CLAMP: Contrastive Learning for 3D Multi-View Action-Conditioned Robotic Manipulation Pretraining
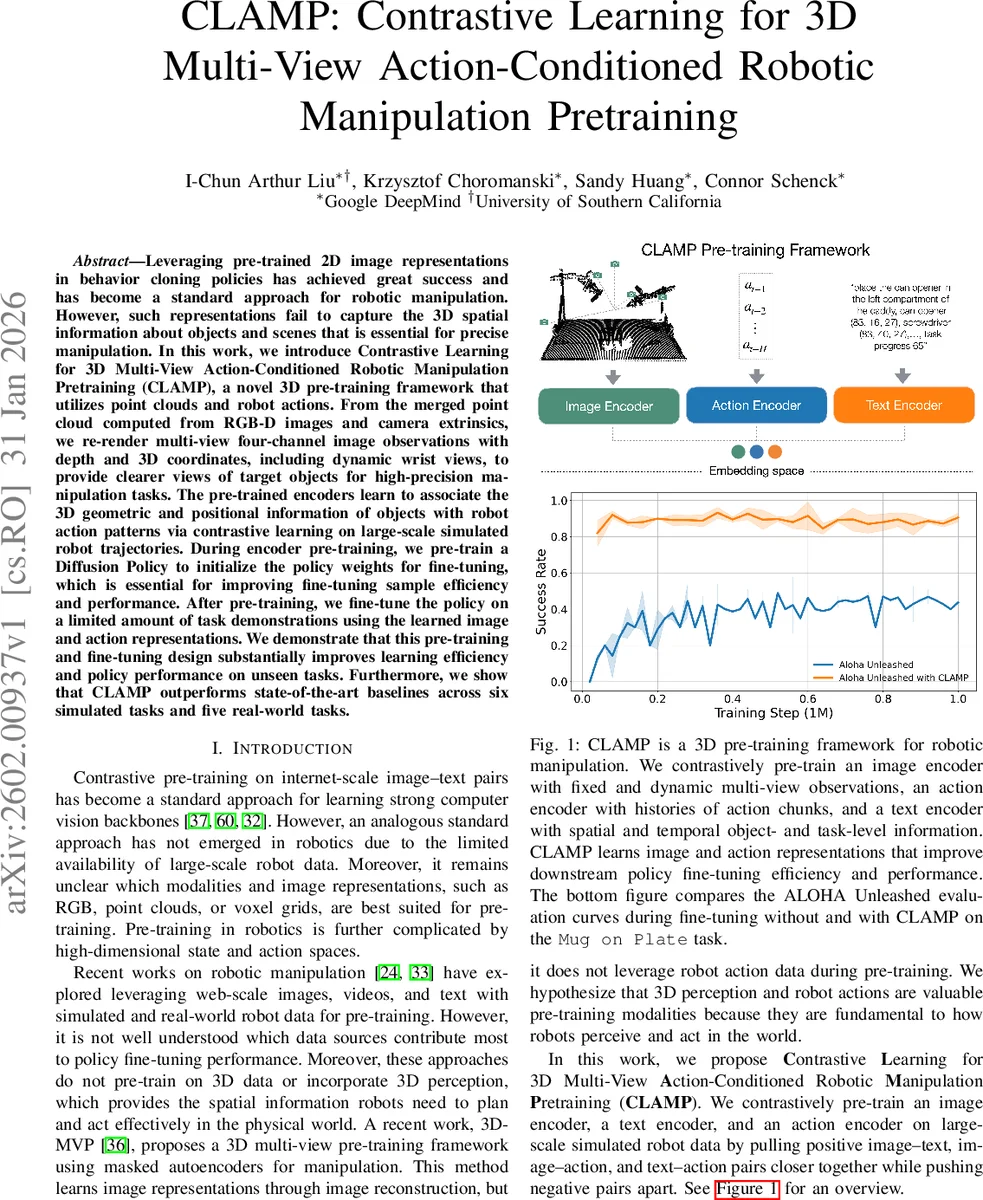
Leveraging pre-trained 2D image representations in behavior cloning policies has achieved great success and has become a standard approach for robotic manipulation. However, such representations fail to capture the 3D spatial information about objects and scenes that is essential for precise manipulation. In this work, we introduce Contrastive Learning for 3D Multi-View Action-Conditioned Robotic Manipulation Pretraining (CLAMP), a novel 3D pre-training framework that utilizes point clouds and robot actions. From the merged point cloud computed from RGB-D images and camera extrinsics, we re-render multi-view four-channel image observations with depth and 3D coordinates, including dynamic wrist views, to provide clearer views of target objects for high-precision manipulation tasks. The pre-trained encoders learn to associate the 3D geometric and positional information of objects with robot action patterns via contrastive learning on large-scale simulated robot trajectories. During encoder pre-training, we pre-train a Diffusion Policy to initialize the policy weights for fine-tuning, which is essential for improving fine-tuning sample efficiency and performance. After pre-training, we fine-tune the policy on a limited amount of task demonstrations using the learned image and action representations. We demonstrate that this pre-training and fine-tuning design substantially improves learning efficiency and policy performance on unseen tasks. Furthermore, we show that CLAMP outperforms state-of-the-art baselines across six simulated tasks and five real-world tasks.
💡 Research Summary
The paper “CLAMP: Contrastive Learning for 3D Multi-View Action-Conditioned Robotic Manipulation Pretraining” introduces a novel framework designed to learn rich 3D spatial and action-oriented representations for robotic manipulation tasks. Recognizing the limitations of standard 2D image-based pre-training, which lacks crucial 3D geometric understanding, CLAMP leverages point clouds and robot action data from large-scale simulated trajectories.
