ∗ 0 , y f ). Follo wing standard practices ( Janner et al. , 2022 ), we train the network to directly predict the clean trajectory ˆ x 0 at each step k by minimizing the simplified objectiv e: L ( θ ) = E k, x 0 ,ϵ || x 0 − x θ ( x k , k , y ∗ 0 , y f ) || 2 , where k ∼ U { 1 , . . . , K } is the diffusion step, and x k = √ ¯ α k x 0 + √ 1 − ¯ α k ϵ is the noisy input constructed from variance schedule ¯ α k . 4. SEDC: the Proposed Method 4.1. Controlling with Diffusion Models As shown in Figure 1 , SEDC reformulates the control prob- lem as a conditional trajectory generation task. The core idea is to train a diffusion model, conditioned on the initial y ∗ 0 and tar get y f states, to directly generate a complete state trajectory y [0: T ] . Subsequently , a corresponding control se- quence u [0: T − 1] is deriv ed from this state trajectory via a learned in verse dynamics model. Decoupled State Diffusion (DSD). Jointly modeling the state-control distribution is highly sample-intensiv e and risks generating physically inconsistent trajectories. T o ad- dress this, we propose Decoupled State Diffusion (DSD). As shown in Figure 1 , we confine the dif fusion process to the state trajectory y alone (i.e., x := y [0: T ] ), as state ev olution is generally smoother and more structured. The correspond- ing control sequence is then deriv ed from the generated state transitions via a separately trained inv erse dynamics model, f ϕ : ˜ u 0 t, update = f ϕ ( y 0 t , y 0 t +1 ) , where the superscript 0 denotes the final denoised output of the diffusion model. A common concern with deterministic in verse dynamics models f ϕ is the potential for averaging valid controls in multi-modal scenarios (where distinct actions yield identical transitions), leading to physically in valid actions. Howe ver , Unlike joint modeling state and control, which risks gener - ating out-of-distrib ution pairs, DSD ensures that the input to the in verse model ( y t , y t +1 ) is always dra wn from a valid, coherent manifold generated by the dif fusion model ( Chen et al. , 2025 ). Even in settings with control non-uniqueness, the in verse model is only tasked with finding a feasible control that satisfies this v alid transition, a significantly well-posed problem compared to unconstrained joint gener- ation. W e also ev aluate and discuss SEDC’ s robustness to non-in vertibility in Section 5.4 . W e then optimize f ϕ simultaneously with the denoiser . The loss function is: L ( θ , ϕ ) := E x ,k, y ∗ 0 , y f ,ϵ [ || x − x θ ( x k , k , y ∗ 0 , y f ) || 2 ] + E y t , u t , y t +1 [ || u t − f ϕ ( y t , y t +1 ) || 2 ] , (2) where y t , u t , y t +1 are sampled from the dataset. After train- ing, the denoising process generates a state trajectory y 0: T that is both physically plausible and conditioned on the start and target states. T o further refine this process, we intro- duce two key mechanisms: inpainting for hard constraint satisfaction and gradient guidance for soft optimization. T arget-Conditioning via Inpainting. T o ensure the gen- erated trajectory strictly adheres to the gi ven initial state y ∗ 0 and target state y f , we treat the problem as a form of trajectory inpainting. While these states are provided as conditions to the denoising network, we enforce them as hard constraints during the sampling process. Specifically , at each denoising step k , after sampling a potential trajec- tory x k − 1 ∼ p θ ( x k − 1 | x k , y ∗ 0 , y f ) , we replace its start and end points with the ground truth values: x k − 1 0 ← y ∗ 0 and x k − 1 T ← y f . This technique, analogous to inpainting in image generation ( Lugmayr et al. , 2022 ), guarantees that the final output satisfies the boundary conditions. Cost Optimization via Gradient Guidance. Beyond satis- fying the boundary constraints, we aim to find a trajectory that minimizes a gi ven cost function J (e.g., control energy). W e achiev e this through inference-time gradient guidance. Building upon the inpainting-enforced sampling, we further modify the mean of the denoising distrib ution by incorpo- rating the cost gradient: µ θ ( x k , k , y ∗ 0 , y f ) = √ ¯ α k − 1 β k 1 − ¯ α k ˆ x k + √ α k (1 − ¯ α k − 1 ) 1 − ¯ α k x k − λ Σ k ∇ x k J ( ˆ x k ( x k )) , (3) where λ controls guidance strength and the superscript k of ˆ x k := ˆ y k [0: T ] denotes the clean output from the denoiser at step k . Since our diffusion model operates on states only , we recover the control sequence ˜ u k t = f ϕ ( ˆ y k t , ˆ y k t +1 ) to com- pute the cost J ( u ) at each step. This combined approach of inpainting and guidance ensures the final generated trajec- tory is not only feasible and satisfies hard constraints but is also optimized for the desired cost objectiv e. 4.2. Dual-Mode Decomposition (DMD) for Denoiser In this section, we propose our denoising network design, DMD, that decomposes the modeling of linear and non- linear modes in the sampled trajectory by a dual-Unet ar- chitecture, as shown in Figure 1 . Our design draws inspi- ration from control theory . For linear systems, Y an et al. ( 2012 ) demonstrated that optimal control signals have a linear relationship with a specific linear combination y c of initial and target states. Building upon this insight, we dev elop a framework where a bias-free linear layer first learns this crucial linear combination y c from the initial 4 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems state y 0 and target state y f . Then, our module decomposes the prediction of the clean sampled trajectory into linear and nonlinear modes, ov ercoming the limitations of single- network approaches that struggle to model both simultane- ously . The theoretical foundation is as follows: y c is the conditional input, and our denoiser is designed to output the clean state trajectory ˆ x 0 , expressed as a v ector function f ( y c ) . It admits a vector T aylor expansion at y c = 0 as ˆ x 0 = f ( y c ) = C 1 y c + y T c C 2 y c + O ( || y c || 3 ) . For linear systems, only the first-order term remains. For nonlinear systems, by neglecting higher -order terms for simplicity , we can decompose the prediction into linear and nonlinear quadratic modes. This decomposition imposes a strong inductiv e bias: model- ing a dominant linear part and a subtle nonlinear correction is a more stable and sample-efficient task than forcing a monolithic network to learn the entire complex function from scratch. W e implement this with a dual-UNet architec- ture, as illustrated in Figure 1 . The network is conditioned on a vector y c = f c ([ y 0 , y f ]) ∈ R B × C 1 , which is gener- ated from the start and target states via a bias-less linear layer f c . Giv en the noisy trajectory x k ∈ R B × T × N and time em- bedding k emb , the first stage produces a linear prediction O 1 ∈ R B × T × N from first-order coefficients C 1 : C 1 = UNet 1 ( x k , k emb ) , O 1 = reshape ( C 1 ) · y c . (4) In the second stage, UNet 2 combines the input x k and inter- mediate features C 1 to generate quadratic coef ficients C 2 , which yield a nonlinear correction term O 2 ∈ R B × T × N : C 2 = UNet 2 ([ x k , C 1 ] , k emb ) , O 2 = y T c · reshape ( C 2 ) · y c . (5) The final denoised prediction is the sum of these compo- nents: ˆ x 0 = O 1 + O 2 ∈ R B × T × N . (6) Here, C 1 ∈ R B × T × ( N × C 1 ) and C 2 ∈ R B × T × ( C 1 × N × C 1 ) represent the learned coefficient tensors. 