Enhancing Human-Like Responses in Large Language Models
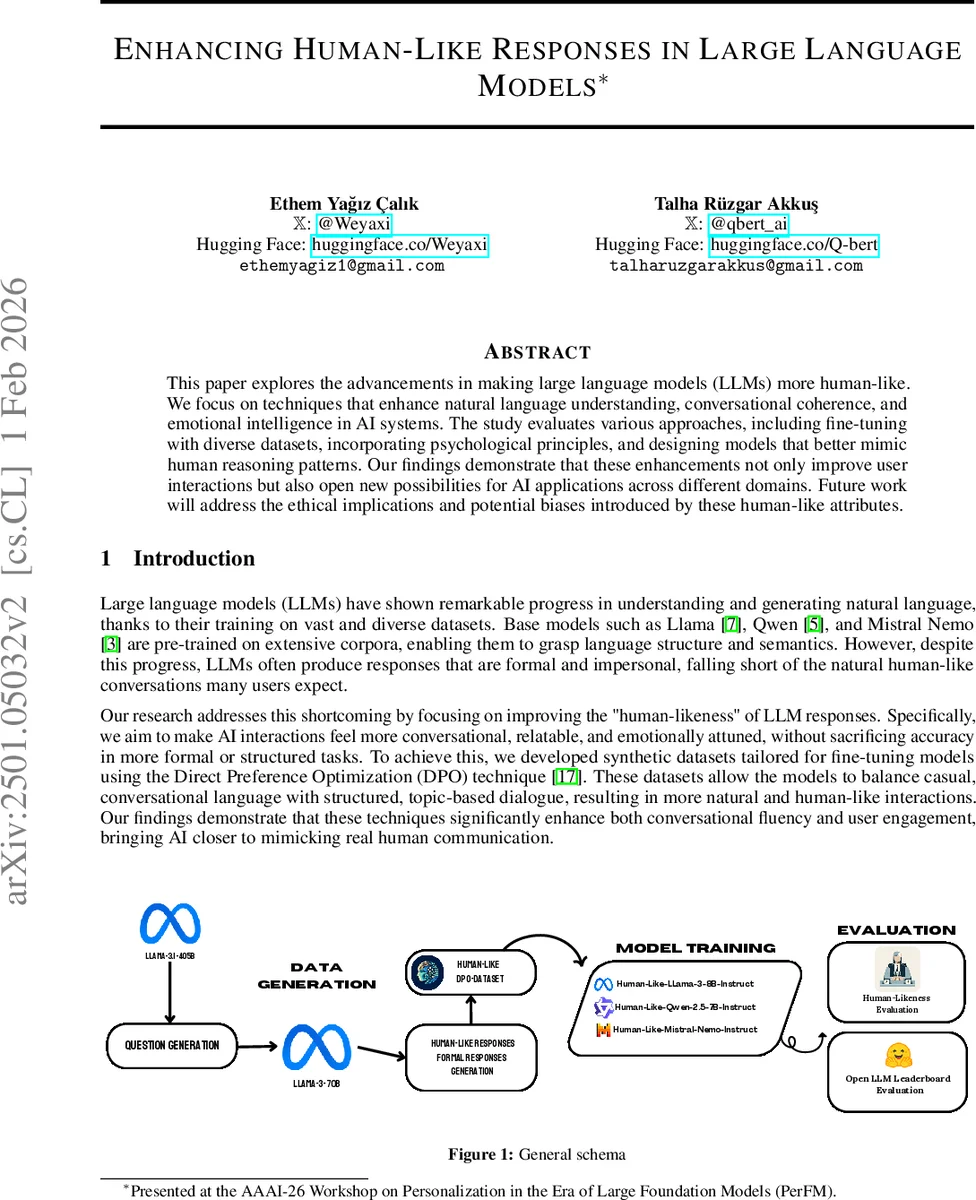
This paper explores the advancements in making large language models (LLMs) more human-like. We focus on techniques that enhance natural language understanding, conversational coherence, and emotional intelligence in AI systems. The study evaluates various approaches, including fine-tuning with diverse datasets, incorporating psychological principles, and designing models that better mimic human reasoning patterns. Our findings demonstrate that these enhancements not only improve user interactions but also open new possibilities for AI applications across different domains. Future work will address the ethical implications and potential biases introduced by these human-like attributes.