The core methodology consists of two synergistic pre-training stages. First, a contrastive encoder pre-training stage learns aligned representations across three modalities: 3D scene observations, text descriptions, and robot action histories. The system generates a scene point cloud from RGB-D images, then re-renders it into multi-view, four-channel images (containing depth and XYZ world coordinates) from five key viewpoints: three fixed (overhead, front-left, back-right) and two dynamic views attached to the robot’s wrists. These dynamic wrist views are crucial for reducing occlusion during manipulation. A Vision Transformer (ViT) image encoder processes these views, enhanced with STRING relative positional encoding that uses the 3D coordinates to relate image patches based on their physical proximity. A Transformer-based action encoder processes a history of past robot actions, and a CLIP text encoder processes privileged simulator text containing object names, positions, and task progress. These three encoders are trained jointly using a modified SigLIP contrastive loss that pulls together embeddings from matched image-text, image-action, and text-action pairs.
Concurrently, the second stage involves pre-training the downstream visuomotor policy, specifically a Diffusion Policy. The frozen embeddings from the CLAMP encoders (taken before final pooling) are concatenated with task-specific RGB features (from ResNet-50) and proprioceptive data. This combined conditioning signal is fed into a Transformer-based Diffusion Policy, which is pre-trained on the same large-scale simulation data to predict noise for action denoising. This policy pre-training provides a critical weight initialization for the final fine-tuning step.
For deployment on a target task, the pre-trained CLAMP encoders remain frozen, while the Diffusion Policy is fine-tuned on a limited set of expert demonstrations for that specific task. Extensive experiments across six simulated and five real-world tasks (using the ALOHA Unleashed benchmark) demonstrate that CLAMP significantly improves sample efficiency and final success rates compared to state-of-the-art baselines like 3D-MVP, RVT, and DP3. Ablation studies confirm the vital importance of both dynamic wrist views (for high-precision tasks) and the concurrent policy pre-training (for fine-tuning efficiency). The work establishes that effective robotic manipulation pre-training must unify 3D geometric perception, action-conditioned learning, and direct policy initialization within a single framework.
Comments & Academic Discussion
Loading comments...
Leave a Comment