4.3. Guided Self-finetuning (GSF) Randomly generated training data cannot guarantee co ver - age of optimal scenarios. T o generate near-optimal controls that may deviate significantly from the training distribution, we propose le veraging the model’ s initially generated data (under the guidance of the cost function), which naturally deviat es from the training distrib ution tow ard optimality , for iterativ e retraining to systematically expand the manifold cov erage. This approach maintains physical consistency by ensuring generated samples adhere to the underlying system dynamics. As shown in Figure 1 , our methodology inv olves extract- ing control sequences from the generated samples (i.e., the output of in verse dynamics ˜ u 0 ) and reintroducing them into the ground-truth simulator (or the physical en vironment if accessible) to generate corresponding state sequences ˜ y 0 . While this introduces an online interaction component, it is highly practical in scientific control tasks (e.g., fluid dynamics) where forward simulation is possible but com- putationally expensi ve to run exhaustiv ely . GSF serves as a sample-ef ficient bridge between of fline initialization and optimal control. T ogether , we add the renewed [ ˜ u 0 , ˜ y 0 ] to the retrain data pool used for a new round of fine-tuning, notably without requiring explicit system parameter identi- fication. W e iterate this process over multiple rounds spec- ified by a hyperparameter , systematically expanding the model’ s manifold support to progressively approach the optimal control law . Denote the sampling process under cost J ’ s guidance and the follo wing interacting process as [ ˜ u 0 , ˜ y 0 ] = S ( x K , y ∗ 0 , y f , J, Φ) . The process can be formu- lated as: [ ˜ u 0 , ˜ y 0 ] = S ( x K , y ∗ 0 , y f ) ∼ D ( x K , y ∗ 0 , y f , J, Φ) , (7) D = [ D , [ ˜ u 0 , ˜ y 0 ]] , (8) where D is the training set and S ( x K , y ∗ 0 , y f , J, Φ) denotes the full process of generating a guided trajectory using cost J and then interacting with the system dynamics Φ to get the corresponding state sequence. W e provide the algorithm form of SEDC in Appendix A . 5. Experiments 5.1. Experiment Settings W e conducted experiments on multiple nonlinear physics systems, following the instructions in the previous works for data synthesis. These systems include: the 1-D Burgers dynamics ( Hw ang et al. , 2022 ; W ei et al. , 2024b ), which is a high-dimensionality (128-dim, significantly larger than stan- dard low-dimensional robotics benchmarks) dynamic sys- tem for studying nonlinear wa ve propagation and turb ulent fluid flow; the Kuramoto dynamics ( Acebr ´ on et al. , 2005 ; Baggio et al. , 2021 ; Gupta et al. , 2022 ), which is essential for understanding synchronization phenomena in complex networks and coupled oscillator systems; the in verted pendu- lum dynamics ( Boubaker , 2013 ), a classic nonlinear control baseline. T o further assess the scalability of our approach in extreme high-dimensional settings, we also e valuate SEDC on Jellyfish locomotion, a challenging 2D PDE control task in volving complex fluid-solid interactions (detailed in Ap- pendix G.2 ). For each system, we generated control/state trajectory data using the finite difference method and se- lected 50 trajectories as the test set. W e assume full state observability throughout the e xperiments. Detailed descrip- tions of the system dynamics equations and data synthesis procedures are provided in Appendix B . Implementation de- 5 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems 4 5 6 7 8 9 10 11 12 Ener gy (J) 1 0 4 1 0 3 1 0 2 1 0 1 T ar get L oss Bur gers PID BPPO B C RDM DecisionDiff DiffPhyCon A daptDiff Ours 1 0 3 1 0 2 1 0 1 Ener gy (J) 1 0 3 1 0 2 Inverted P endulum PID BPPO B C RDM DecisionDiff DiffPhyCon A daptDiff Ours 15.0 17.5 20.0 22.5 25.0 27.5 30.0 32.5 Ener gy (J) 1 0 5 1 0 4 1 0 3 1 0 2 1 0 1 1 0 0 K uramoto PID BPPO B C RDM DecisionDiff DiffPhyCon A daptDiff Ours F igure 2. Comparison of target loss and energy cost J across different datasets. The closer the data point is to the bottom left, the better the performance. 1% 5% 10% 20% 100% T raining Data P er centage 1 0 4 1 0 3 L oss V alue (log scale) Bur gers 1% 5% 10% 20% 100% T raining Data P er centage 1 0 3 Inverse P endulum 1% 5% 10% 20% 100% T raining Data P er centage 1 0 5 1 0 4 1 0 3 K uramoto DiffPhyCon DecisionDiff A daptDiffuser Ours F igure 3. Sample-efficiency comparison on Bur gers, Kuramoto and In verse Pendulum dynamics. tails and time consumption reports are provided in Appendix C . W e ev aluate two metrics which is crucial in complex sys- tem control: T arget Loss , the mean-squared-error (MSE) of y T and desired target y f , i.e. 1 N ∥ y T − y f ∥ 2 . (Note that y T is obtained by simulating the real system using the control inputs generated by each method, along with the giv en initial state conditions, rather than extracted from the sample trajectories of the dif fusion-based methods); Ener gy J = R T 0 | u ( t ′ ) | 2 dt ′ , which measures the cumulativ e control effort required to achie ve the target state. Lower v alues of both metrics indicate better performance. Baselines. W e ev aluate SEDC against two categories of control methods. Iterative Methods: we include the classical PID controller ( Li et al. , 2006 ) and data-dri ven sequential learning approaches, including Behavioral Cloning (BC) ( Pomerleau , 1988 ) and Batch Proximal Policy Optimization (BPPO) ( Zhuang et al. , 2023 ). Global Methods: we also compare against state-of-the-art diffusion-based methods that generate holistic plans: DecisionDiffuser (DecisionDiff) ( Ajay et al. , 2022 ), AdaptDiffuser (AdaptDif f) ( Liang et al. , 2023 ), RDM ( Zhou et al. , 2024 ), and Dif fPhyCon ( W ei et al. , 2024b ). These global methods av oid error accumulation by solving for the entire trajectory holistically . Detailed descriptions are included in Appendix D . 5.2. Overall Contr ol Perf ormance In Figure 2 , we compare different methods’ performance across three dynamical systems using tw o-dimensional co- ordinate plots, where proximity to the lo wer-left corner indicates better trade-offs between control accuracy and en- ergy ef ficiency . Since unstable control can lead to system failure regardless of energy efficiency , we prioritize con- trol accuracy and report metrics at each method’ s minimum T arget Loss. SEDC consistently achiev es state-of-the-art perf ormance. Our method secures the position closest to the origin in all three datasets, demonstrating the best balance between accu- racy and ef ficiency . Specifically , SEDC achiev es the lowest T arget Loss across all systems, outperforming the strongest baselines by 39.5%, 49.4%, and 47.3% in the Bur gers, Ku- ramoto, and IP systems, respecti vely . This highlights its superior capability in learning complex dynamics. In terms of energy cost, SEDC leads on the Kuramoto and IP systems and remains highly competitiv e on the Burgers system. Analysis of Baselines. The results rev eal clear performance tiers among different method f amilies. T raditional PID control shows the poorest performance, as system complex- ity exacerbates the dif ficulties in PID control and tuning. Sequential learning methods (e.g., BPPO) are competitiv e against some dif fusion-based approaches but sacrifice T ar- get Loss performance and underperform compared to global trajectory planning methods in other systems. Dif fusion- based methods demonstrate superior overall performance, as they better capture long-term dependencies in system dynamics compared to traditional and iterativ e sequential methods, av oiding myopic failure modes and facilitating global optimization of long-term dynamics. Due to space constraints, Appendices E and H provide de- tailed numerical results, including standard errors, Pareto frontier comparisons, and control dynamics visualizations. 