💡 Research Summary
The paper “Enhancing Human‑Like Responses in Large Language Models” investigates how to make large language models (LLMs) generate dialogue that feels more natural, engaging, and emotionally attuned, thereby narrowing the gap between AI‑generated text and human conversation. The authors begin by noting that while modern LLMs such as Llama 3, Qwen 2.5, and Mistral‑Nemo demonstrate impressive linguistic competence, their outputs often remain formal, impersonal, and riddled with self‑referential boilerplate (“I am just a language model”). To address this shortcoming, the study proposes a two‑stage pipeline: (1) creation of a synthetic “Human‑Like‑DPO‑Dataset” that explicitly distinguishes between “human‑like” and “formal” responses, and (2) fine‑tuning of base models using a combination of Low‑Rank Adaptation (LoRA) and Direct Preference Optimization (DPO).
Dataset construction leverages the powerful Llama 3 70B and 405B models in a Self‑Instruct‑style process. First, a set of 10 884 question prompts is generated, split between conversational prompts (personal experiences, hypothetical scenarios) and general‑knowledge prompts. For each question, two system prompts are applied: one that encourages a warm, informal, context‑rich answer, and another that pushes the model toward a concise, structured, impersonal reply. The resulting pairs are labeled “chosen” (human‑like) and “rejected” (formal). Topic analysis using an Atlas Nomic Map reveals natural clustering into 256 categories such as travel, sports, technology, health, and culture, ensuring broad coverage.
Training employs LoRA to adapt only a small low‑rank sub‑space of each model’s weights (r = 8, α = 4, dropout = 0.05), thereby preserving the bulk of the pretrained knowledge and mitigating catastrophic forgetting. DPO then supplies a reward signal that favors the “chosen” responses while penalizing the “rejected” ones, effectively teaching the model to prefer conversational style during inference. The fine‑tuning is carried out on two NVIDIA A100 80 GB GPUs using the Axolotl framework, with hyperparameters such as a learning rate of 2e‑4, a single epoch, and a batch size of 8. Three instruction‑tuned base models—Llama‑3‑8B‑Instruct, Qwen‑2.5‑7B‑Instruct, and Mistral‑Nemo‑Instruct—are each fine‑tuned, producing “Human‑Like‑Llama‑3‑8B‑Instruct,” “Human‑Like‑Qwen‑2.5‑7B‑Instruct,” and “Human‑Like‑Mistral‑Nemo‑Instruct.”
Evaluation consists of two complementary parts. The first is a human‑likeness assessment using an anonymous voting interface built with Gradio and hosted on Hugging Face Spaces. Participants (a mix of high‑school students and adults, native and non‑native English speakers) were shown side‑by‑side responses from a fine‑tuned model and its original counterpart for 500 generated questions, yielding 2 000 votes. The fine‑tuned models were overwhelmingly preferred: 89.6% for the Llama variant, 89.5% for the Qwen variant, and 79.6% for the Mistral variant. Qualitative inspection highlighted that the fine‑tuned models avoided mechanical self‑disclaimers and produced more fluid, context‑aware replies.
The second evaluation uses the Open LLM Leaderboard to measure any trade‑off in standard benchmark performance. Across IFEval, BBH, Math Level 5, GPQA, MuSR, and MMLU‑Pro, the fine‑tuned models show only modest changes. IFEval scores drop by roughly 1 point for Llama and 0.2 points for Qwen, while other benchmarks remain stable or improve slightly (e.g., Mistral’s Math Level 5 score rises by 3 points). When IFEval is excluded, average performance differences shrink further, indicating that the human‑likeness enhancements do not substantially degrade the models’ general capabilities.
The discussion acknowledges several limitations: the synthetic nature of the dataset may not capture the full diversity of real user queries; the demographic skew of annotators could introduce bias; and increasing emotional expressiveness raises ethical concerns about deception, manipulation, and the propagation of bias. The authors suggest future work should incorporate real‑world interaction logs, expand multilingual and cross‑cultural evaluations, and develop transparency mechanisms that make a model’s affective stance explicit to users.
In conclusion, the paper demonstrates that a carefully engineered combination of LoRA‑based parameter-efficient fine‑tuning and DPO‑driven preference learning can substantially improve the perceived human‑likeness of LLM responses while preserving, or even slightly enhancing, benchmark performance. This approach offers a practical pathway for deploying more natural, engaging conversational agents in applications ranging from virtual assistants to educational chatbots, provided that ethical safeguards are put in place.
Comments & Academic Discussion
Loading comments...
Leave a Comment