6 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems T able 1. Ablation performance across datasets. T arget Loss at 10% and 100% training data is reported. Best/second-best/worst in each row are in bold /underlined/ italics . System Ratio Ours w/o DSD w/o DMD w/o GSF Burgers 10% 1.74e-4 1.00e-3 3.78e-4 6.67e-4 100% 9.80e-5 8.71e-4 2.28e-4 2.62e-4 Kuramoto 10% 1.12e-5 4.15e-3 5.21e-5 4.77e-5 100% 8.90e-6 5.43e-3 1.76e-5 3.88e-5 IP 10% 6.21e-4 1.58e-3 1.10e-3 2.00e-3 100% 3.49e-4 1.37e-3 6.64e-4 7.85e-4 A comparison with a data-dri ven MPC in Appendix G.1 further underscores the adv antages of our global planning approach. While our main experiments assume full-state observability , we validate SEDC’ s robustness to significant observation noise in Appendices G.6 . Furthermore, Ap- pendices G.2 validate the method’ s effecti veness on higher- dimensional physics systems. 5.3. Sample Efficiency T o ev aluate the sample efficienc y of diffusion-based meth- ods, we conducted experiments on all the systems using varying proportions of the full training dataset. Specifically , we trained models using 1%, 5%, 10%, 20%, and 100% of the av ailable data and assessed their performance using the T arget Loss metric on a held-out test set. Figure 3 demon- strates our method’ s superior performance in controlling Burgers and Kuramoto systems compared to state-of-the- art baselines. In all systems, our approach achiev es sig- nificantly lower target loss values across all training data percentages. Most notably , with only 10% of the training data, our method attains a target loss of 1.71e-4 for Burgers, 1.12e-5 for Kuramoto, and 6.35e-4 for Inv erse Pendulum, matching(-5.5% in Burgers) or exceeding(+36.4% in Ku- ramoto and +1.2% in In verse Pendulum) the performance of best baseline methods trained on the complete dataset. This indicates our method can achiev e state-of-the-art per - formance while requiring only 10% of the training samples. Among the baselines, DiffPhyCon’ s complex training re- quirement (Sec. 2 ) makes it particularly sample-inef ficient. While AdaptDiffuser’ s self-tuning improves upon Decision- Diffuser , SEDC’ s advantage stems from its ef ficient dynam- ics learning and a filter-free finetuning strategy . Unlike AdaptDiffuser , our GSF mechanism integrates all guided trajectories without discriminator filtering, promoting data div ersity and a better exploration-exploitation balance. 5.4. Ablation Study Overall ablation study . W e explore the main performance against each ablation of the original SEDC. Specifically , w/o DSD remov es the in verse dynamics, unifying the dif fusion of system state and control input, i.e. x = [ u , y ] . Therefore, 16 32 64 128 0 25 50 75 100 Er r or Decr ease (%) Bur gers Equation 4 5 6 7 8 State Dimension 99.0 99.2 99.4 99.6 99.8 100.0 Er r or Decr ease (%) K uramoto Model (a) Bur gers K uramoto 0 5 10 15 20 Ener gy Cost (J) 37.7% 13.0% 4.2% 2.0% GSF R ound Befor e GSF R ound 1 R ound 2 (b) F igure 4. Ablation analysis of SEDC components. (a) T arget Loss decrease rate of Decoupled State Diffusion (DSD), measured as the reduction relative to w/o DSD across state dimensions in Burgers and Kuramoto. (b) Energy cost ( J ) reduction o ver Guided Self-finetuning (GSF) rounds, with most gains in the first round and subsequent rounds indicating con vergence. the dif fusion model is required to simultaneously capture the temporal information and implicit dynamics of the control and system trajectory . Note that the inpainting mechanism and gradient guidance are retained. w/o DMD removes the decomposition design, resulting in a single 1-D Unet structure as the denoising network, following DecisionDif f. Finally , w/o GSF reports the performance without guided self-finetuning process, which means the model only uses the original dataset to train itself. T o sho w the sample- efficienc y performance, we also in vestigate the results under less amount of training sample(10%). For w/o DMD and w/o DSD , we adjust the number of trainable parameters at a comparable lev el against the original version. T able 1 shows the T arget Loss performance of different abla- tions of SEDC across multiple datasets and different training sample ratios. As can be seen, removing any component leads to a certain decrease in performance, whether the train- ing data is limited or not, demonstrating the effecti veness of each design. The most significant performance drops are often observed in w/o DSD , highlighting the importance of explicit learning of dynamics in complex systems. w/o DMD exhibits the lo west decline across the three systems. This is because the single-Unet-structured denoising network can already capture the nonlinearity to some e xtent, but not as good as the proposed decomposition approach. with 10% of training data, removing individual components still led to noticeable performance de gradation, and the patterns con- sistent with the full dataset results. This demonstrates that our designs remain effecti ve in lo w-data scenarios. Effectiveness of DSD. T o ev aluate DSD’ s effecti veness against the curse of dimensionality , we compared the per- formance of original and w/o DSD models across K uramoto systems with dimensions ranging from N = 4 to N = 8 . Experimental results (Figure 4a ) show that performance degradation from w/o DSD increases proportionally with 7 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems T able 2. Performance degradation using dif ferent denoiser output with varying nonlinearity strength γ in the Kuramoto system. γ 1 2 4 O 1 + O 2 8.90e-6 2.78e-5 3.89e-5 O 1 1.42e-5 4.73e-5 8.52e-5 Dec. (%) 37.3 41.2 54.3 system dimensionality , demonstrating DSD’ s enhanced ef- fecti veness in higher -dimensional systems and validating its capability to address dimensionality challenges. Further , we can observe that the decrease changes more rapidly with in- creasing dimensionality compared to Kuramoto, indicating that DSD exhibits heightened sensitivity to dimensional- ity in higher -dimensional systems. W e also in vestigate the effecti veness of dynamical learning in Appendix G.4 . Effectiveness of DMD. T o in vestigate the contrib ution of DMD’ s dual-Unet architecture to nonlinearity learning, we conducted experiments on the K uramoto system with vary- ing degrees of nonlinearity (controlled by the coefficient γ ∈ { 1 , 2 , 4 } of the nonlinear sinusoidal term, where larger values indicate stronger nonlinearity). W e compared the performance between using only the linear intermediate out- put ( ˆ x 0 = O 1 ) of the denoising network and the original nonlinear output ( ˆ x 0 = O 1 + O 2 ) in terms of T arget Loss. The Dec. indicates the reduction in target loss achiev ed by nonlinear output O 1 + O 2 compared to linear output O 1 . As sho wn in T able 2 , the magnitude of loss reduction increases proportionally with the nonlinearity strength γ , in- dicating that the quadratic term exhibits enhanced capability in capturing nonlinear dynamics as the system’ s nonlinear- ity intensifies. This comparison confirms that the nonlinear branch O 2 is essential for capturing dynamics as nonlin- earity ( γ ) increases. The superiority of the decomposition architecture itself is further e videnced in T able 1 , where w/o DMD shows consistently higher target loss. W e also show that DMD is suf ficient for modeling e ven higher-order dynamics in Appendix G.5 . Effectiveness of GSF . T o validate GSF’ s ability to refine the control law to wards lo wer energy cost, we tracked test-set energy consumption across finetuning rounds. As shown in Figure 4b , the first GSF round yields a dramatic im- prov ement ov er the initial model, reducing energy by 37.7% (Burgers) and 13.0% (K uramoto). Subsequent rounds of fer minor refinements (4.2% and 2.0% respectively), indicating con vergence to a near-optimal law . This confirms GSF ef fec- ti vely guides the model be yond its initial suboptimal training data to discov er more energy-ef ficient control solutions. Robustness to Non-inv ertibility . A critical question is whether DSD fails when multiple controls map to the same state transition (multi-modality). T o inv estigate this, we tested SEDC against the joint-diffusion baseline ( w/o DSD ) on a rank-deficient system where control is non-unique. w/o DSD SEDC 0.0 0.5 1.0 1.5 T ar get L oss 1e 2 R ank-Deficient System 0 1 2 3 Ener gy F igure 5. Comparison on a rank-deficient system showing SEDC’ s robustness to multi- modal control. Decision Diff RDM DiffPhy Con SEDC 0.00 0.01 0.02 0.03 0.04 0.05 0.06 T ar get L oss New England P ower Grid 0.00 0.05 0.10 0.15 0.20 0.25 0.30 Ener gy F igure 6. Stabilization per - formance on the 39-bus New England Grid comparing SEDC with diffusion baselines. Details can be found in Appendix G.3 . As shown in Figure 5 , SEDC outperforms the baseline by reducing T arget Loss by ov er 70%. W e attribute this success to task decomposition: joint baselines struggle to model the comple x multi-modal joint distribution p ( y , u ) , often leading to mode a veraging. In contrast, SEDC first generates a coherent state trajectory y 0: T . Conditioned on this v alid path, the in verse model f ϕ transforms the intractable joint generation problem into a simplified supervised task: identifying a feasible control (e.g., the smoothest one) that satisfies the transition. 5.5. Case Study Real-world Power Grid. T o validate scalability on real- world infrastructure, we applied SEDC to the 39-bus Ne w England power grid (Swing Equation) ( Baggio et al. , 2021 ), a real-world benchmark for post-fault stabilization (setup de- tails in Appendix F ). As shown in Figure 6 , SEDC achieves a 60.5% reduction in T ar get Loss compared to the strongest baseline (DecisionDif fuser) while maintaining lo wer energy cost. This significant margin demonstrates SEDC’ s superior ability to capture the highly coupled nonlinearities of power networks, where our global planning approach av oids the compounding errors typical of myopic methods in recov er - ing synchronous states. 6. Conclusion In this paper , we presented SEDC, a nov el sample-efficient diffusion-based frame work for complex nonlinear system control. By syner gistically inte grating Decoupled State Diffusion (DSD), Dual-Mode Decomposition (DMD), and Guided Self-finetuning (GSF), SEDC achie ves superior con- trol performance with remarkable data ef ficiency . Our e xper - iments show that SEDC can match state-of-the-art accuracy using just 10% of the training data. The framework’ s ro- bustness is further validated through rigorous testing on high-dimensional PDEs and real-world systems, confirm- ing the broad applicability and ef fectiv eness of our design principles. These results mark a significant advancement in developing practical and sample-efficient solutions for complex system control. 8 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems Impact Statement This paper presents work whose goal is to advance the field of Machine Learning. There are many potential societal consequences of our work, none which we feel must be specifically highlighted here. References Acebr ´ on, J. A., Bonilla, L. L., P ´ erez V icente, C. J., Ri- tort, F ., and Spigler , R. The kuramoto model: A simple paradigm for synchronization phenomena. Reviews of modern physics , 77(1):137–185, 2005. Ajay , A., Du, Y ., Gupta, A., T enenbaum, J., Jaakkola, T ., and Agra wal, P . Is conditional generative model- ing all you need for decision-making? arXiv pr eprint arXiv:2211.15657 , 2022. Baggio, G., Bassett, D. S., and P asqualetti, F . Data-driv en control of complex networks. Nature communications , 12(1):1429, 2021. Boubaker , O. The inv erted pendulum benchmark in non- linear control theory: a survey . International Journal of Advanced Robotic Systems , 10(5):233, 2013. Brunton, S. L., Noack, B. R., and K oumoutsakos, P . Ma- chine learning for fluid mechanics. Annual r eview of fluid mechanics , 52(1):477–508, 2020. Chen, H., Xu, J., Sheng, L., Ji, T ., Liu, S., Li, Y ., and Driggs-Campbell, K. Learning coordinated bimanual manipulation policies using state diffusion and in verse dynamics models. In 2025 IEEE International Confer- ence on Robotics and A utomation (ICRA) , pp. 5644–5651. IEEE, 2025. Dhariwal, P . and Nichol, A. Diffusion models beat gans on image synthesis. Advances in neural information pr ocessing systems , 34:8780–8794, 2021. Gu, S., Pasqualetti, F ., Cieslak, M., T elesford, Q. K., Y u, A. B., Kahn, A. E., Medaglia, J. D., V ettel, J. M., Miller , M. B., Grafton, S. T ., et al. Controllability of struc- tural brain networks. Nature communications , 6(1):8414, 2015. Gupta, J., V emprala, S., and Kapoor , A. Learning modular simulations for homogeneous systems. Advances in Neu- ral Information Pr ocessing Systems , 35:14852–14864, 2022. Haarnoja, T ., Zhou, A., Abbeel, P ., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforce- ment learning with a stochastic actor . In International confer ence on machine learning , pp. 1861–1870. PMLR, 2018. Ho, J., Jain, A., and Abbeel, P . Denoising diff usion proba- bilistic models. Advances in neural information pr ocess- ing systems , 33:6840–6851, 2020. Ho, J., Salimans, T ., Gritsenko, A., Chan, W ., Norouzi, M., and Fleet, D. J. V ideo diffusion models. Advances in Neural Information Pr ocessing Systems , 35:8633–8646, 2022. Hu, P ., W ang, R., Zheng, X., Zhang, T ., Feng, H., Feng, R., W ei, L., W ang, Y ., Ma, Z.-M., and W u, T . W avelet dif fu- sion neural operator . arXiv pr eprint arXiv:2412.04833 , 2024. Hu, P ., Qian, X., Deng, W ., W ang, R., Feng, H., Feng, R., Zhang, T ., W ei, L., W ang, Y ., Ma, Z.-M., et al. From un- certain to safe: Conformal fine-tuning of dif fusion models for safe pde control. arXiv pr eprint arXiv:2502.02205 , 2025. Hwang, R., Lee, J. Y ., Shin, J. Y ., and Hwang, H. J. Solving pde-constrained control problems using operator learn- ing. In Pr oceedings of the AAAI Conference on Artificial Intelligence , v olume 36, pp. 4504–4512, 2022. Janner , M., Du, Y ., T enenbaum, J. B., and Levine, S. Plan- ning with diffusion for flexible beha vior synthesis. arXiv pr eprint arXiv:2205.09991 , 2022. K ong, Z., Ping, W ., Huang, J., Zhao, K., and Catanzaro, B. Dif fwa ve: A v ersatile diffusion model for audio synthesis. arXiv pr eprint arXiv:2009.09761 , 2020. Li, Y ., Ang, K. H., and Chong, G. C. Pid control system analysis and design. IEEE Contr ol Systems Magazine , 26 (1):32–41, 2006. Liang, Z., Mu, Y ., Ding, M., Ni, F ., T omizuka, M., and Luo, P . Adaptdiffuser: Diffusion models as adaptive self-ev olving planners. arXiv pr eprint arXiv:2302.01877 , 2023. Lugmayr , A., Danelljan, M., Romero, A., Y u, F ., Timofte, R., and V an Gool, L. Repaint: Inpainting using denoising diffusion probabilistic models. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pp. 11461–11471, 2022. Mauroy , A., Susuki, Y ., and Mezic, I. K oopman operator in systems and contr ol , volume 7. Springer , 2020. Pomerleau, D. A. Alvinn: An autonomous land vehicle in a neural network. Advances in neural information pr ocessing systems , 1, 1988. Ross, S., Gordon, G., and Bagnell, D. A reduction of imita- tion learning and structured prediction to no-re gret online learning. In Pr oceedings of the fourteenth international 9 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems confer ence on artificial intellig ence and statistics , pp. 627–635. JMLR W orkshop and Conference Proceedings, 2011. Schwenzer , M., A y , M., Ber gs, T ., and Abel, D. Revie w on model predictiv e control: An engineering perspecti ve. The International J ournal of Advanced Manufacturing T echnology , 117(5):1327–1349, 2021. Song, Y . and Ermon, S. Generativ e modeling by estimating gradients of the data distribution. Advances in Neural Information Pr ocessing Systems , 32, 2019. T u, J. H. Dynamic mode decomposition: Theory and appli- cations . PhD thesis, Princeton University , 2013. W ei, L., Feng, H., Y ang, Y ., Feng, R., Hu, P ., Zheng, X., Zhang, T ., Fan, D., and Wu, T . Cl-diffphycon: Closed- loop dif fusion control of complex physical systems. arXiv pr eprint arXiv:2408.03124 , 2024a. W ei, L., Hu, P ., Feng, R., Feng, H., Du, Y ., Zhang, T ., W ang, R., W ang, Y ., Ma, Z.-M., and W u, T . A generativ e approach to control complex physical systems. arXiv pr eprint arXiv:2407.06494 , 2024b. Y an, G., Ren, J., Lai, Y .-C., Lai, C.-H., and Li, B. Con- trolling complex networks: Ho w much energy is needed? Physical r eview letters , 108(21):218703, 2012. Zhong, H., Xie, H., W ang, S., and Y ong, H. Constrained control of the radiativ e transport equation: A nov el ap- proach based on the frozen diffusion model. Computer Physics Communications , pp. 109777, 2025. Zhou, S., Du, Y ., Zhang, S., Xu, M., Shen, Y ., Xiao, W ., Y eung, D.-Y ., and Gan, C. Adapti ve online replanning with dif fusion models. Advances in Neural Information Pr ocessing Systems , 36, 2024. Zhuang, Z., Lei, K., Liu, J., W ang, D., and Guo, Y . Be- havior proximal policy optimization. arXiv pr eprint arXiv:2302.11312 , 2023. 10 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems A. Algorithm f orm of SEDC Algorithm 1 SEDC: T raining and finetuning Input: Initial dataset D 0 , diffusion steps K , guidance strength λ , self-finetuning rounds R , forward dynamics f forward Output: Optimized trajectory y 0 0: T , controls u 0 0: T Function Initial T raining( D 0 ) while not con verg ed do Sample batch ( y 0: T , u 0: T ) ∼ D 0 Sample k ∼ U { 1 , ..., K } , ϵ ∼ N (0 , I ) Corrupt states: y k = √ ¯ α k y + √ 1 − ¯ α k ϵ Predict clean states: ˆ y k = G θ ( y k , k , y ∗ 0 , y f ) Predict controls: ˜ u t = f ϕ ( y t , y t +1 ) Compute losses: L diff = ∥ y − ˆ y k ∥ 2 L in v = ∥ u t − ˆ u t ∥ 2 Update θ , ϕ with ∇ ( L diff + L in v ) for r = 1 to R do Guided Data Generation: Initialize y K ∼ N (0 , I ) , sample ( y ∗ 0 , y f ) ∼ D r − 1 for k = K do wnto 1 do Predict ˆ y k = G θ ( y k , k , y ∗ 0 , y f ) Compute gradient: g = ∇ y k J ( ˜ y k , ˆ u k ) , where ˜ u k t = f ϕ ( ˆ y k t , ˆ y k t +1 ) Adjust mean: µ θ = µ (base) θ − λ Σ k g Sample y k − 1 ∼ N ( µ θ , Σ k I ) Enforce constraints: y k − 1 0 ← y ∗ 0 , y k − 1 T ← y f Recov er controls: ˜ u 0 t = f ϕ ( y 0 t , y 0 t +1 ) System Interaction: Generate ˜ y 0 [0: T ] = f forward ( ˜ u 0 [0: T ] , y ∗ 0 ) Augment dataset: D r = D r − 1 ∪ { ( ˜ y 0 [0: T ] , ˜ u 0 [0: T ] } Adaptive Fine-tuning: while validation loss decr eases do Sample batch from D r Perform training steps as in Initial T raining retur n Optimized θ , ϕ (T est pr ocess follows guided data generation with test conditions ( y ∗ 0 , y f ) pr ovided.) B. Detailed System and Dataset Description B.1. Overall Intr oduction Our benchmark selection (In verted Pendulum, Kuramoto, and Burgers) follows established control systems research practice, chosen for real-world rele vance and di verse nonlinearity and comple xity: • In verted Pendulum: state 2, control 1, timestep 128 • Kuramoto: state 8, control 8, timestep 15 • Burgers: state 128, control 128, timestep 10 B.2. Burgers Dynamics The Burgers’ equation is a governing la w occurring in various physical systems. W e consider the 1D Burgers’ equation with the Dirichlet boundary condition and external control input u ( t, x ) : 11 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems ∂ y ∂ t = − y · ∂ y ∂ x + ν ∂ 2 y ∂ x 2 + u ( t, x ) in [0 , T ] × Ω y ( t, x ) = 0 on [0 , T ] × ∂ Ω y (0 , x ) = y 0 ( x ) in { t = 0 } × Ω Here ν is the viscosity parameter , and y 0 ( x ) is the initial condition. Subject to these equations, giv en a target state y d ( x ) , the objectiv e of control is to minimize the control error J actual between y T and y d , while constraining the energy cost J energy of the control sequence u ( t, x ) . W e follow instructions in W ei et al. ( 2024b ) to generate a 1D Burgers’ equation dataset. Specifically , for numerical simulation, we discretized the spatial domain [0,1] and temporal domain [0,1] using the finite dif ference method (FDM). The spatial grid consisted of 128 points, while the temporal domain was divided into 10000 timesteps. W e initiated the system with randomly sampled initial conditions and control inputs drawn from specified probability distributions. This setup allowed us to generate 90000 trajectories for training and 50 trajectories for testing purposes. B.3. Kuramoto Dynamics The Kuramoto model is a paradigmatic system for studying synchronization phenomena. W e considered a ring network of N = 8 Kuramoto oscillators. The dynamics of the phases (states) of oscillators are expressed by: ˙ θ i,t = ω + γ (sin( θ i − 1 ,t − 1 − θ i,t − 1 ) + sin( θ i +1 ,t − 1 − θ i,t − 1 )) + u i,t − 1 , i = 1 , 2 , ..., N . (9) For the Kuramoto model, we generated 20,000 samples for training and 50 samples for testing. The initial phases were sampled from a Gaussian distrib ution N (0 , I ) , and the random interv ention control signals were sampled from N (0 , 2 I ) . The system was simulated for T = 16 time steps with ω = 0 , following Baggio et al. ( 2021 ). The resulting phase observations and control signals were used as the training and test datasets. B.4. In verted Pendulum Dynamics The in verted pendulum is a classic nonlinear control system. The dynamics can be represented by: d 2 θ dt 2 = g L sin( θ ) − µ L dθ dt + 1 mL 2 u where θ is the angle from the upward position, and u is the control input torque. The system parameters are set as: gravity g = 9 . 81 m/s², pendulum length L = 1 . 0 m, mass m = 1 . 0 kg, and friction coef ficient µ = 0 . 1 . T o generate the training dataset, we simulate 90,000 trajectories for training and 50 for testing with 128 time steps each, using a time step of 0.01s. For each trajectory , we randomly sample initial states near the unstable equilibrium point with θ 0 ∼ U ( − 1 , 1) and ˙ θ 0 ∼ U ( − 1 , 1) , and generate control inputs from u ∼ U ( − 0 . 5 , 0 . 5) . The resulting dataset contains the state trajectories and their corresponding control sequences. C. Implementation Details C.1. Implementation of SEDC In this section, we describe various architectural and h yperparameter details: • The temporal U-Net (1D-Unet) ( Janner et al. , 2022 ) in the denoising network consists of a U-Net structure with 4 repeated residual blocks. Each block comprises two temporal con volutions, follo wed by group normalization, and a final Mish nonlinearity . The channel dimensions of the downsample layers are 1 , 2 , 4 ∗ statedimension . Timestep embedding is produced by a Sinusoidal Positional Encoder , following a 2-layer MLP , and the dimension of this embedding is 32. The dimension of condition embedding is the same as the system state dimension. • W e represent the in verse dynamics f ϕ with an autoregressi ve model with 64 hidden units and ReLU acti vations. The model autoregressi vely generates control outputs along the control dimensions. 12 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems • W e train x θ and f ϕ using the Adam optimizer with learning rates from { 1e-3, 5e-3, 1e-4 } . The exact choice v aries by task. Moreover , we also use a learning rate scheduler with step factor=0.1. Training batch size is 32. • W e use K = 128 diffusion steps. • W e use a guidance scale λ ∈ { 0 . 01 , 0 . 001 , 0 . 1 } but the exact choice v aries by task. C.2. T raining and Inference Time Analysis T able 3. Approximate Training T ime Comparison of Different Models on V arious Datasets (in hours) Dataset/System DecisionDiffuser RDM DiffPhyCon AdaptDiffuser SEDC Burgers 2.5 2.5 3.0 2.5 2.5 Kuramoto 1.5 1.5 1.5 1.0 1.0 IP 1.0 1.0 1.5 1.0 0.5 T able 4. Approximate Inference Time Comparison of Dif ferent Models on V arious Datasets (in seconds) Dataset/System DecisionDiffuser RDM DiffPhyCon AdaptDiffuser SEDC Burgers 3.0 4.0 6.0 4.0 4.0 Kuramoto 1.0 1.5 2.0 1.5 1.5 IP 0.5 1.0 1.0 0.5 0.5 The dif fusion-based methods are trained on single NVIDIA GeForce R TX 4090 GPU. W e ev aluate the training and inference time of all the diffusion-based methods e valuated in the experiment session. As shown in T able 3 , we compare the training efficienc y of different models across v arious datasets. DiffPhyCon consistently shows longer training times compared to other methods, because it requires training two models that learn the joint distribution and the prior distrib ution respectiv ely , increasing its training time consumption. The training times of DecisionDiffuser , RDM, and AdaptDif fuser are generally comparable, while SEDC demonstrates relativ ely ef ficient training performance across most datasets. This may be because of the proposed designs that not only improv e sample ef ficiency b ut also improve learning ef ficiency . The inference time comparison in T able 4 reveals that Dif fPhyCon requires longer execution time compared to other models, because it needs to sample from two learned distrib utions in the denoising process. RDM achie ves relati vely slower inference speeds than DecisionDiffuser , AdaptDiffuser , and SEDC, because RDM replans during inference, increasing planning time. Notably , all models exhibit shorter training and inference times on the IP dataset, suggesting the influence of system complexity on computational ef ficiency . D. Baselines Description D.1. PID PID (Proportional-Integral-Deri vati ve) control is a classical feedback control methodology that has been widely adopted in industrial applications. The control signal is generated by computing the weighted sum of proportional, integral, and deriv ativ e terms of the error . The control law can be e xpressed as: u ( t ) = K p e ( t ) + K i Z t 0 e ( τ ) dτ + K d d dt e ( t ) While PID controllers exhibit robust performance and require minimal system modeling, their effecti veness may be compromised when dealing with highly nonlinear or time-varying systems, necessitating frequent parameter tuning. D.2. BC, BPPO Behavior Cloning (BC) represents a supervised imitation learning paradigm that aims to learn a direct mapping from states to actions by minimizing the de viation between predicted actions and expert demonstrations. Despite its implementation 13 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems simplicity and sample ef ficiency , BC suffers from distrib utional shift, where performance degradation occurs when encountering states outside the training distribution. The objectiv e function can be formulated as: L B C ( θ ) = E ( s,a ) ∼D [ − log π θ ( a | s )] where D denotes the expert demonstration dataset. Behavior -guided PPO (BPPO) presents a hybrid approach that integrates behavior cloning with Proximal Policy Optimization. By incorporating a behavioral cloning loss term into the PPO objectiv e, BPPO facilitates more efficient policy learning while maintaining the exploration capabilities inherent to PPO. The composite objecti ve function is defined as: L B P P O ( θ ) = L P P O ( θ ) + αL B C ( θ ) where α serves as a balancing coef ficient between the PPO and BC objectives. Each method exhibits distinct characteristics: BC demonstrates effecti veness when abundant high-quality expert demonstra- tions are av ailable. BPPO le verages the syner gy between expert kno wledge and reinforcement learning for complex control scenarios. D.3. Diffusion-based methods • DecisionDiffuser: A nov el approach that reformulates sequential decision-making as a conditional generativ e modeling problem rather than a reinforcement learning task. The core methodology inv olves modeling policies as return-conditional dif fusion models, enabling direct learning from data without dynamic programming. The model can be conditioned on various factors including constraints and skills during training. • DiffPhyCon: A diffusion-based method for controlling physical systems that operates by jointly optimizing a learned generativ e energy function and predefined control objecti ves across entire trajectories. The approach incorporates a prior re weighting mechanism to enable e xploration be yond the training distribution, allowing the discov ery of di verse control sequences while respecting system dynamics. • AdaptDiffuser: An e volutionary planning framework that enhances diffusion models through self-ev olution. The method generates synthetic expert data using rew ard gradient guidance for goal-conditioned tasks, and employs a discriminator -based selection mechanism to identify high-quality data for model fine-tuning. This approach enables adaptation to both seen and unseen tasks through continuous model improv ement. • RDM: A replanning framew ork for dif fusion-based planning systems that determines replanning timing based on the diffusion model’ s likelihood estimates of existing plans. The method introduces a mechanism to replan existing trajectories while maintaining consistency with original goal states, enabling ef ficient bootstrapping from previously generated plans while adapting to dynamic en vironments. E. Detailed Results of Figure 2 W e lev erage 2-D plots in the main paper to better illustrate the performance comparison of all the methods. Here we provide the provides the corresponding numerical results in detail in T able 5 and pareto frontiers in Fig 7 . Results confirm our method maintains competitiv e performance across all datasets. F . P ower Grid Swing Dynamics Details In Section 5.5 , we presented comparative results on the power grid swing dynamics. Here we provide the specific experimental configuration. 14 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems T able 5. Performance comparison of different models acr oss three datasets. TL (T arget Loss) and J (Energy) are reported, with lower values indicating better performance for both metrics. W e report the mean and the standard error ov er 5 random seeds. Following pre vious work(e.g. Ajay et al. ( 2022 )), we highlight the best-performed results in bold . Model Burgers Kuramoto IP TL J TL J TL J PID 1.30e-1 6.56 7.99e-1 30.35 8.64e-3 2.28e-1 BPPO 5.90e-4 9.72 1.56e-4 26.64 3.63e-3 4.16e-3 BC 4.78e-4 10.73 1.52e-4 27.59 3.63e-3 4.20e-3 DecisionDiff 2.46e-4 5.18 3.88e-5 27.48 6.65e-4 9.00e-4 RDM 2.70e-4 7.01 4.60e-4 29.03 7.85e-4 3.38e-3 DiffPh yCon 1.62e-4 5.15 4.80e-4 18.72 6.63e-4 1.99e-3 AdaptDiffuser 2.28e-4 4.65 1.76e-5 26.23 8.64e-4 5.49e-3 Ours 9.80 ±5.6 e-5 5.01 ±0.6 8.90 ±3.1 e-6 14.90 ±0.8 3.49 ±2.6 e-4 8.90 ±0.9 e-4 F igure 7. Pareto frontier of tar get loss and energy cost J across dif ferent datasets of our method and two SO T A baselines DecisionDiffuser and DiffPh yCon. The closer the data point is to the bottom left, the better the performance. System Description. The Swing Equation system models the rotational dynamics of synchronous generators in a po wer network. W e utilize the New England 10-generator 39-bus system. The state space consists of the rotor angles and frequencies of the generators, resulting in a high-dimensional nonlinear system. T ask Setup. Follo wing the experimental design in Baggio et al. ( 2021 ), the control task simulates a recov ery scenario following a line fault. The process is illustrated in Figure 8 . The objective is to compute an optimal control sequence that dri ves the generators from a disturbed, un-synchronized state back to the steady-state operation (zero de viation). The trajectories are sampled with 18 state v ariables and 9 control inputs over a horizon of 32 timesteps . This setup incorporates realistic physical parameters and disturbances, serving as a rigorous test for controlling coupled nonlinear dynamics. G. Supplementary Experiments G.1. Comparison against MPC T able 6. Comparison of SEDC (Ours) and Model Predicti ve Control (MPC) across three control tasks. Results show tar get loss (MSE), control cost (J), and inference time in seconds. W e implemented the MPC that uses a neural netw ork architecture with residual connections to learn system dynamics from data, then solves finite-horizon optimization problems at each timestep using the gradient of the summation of target loss and control energy , which iterativ ely refines the sampling distribution tow ard optimal control sequences. The control horizons of Kuramoto,Bur gers and IP are 15, 10 and 128. Model Kuramoto Burgers IP T arget loss J T ime(s) T arget loss J Time(s) T arget loss J Time(s) MPC 9.10e-03 0.34 ∼ 50 1.89e-01 0.001 ∼ 30 4.33e-04 1.01e-03 > 1000 Ours 8.90e-06 14.9 ∼ 1.5 9.80e-05 5.01 ∼ 2.5 3.49e-04 8.90e-04 ∼ 0.5 W e additionally compare SEDC with data-dri ven Model Predicti ve Control (MPC). W e implement MPC in a data-dri ven 15 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems F igure 8. Illustration of the power grid swing dynamics control task. The system simulates a recovery scenario follo wing a line fault, where the objectiv e is to compute an optimal control sequence that driv es the generators from a disturbed, un-synchronized state back to steady-state operation (zero deviation). Sev eral component of this figure are adapted from Baggio et al. ( 2021 ). way , where we train an MLP for the forward model. Results in T able 6 sho w MPC achie ves higher tar get losses across all tasks, likely due to error accumulation. MPC also has significantly longer inference times (e.g. ¿1000 vs. 0.5) that increase with control horizon. SEDC directly maps initial/target states to complete control trajectories, av oiding compounding errors and reducing computation time. G.2. V alidation on High-Dimensional 2D PDE Control: Jellyfish Locomotion T o address the critical question of our method’ s scalability and effecti veness on truly high-dimensional control problems, we conducted additional experiments on a challenging 2D PDE control benchmark: the locomotion of a jellyfish. This task represents a state-of-the-art challenge in data-driv en control of physical systems, in volving complex fluid-solid interactions gov erned by the 2D incompressible Navier -Stokes equations ( W ei et al. , 2024b ). Unlike the systems in the main text, this benchmark provides a testbed with a significantly higher state-space dimension, allo wing for a rigorous e valuation of SEDC’ s scalability . Experimental Setup The objecti ve is to control the opening angle of the jellyfish’ s wings to achie ve a target locomotion pattern. The system state is a high-dimensional PDE field representing the fluid velocity and pressure, while the control input is a scalar time series representing the wing angle. • State Representation: Each state at a given timestep is represented by a 3 × 32 × 32 tensor , resulting in a state dimension of 3,072 . This is a substantial increase in complexity compared to the 1D systems. • Dataset: W e generated a dataset of 20,000 control trajectories for training, follo wing the standard procedure for this benchmark. Overall P erf ormance Comparison W e first ev aluated SEDC against strong diffusion-based baselines using the full training dataset. The results, shown in T able 7 , assess control accuracy (T arget Loss), energy ef ficiency (Energy), and computational cost (T raining and Inference Time). The results demonstrate that SEDC achiev es the best control accuracy (lo west T arget Loss) among all methods, confirming that its architectural advantages for sample-efficient learning translate effecti vely to high-dimensional PDE systems. Furthermore, its computational cost remains on par with the fastest baselines, highlighting its practicality . 16 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems T able 7. Performance comparison on the 2D Jellyfish Locomotion control task (100% training data). SEDC achieves the best control accuracy with a competiti ve computational profile. Model T arget Loss ( ↓ ) Energy ( ↓ ) T rain Time (hrs) Inference Time (s) DecisionDiffuser 1.74e-4 ± 7.4e-5 2.016 ± 0.08 3.0 6.0 AdaptDiffuser 1.77e-4 ± 1.7e-5 2.001 ± 0.71 3.0 6.0 DiffPh yCon 1.77e-4 ± 5.4e-5 2.157 ± 0.21 4.0 8.0 SEDC (Ours) 1.70e-4 ± 1.3e-5 2.015 ± 0.43 3.0 6.5 Sample Efficiency Analysis A key claim of our work is superior sample efficienc y . T o specifically v alidate this on a high-dimensional task, we compared the performance of SEDC against the strongest baseline (DecisionDiffuser) when trained on only 20% of the av ailable data versus the full dataset. T able 8. Sample efficiency comparison on the Jellyfish task. Results show the final T arget Loss. SEDC trained on only 20% of the data outperforms the baseline trained on 100% of the data. Model 100% T raining Data 20% T raining Data DecisionDiffuser 1.74e-4 4.52e-4 SEDC (Ours) 1.70e-4 1.75e-4 As shown in T able 8 , SEDC exhibits remarkable sample efficienc y . When trained on just 20% of the data, its performance is statistically on par with the baseline trained on the full dataset (1.75e-4 vs 1.74e-4). In contrast, the baseline’ s performance degrades significantly when data is limited. This comprehensive v alidation on a high-dimensional PDE benchmark strongly supports our paper’ s central claim: SEDC provides a scalable and highly sample-efficient framew ork for the control of complex nonlinear systems. G.3. System Applicability and Non-In vertible Dynamics Details In Section 5.5 , we demonstrated SEDC’ s robustness on non-inv ertible systems. Here we provide the specific dynamics configuration. Rank-Deficient Linear System Setup. W e constructed a linear system with a rank-deficient control matrix to simulate control redundancy (infinite control solutions): ˙ y = Ay + Bu , A = 0 1 − 1 − 0 . 5 , B = 0 0 1 1 (10) where y ∈ R 2 and u ∈ R 2 . The matrix B has rank 1, meaning the controls u 1 and u 2 are coupled ( u 1 + u 2 affects the system), making indi vidual control recov ery mathematically impossible. Despite this, as reported in the main te xt, SEDC successfully learns a v alid control law (implicitly learning an equal distrib ution or minimum norm solution), whereas the joint diffusion baseline f ails to conv erge to a consistent state-control pair . Additional Experiment: Non-Affine MIMO System. W e also verified performance on a nonlinear non-affine system: ˙ x 1 = − x 1 + x 2 , ˙ x 2 = sin( x 1 ) − 0 . 5 x 2 + u 2 1 − u 2 2 . SEDC similarly achie ved a T arget Loss of 5.0e-2 compared to 8.1e-2 for the baseline, further confirming robustness. G.4. The effectiveness of dynamical lear ning T o in vestigate the ef fectiv eness of dynamical learning, we compared the consistency between action sequences and diffusion- sampled state trajectories in models with and without DSD. While both approaches can sample state trajectories from diffusion samples, they differ in action generation: SEDC uses in verse dynamics prediction, whereas w/o DSD obtains control signals directly from diffusion samples by simultaneously dif fusing states and control inputs. W e test both models using identical start-target conditions and visualize the state induced from the generated inputs and the state sampled from the diffusion model, along with the dif ference (error) between the above two states in Figure 9 . W e can observe that SEDC’ s action-induced state trajectories sho wed significantly higher consistency with sampled trajectories compared to w/o DSD , demonstrating that DSD using in verse dynamics achiev es more accurate learning of control-state dynamical relationships. 17 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems F igure 9. Comparison of State T rajectory Consistency between SEDC and w/o DSD Models. The heatmaps show induced states (left), sampled states (middle), and their absolute differences (right) for both SEDC (top) and w/o DSD (bottom) approaches under identical start-target conditions. G.5. Sufficiency of the 2nd-Order DMD Architectur e T o address whether our 2nd-order DMD approximation is sufficient for systems with richer nonlinearities, we conducted a targeted e xperiment on synthetic 2D systems with controlled nonlinear terms. W e designed three systems: one purely linear , one with a quadratic term, and one with a cubic term. W e compared our full DMD model against a single-UNet baseline and a linear-only ablation of our model. T able 9. Performance (T arget Loss) on synthetic systems with v arying orders of nonlinearity . Our 2nd-order DMD model is sufficient to effecti vely control the 3rd-order system. System Dynamics Single-UNet DMD (Ours) Linear -Only 1st-Order (Linear) 1.05e-6 8.68e-7 1.54e-6 2nd-Order (Quadratic) 6.63e-6 5.20e-6 2.50e-4 3rd-Order (Cubic) 7.00e-5 6.43e-5 5.80e-3 As shown in T able 9 , our DMD model achieves the lo west error on the 3rd-order system, demonstrating its suf ficiency . The performance of the Linear-Only model is nearly 90x worse, confirming that the nonlinear branch ( O 2 ) is not redundant and is critical for capturing the system’ s dynamics. This principled, sample-efficient design proves robust ev en for complex systems beyond its e xplicit T aylor-e xpansion moti v ation. G.6. Robustness to Obser vation Noise T o ev aluate the robustness of our method, a critical factor for real-w orld applicability , we conducted new e xperiments to validate SEDC’ s performance when trained on data corrupted by observation noise. This setup simulates practical scenarios where state measurements are imperfect. Experimental Setup W e added zero-mean Gaussian noise with varying standard de viations ( σ ) to the state observations in the training data for both the Kuramoto and Burgers systems. W e then retrained our model and the strongest baselines from scratch on this noisy data and ev aluated their control accuracy on a clean, noise-free test set. Results The results, summarized in T able 10 , sho w that SEDC consistently achiev es superior control accurac y across all noise lev els. Notably , on the Burgers system with medium noise ( σ = 0 . 01 ), SEDC’ s target loss of 2.25e-4 is 1.8x better than AdaptDiffuser’ s and 3.9x better than DiffPhyCon’ s. This superior robustness stems from our ke y architectural innov ations. DMD’ s decomposition helps capture the core system dynamics resiliently , while DSD’ s focus on learning a smoother state-only distrib ution pre vents overfitting to noise, a common issue when modeling complex joint state-control distrib utions. 18 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems T able 10. Performance (T arget Loss) comparison on noisy training data. Energy cost is shown in parentheses. SEDC demonstrates consistently higher accuracy under noisy conditions. System Noise ( σ ) SEDC (Ours) AdaptDiffuser DiffPhyCon Kuramoto 0 8.90e-6 (14.90) 1.76e-5 (26.23) 4.80e-4 (18.72) 0.001 1.21e-5 (17.19) 8.00e-4 (16.24) 3.95e-3 (11.50) 0.01 5.61e-4 (10.40) 1.75e-3 (3.37) 3.24e-3 (17.58) 0.1 3.14e-3 (0.42) 3.96e-3 (0.98) 3.14e-3 (2.22) Burgers 0 9.80e-5 (5.01) 2.28e-4 (4.65) 1.62e-4 (5.15) 0.001 1.86e-4 (5.01) 2.81e-4 (4.73) 6.05e-4 (5.11) 0.01 2.25e-4 (4.40) 3.98e-4 (4.21) 8.69e-4 (4.58) 0.1 6.97e-4 (4.25) 1.22e-3 (3.75) 2.89e-3 (3.13) H. V isualization W e present some visualization results of our method and best-performing baselines under three systems. The goal is to make the end state (T=10 for Burgers and T=15 for Kuramoto) close to the target state. As can be seen, SEDC’ s final state always coincides with the target state. In contrast, the baselines showed inferior results, as some mismatch with the target state can be observed. I. Limitations In our paper , we assume full state observability throughout. W e hope to extend our framework to partial-observable or partial-controllable circumstances in the future. Considering extending this work to stochastic control settings, our present work focuses on deterministic non-linear systems where SEDC demonstrates significant advantages in sample efficiency and control accuracy . Although we believe the diffusion-based nature of our approach provides a conceptual foundation that could potentially be adapted to stochastic settings, this would require substantial theoretical modifications to our framework components (DSD, DMD, and GSF). Extending to stochastic control would in volve addressing additional comple xities in modeling state transition probabilities and optimizing over distributions rather than deterministic trajectories. This remains an open research question we are interested in exploring. While our current framework generates open-loop trajectories, its computational efficiency and ability to produce high- quality plans make it an ideal candidate for integration into a closed-loop MPC scheme. Such an integration would le verage SEDC as a powerful trajectory planner at each step, enabling robust adaptation to unexpected disturbances by replanning in real-time. This synergy between global planning and reactiv e feedback represents a promising avenue for future research in robust, sample-ef ficient, data-driv en control. 19 Sample-Efficient Diffusion-based Control of Complex Ph ysics Systems (a) Burgers (b) Kuramoto (c) In verse Pendulum F igure 10. Comparison of different methods on Bur gers, Kuramoto and In verse Pendulum systems 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment